缓存失效及解决方案
这几天在网易云课堂上看到几个关于Java开发比较好的视频,推荐给大家
Java高级开发工程师公开课
这篇文章也是对其中一门课程的个人总结。
何谓缓存失效
对于一个并发量大的项目,缓存是必须的,如果没有缓存,所有的请求将直击数据库,数据库很有可能抗不住,所以建立缓存势在不行。
那么建立缓存后就有可能出现缓存失效的问题:
- 大面积的缓存key失效
- 热点key失效
类似12306网站,因为用户频繁的查询车次信息,假设所有车次信息都建立对应的缓存,那么如果所有车次建立缓存的时间一样,失效时间也一样,那么在缓存失效的这一刻,也就意味着所有车次的缓存都失效。通常当缓存失效的时候我们需要重构缓存,这时所有的车次都将面临重构缓存,即出现问题1的场景,此时数据库就将面临大规模的访问。
针对以上这种情况,可以将建立缓存的时间进行分布,使得缓存失效时间尽量不同,从而避免大面积的缓存失效。
下面讨论第二个问题。
春节马上快到了,抢票回家的时刻也快来临了。通常我们会事先选择好一个车次然后疯狂更新车次信息,假设此时这般车的缓存刚好失效,可以想象会有多大的请求会直怼数据库。
使用缓存
下面是通常的缓存使用方法,无非就是先查缓存,再查DB,重构缓存。
@Service
public class TicketService {
@Autowired
TicketRepository ticketRepository;
@Autowired
RedisUtil redis;
public Integer findTicketByName(String name){
//1.先从缓存获取
String value = redis.get(name);
if(value != null){
System.out.println(Thread.currentThread().getId()+"从缓存获取:"+value);
return Integer.valueOf(value);
}
//2.查询数据库
Ticket ticket = ticketRepository.findByName(name);
System.out.println(Thread.currentThread().getId()+"从数据库获取:"+ticket.getTickets());
//3.放入缓存
redis.set(name,ticket.getTickets(),120);
return 0;
}
}
接下来我们模拟1000个请求同时访问这个service
@RunWith(SpringRunner.class)
@SpringBootTest
public class RedisQpsApplicationTests {
//车次
public static final String NAME = "G2386";
//请求数量
public static final Integer THREAD_NUM = 1000;
//倒计时
private CountDownLatch countDownLatch = new CountDownLatch(THREAD_NUM);
@Autowired
private TicketService tocketService;
@Autowired
private TicketService2 tocketService2;
@Autowired
private TicketService3 tocketService3;
@Test
public void contextLoads() {
long startTime = System.currentTimeMillis();
System.out.println("开始测试");
Thread[] threads = new Thread[THREAD_NUM];
for(int i=0;i<THREAD_NUM;i++){
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
try {
//所有开启的线程在此等待,倒计时结束后统一开始请求,模拟并发量
countDownLatch.await();
//查找票数
tocketService.findTicketByName(NAME);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
threads[i].start();
//倒计时
countDownLatch.countDown();
}
for(Thread thread:threads){
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("结束测试===="+(System.currentTimeMillis()-startTime));
}
}
经过测试可以很简单地发现所有的访问都直接去查询数据库而获得数据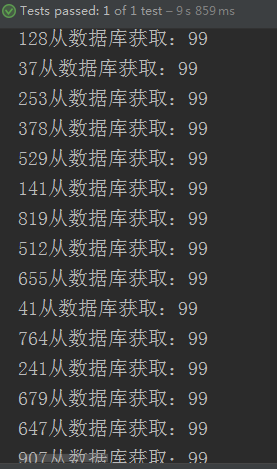
那么明明我们已经使用了缓存为什么还会出现这种情况呢?只要稍微了解多线程的知识就不难知道为什么会出现这个问题。
我们的思路是第一个访问的人在没有缓存的情况下,去重构缓存,那么剩下的访问再去查缓存。上述的情况就是因为在第一人去查DB的时候,剩下的访问也去查DB了。
那么根据我们的思路无非就是想让剩下的访问阻塞等待嘛,于是有了我们下面经过改良的方案。
加锁重构缓存
@Service
public class TicketService2 {
@Autowired
TicketRepository ticketRepository;
Lock lock = new ReentrantLock();
@Autowired
RedisUtil redis;
public Integer findTicketByName(String name){
//1.先从缓存获取
