全文分两部分,第一部分讲车牌识别及普通验证码这一类识别的普通方法,第二部分讲对类似QQ验证码,Gmail验证码这一类变态验证码的识别方法和思路。
一、车牌/验证码识别的普通方法
车牌、验证码识别的普通方法为:
(1) 将图片灰度化与二值化
(2) 去噪,然后切割成一个一个的字符
(3) 提取每一个字符的特征,生成特征矢量或特征矩阵
(4) 分类与学习。将特征矢量或特征矩阵与样本库进行比对,挑选出相似的那类样本,将这类样本的值作为输出结果。
下面借着代码,描述一下上述过程。因为更新SVN Server,我以前以bdb储存的代码访问不了,因此部分代码是用Reflector反编译过来的,望见谅。
(1) 图片的灰度化与二值化
这样做的目的是将图片的每一个象素变成0或者255,以便以计算。同时,也可以去除部分噪音。
图片的灰度化与二值化的前提是bmp图片,如果不是,则需要首先转换为bmp图片。
用代码说话,我的将图片灰度化的代码(算法是在网上搜到的):
1 protected static Color Gray(Color c)
2 {
3 int rgb = Convert.ToInt32((double) (((0.3 * c.R) + (0.59 * c.G)) + (0.11 * c.B)));
4 return Color.FromArgb(rgb, rgb, rgb);
5 }
6
通过将图片灰度化,每一个象素就变成了一个0-255的灰度值。
然后是将灰度值二值化为 0 或255。一般的处理方法是设定一个区间,比如,[a,b],将[a,b]之间的灰度全部变成255,其它的变成0。这里我采用的是网上广为流行的自适应二值化算法。
1 public static void Binarizate(Bitmap map)
2 {
3 int tv = ComputeThresholdValue(map);
4 int x = map.Width;
5 int y = map.Height;
6 for (int i = 0; i < x; i++)
7 {
8 for (int j = 0; j < y; j++)
9 {
10 if (map.GetPixel(i, j).R >= tv)
11 {
12 map.SetPixel(i, j, Color.FromArgb(0xff, 0xff, 0xff));
13 }
14 else
15 {
16 map.SetPixel(i, j, Color.FromArgb(0, 0, 0));
17 }
18 }
19 }
20 }
21
22 private static int ComputeThresholdValue(Bitmap img)
23 {
24 int i;
25 int k;
26 double csum;
27 int thresholdValue = 1;
28 int[] ihist = new int[0x100];
29 for (i = 0; i < 0x100; i++)
30 {
31 ihist[i] = 0;
32 }
33 int gmin = 0xff;
34 int gmax = 0;
35 for (i = 1; i < (img.Width - 1); i++)
36 {
37 for (int j = 1; j < (img.Height - 1); j++)
38 {
39 int cn = img.GetPixel(i, j).R;
40 ihist[cn]++;
41 if (cn > gmax)
42 {
43 gmax = cn;
44 }
45 if (cn < gmin)
46 {
47 gmin = cn;
48 }
49 }
50 }
51 double sum = csum = 0.0;
52 int n = 0;
53 for (k = 0; k <= 0xff; k++)
54 {
55 sum += k * ihist[k];
56 n += ihist[k];
57 }
58 if (n == 0)
59 {
60 return 60;
61 }
62 double fmax = -1.0;
63 int n1 = 0;
64 for (k = 0; k < 0xff; k++)
65 {
66 n1 += ihist[k];
67 if (n1 != 0)
68 {
69 int n2 = n - n1;
70 if (n2 == 0)
71 {
72 return thresholdValue;
73 }
74 csum += k * ihist[k];
75 double m1 = csum / ((double) n1);
76 double m2 = (sum - csum) / ((double) n2);
77 double sb = ((n1 * n2) * (m1 - m2)) * (m1 - m2);
78 if (sb > fmax)
79 {
80 fmax = sb;
81 thresholdValue = k;
82 }
83 }
84 }
85 return thresholdValue;
86 }
87
88
灰度化与二值化之前的图片:
![]()
灰度化与二值化之后的图片:
![]()
注:对于车牌识别来说,这个算法还不错。对于验证码识别,可能需要针对特定的网站设计特殊的二值化算法,以过滤杂色。
(2) 去噪,然后切割成一个一个的字符
上面这张车牌切割是比较简单的,从左到右扫描一下,碰见空大的,咔嚓一刀,就解决了。但有一些车牌,比如这张:
![]()
简单的扫描就解决不了。因此需要一个比较通用的去噪和切割算法。这里我采用的是比较朴素的方法:
将上面的图片看成是一个平面。将图片向水平方向投影,这样有字的地方的投影值就高,没字的地方投影得到的值就低。这样会得到一根曲线,像一个又一个山头。下面是我手画示意图:
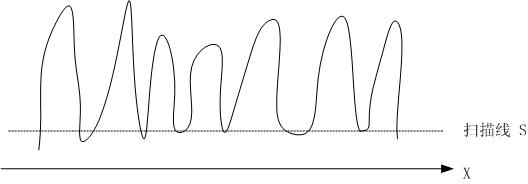
然后,用一根扫描线(上图中的S)从下向上扫描。这个扫描线会与图中曲线存在交点,这些交点会将山头分割成一个又一个区域。车牌图片一般是7个字符,因此,当扫描线将山头分割成七个区域时停止。然后根据这七个区域向水平线的投影的坐标就可以将图片中的七个字符分割出来。
但是,现实是复杂的。比如,“川”字,它的水平投影是三个山头。按上面这种扫描方法会将它切开。因此,对于上面的切割,需要加上约束条件:每个山头有一个中心线,山头与山头的中心线的距离必需在某一个值之上,否则,则需要将这两个山头进行合并。加上这个约束之后,便可以有效的切割了。
以上是水平投影。然后还需要做垂直投影与切割。这里的垂直投影与切割就一个山头,因此好处理一些。
切割结果如下:
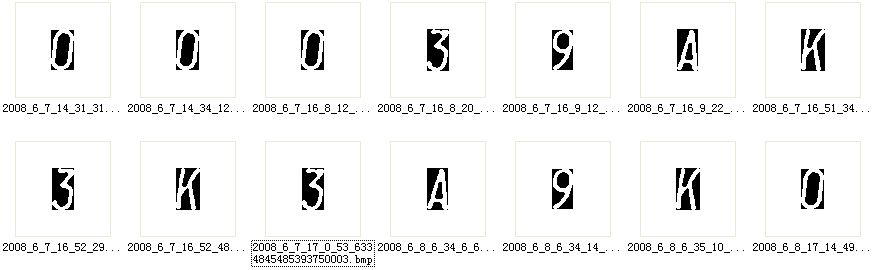
水平投影及切割代码:
1 public static IList<Bitmap> Split(Bitmap map, int count)
2 {
3 if (count <= 0)
4 {
5 throw new ArgumentOutOfRangeException("Count 必须大于0.");
6 }
7 IList<Bitmap> resultList = new List<Bitmap>();
8 int x = map.Width;
9 int y = map.Height;
10 int splitBitmapMinWidth = 4;
11 int[] xNormal = new int[x];
12 for (int i = 0; i < x; i++)
13 {
14 for (int j = 0; j < y; j++)
15 {
16 if (map.GetPixel(i, j).R == CharGrayValue)
17 {
18 xNormal[i]++;
19 }
20 }
21 }
22 Pair pair = new Pair();
23 for (int i = 0; i < y; i++)
24 {
25 IList<Pair> pairList = new List<Pair>(count + 1);
26 for (int j = 0; j < x; j++)
27 {
28 if (xNormal[j] >= i)
29 {
30 if ((j == (x - 1)) && (pair.Status == PairStatus.Start))
31 {
32 pair.End = j;
33 pair.Status = PairStatus.End;
34 if ((pair.End - pair.Start) >= splitBitmapMinWidth)
35 {
36 pairList.Add(pair);
37 }
38 pair = new Pair();
39 }
40 else if (pair.Status == PairStatus.JustCreated)
41 {
42 pair.Start = j;
43 pair.Status = PairStatus.Start;
44 }
45 }
46 else if (pair.Status == PairStatus.Start)
47 {
48 pair.End = j;
49 pair.Status = PairStatus.End;
50 if ((pair.End - pair.Start) >= splitBitmapMinWidth)
51 {
52 pairList.Add(pair);
53 }
54 pair = new Pair();
55 }
56 if (pairList.Count > count)
57 {
58 break;
59 }
60 }
61 if (pairList.Count == count)
62 {
63 foreach (Pair p in pairList)
64 {
65 if (p.Width < (map.Width / 10))
66 {
67 int width = (map.Width / 10) - p.Width;
68 p.Start = Math.Max(0, p.Start - (width / 2));
69 p.End = Math.Min((int) (p.End + (width / 2)), (int) (map.Width - 1));
70 }
71 }
72 foreach (Pair p in pairList)
73 {
74 int newMapWidth = (p.End - p.Start) + 1;