String value = redis.get(name);
if(value != null){
System.out.println(Thread.currentThread().getId()+"从缓存获取:"+value);
return Integer.valueOf(value);
}
//第一人获取锁,去查DB,剩余人二次查询缓存
long s = System.currentTimeMillis();
lock.lock();
try {
System.out.println(Thread.currentThread().getId()+"加锁阻塞时长"+(System.currentTimeMillis()-s));
value = redis.get(name);
if(value != null){
System.out.println(Thread.currentThread().getId()+"从缓存获取:"+value);
return Integer.valueOf(value);
}
//2.查询数据库
Ticket ticket = ticketRepository.findByName(name);
System.out.println(Thread.currentThread().getId()+"从数据库获取:"+ticket.getTickets());
//3.放入缓存
redis.set(name,ticket.getTickets(),120);
}finally {
lock.unlock();
}
return 0;
}
}
通过单元测试可以看到确实符合我们的预期。第一个去重构缓存,剩余的查缓存。这里要注意记得在锁内对缓存进行二次查询。
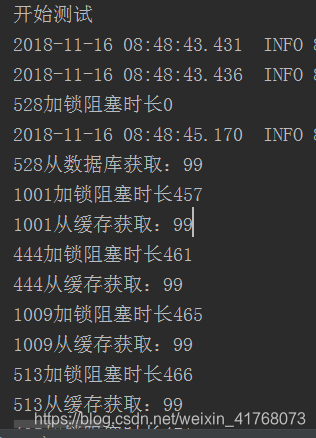
这种解决方案怎么说呢,有好有坏。
- 优点:简单通用,使用范围广
- 缺点:阻塞访问,用户体验差,锁粒度粗
关于锁的粒度:12306的车次是非常多的,假设有两个车次的缓存都失效了,假设使用上述方案,第一个车次的去查DB,第二个车次的也要去查DB重构缓存啊,凭什么我要等你第一个车次的查完,我再去查。这就是锁粒度粗导致的,一把锁面对所有车次的查询,当别车次拥有了锁,那你只好乖乖等待了。
缓存降级
缓存降级简单的理解就是降低预期期望。比如双十一的时候很多人因为支付不成功而提示的稍后再试,这些都属于缓存降级,缓存降级也有好几种方案,具体要结合实际业务场景,可以返回固定的信息,返回备份缓存的值(并不一定是真实值),返回提示等待…
对锁的粒度进行优化结合缓存降级,对于每一个车次如果已经在重构缓存,那么同车次的访问进行缓存降级,不同车次的访问则也可以重构缓存。大体思路如下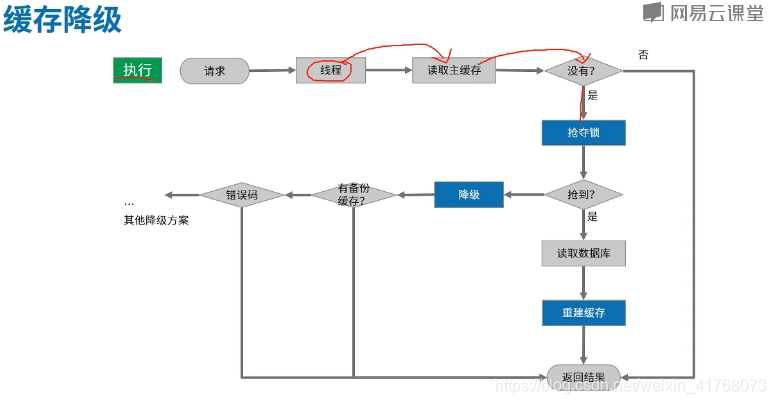
下面使用ConcurrentHashMap对每个车次的锁进行标记
@Service
public class TicketService3 {
@Autowired
TicketRepository ticketRepository;
//标记该车次是否有人在重构缓存
ConcurrentHashMap<String,String> mapLock = new ConcurrentHashMap<>();
@Autowired
RedisUtil redis;
public Integer findTicketByName(String name){
//1.先从缓存获取
String value = redis.get(name);
if(value != null){
System.out.println(Thread.currentThread().getId()+"从缓存获取:"+value);
return Integer.valueOf(value);
}
boolean lock = false;
try {
/* putIfAbsent 如果不存在,添加键值,返回null,存在则返回存在的值 */
lock = mapLock.putIfAbsent(name,"true") == null ; //1000个请求,只有一个拿到锁,剩余人缓存降级
if(lock){ //拿到锁
//2.查询数据库
Ticket ticket = ticketRepository.findByName(name);
System.out.println(Thread.currentThread().getId()+"从数据库获取:"+ticket.getTickets());
//3.放入缓存
redis.set(name,ticket.getTickets(),120);
//4.有备份缓存 双写缓存 不设时间
}else{
//方案1 返回固定值
System.out.println(Thread.currentThread().getId()+"固定值获取:0");
return 0;
//方案2 备份缓存
//方案3 提示用户重试
}
}finally {
if(lock){//有锁才释放
mapLock.remove(name);//释放锁
}
}
return 0;
}
}详细代码已经见码云
总结
缓存失效的两种情况:
1.大面积缓存key失效,所有车次查询都依赖数据库,可对缓存的时间进行随机分布
2.热点key失效,某个key的海量请求直击数据库
缓存的实现原理:先查缓存,再查DB,塞进缓存
1.缓存失效:缓存有有效时间,当有效时间到达,大量并发线程会直击数据库。
解决方案:1.Lock 第一人查DB,做缓存,剩余人二次查询缓存
优点:简单有效,适用范围广
缺点:阻塞其他线程,用户体验差
锁颗粒度大
优化:细粒度锁实现
2.缓存降级:1)做备份缓存,不设置事件 2)返回固定值
主备都无数据,一人去查DB,剩余人返回固定值
主无数据,备有数据,一人查DB,剩余人查备份
优点:灵活多变
缺点:备份缓存数据可能不一致