75 Bitmap newMap = new Bitmap(newMapWidth, y);
76 for (int ni = p.Start; ni <= p.End; ni++)
77 {
78 for (int nj = 0; nj < y; nj++)
79 {
80 newMap.SetPixel(ni - p.Start, nj, map.GetPixel(ni, nj));
81 }
82 }
83 resultList.Add(newMap);
84 }
85 return resultList;
86 }
87 }
88 return resultList;
89 }
90
代码中的 Pair,代表扫描线与曲线的一对交点:
1 private class Pair
2 {
3 public Pair();
4 public int CharPixelCount { get; set; }
5 public int CharPixelXDensity { get; }
6 public int End { get; set; }
7 public int Start { get; set; }
8 public BitmapConverter.PairStatus Status { get; set; }
9 public int Width { get; }
10 }
11
PairStatus代表Pair的状态。具体哪个状态是什么意义,我已经忘了。
1 private enum PairStatus
2 {
3 JustCreated,
4 Start,
5 End
6 }
7
以上这一段代码写的很辛苦,因为要处理很多特殊情况。那个PairStatus 也是为处理特殊情况引进的。
垂直投影与切割的代码简单一些,不贴了,见附后的dll的BitmapConverter.TrimHeight方法。
以上用到的是朴素的去噪与切割方法。有些图片,尤其是验证码图片,需要特别的去噪处理。具体操作方法就是,打开CxImage(http://www.codeproject.com/KB/graphics/cximage.aspx),或者Paint.Net,用上面的那些图片处理方法,看看能否有效去噪。记住自己的操作步骤,然后翻他们的源代码,将其中的算法提取出来。还有什么细化啊,滤波啊,这些处理可以提高图片的质量。具体可参考ITK的代码或图像处理书籍。
(3) 提取每一个字符的特征,生成特征矢量或特征矩阵
将切割出来的字符,分割成一个一个的小块,比如3×3,5×5,或3×5,或10×8,然后统计一下每小块的值为255的像素数量,这样得到一个矩阵M,或者将这个矩阵简化为矢量V。
通过以上3步,就可以将一个车牌中的字符数值化为矢量了。
(1)-(3)步具体的代码流程如下:
1

2 BitmapConverter.ToGrayBmp(bitmap); // 图片灰度化
3 BitmapConverter.Binarizate(bitmap); // 图片二值化
4 IList<Bitmap> mapList = BitmapConverter.Split(bitmap, DefaultCharsCount); // 水平投影然后切割
5 Bitmap map0 = BitmapConverter.TrimHeight(mapList[0], DefaultHeightTrimThresholdValue); // 垂直投影然后切割
6 ImageSpliter spliter = new ImageSpliter(map0);
7 spliter.WidthSplitCount = DefaultWidthSplitCount;
8 spliter.HeightSplitCount = DefaultHeightSplitCount;
9 spliter.Init();
10
然后,通过spliter.ValueList就可以获得 Bitmap map0 的矢量表示。
(4) 分类
分类的原理很简单。用(Vij,Ci)表示一个样本。其中,Vij是样本图片经过上面过程数值化后的矢量。Ci是人肉眼识别这张图片,给出的结果。Vij表明,有多个样本,它们的数值化后的矢量不同,但是它们的结果都是Ci。假设待识别的图片矢量化后,得到的矢量是V’。
直观上,我们会有这样一个思路,就是这张待识别的图片,最像样本库中的某张图片,那么我们就将它当作那张图片,将它识别为样本库中那张图片事先指定的字符。
在我们眼睛里,判断一张图片和另一张图片是否相似很简单,但对于电脑来说,就很难判断了。我们前面已经将图片数值化为一个个维度一样的矢量,电脑是怎样判断一个矢量与另一个矢量相似的呢?
这里需要计算一个矢量与另一个矢量间的距离。这个距离越短,则认为这两个矢量越相似。
我用 SampleVector<T> 来代表矢量:
1 public class SampleVector<T>
2 {
3 protected T[] Vector { get; set; }
4 public Int32 Dimension { get { return Vector.Length; } }
5 ……
6 }
7
T代表数据类型,可以为Int32,也可以为Double等更精确的类型。
测量距离的公共接口为:IMetric
1 public interface IMetric<TElement,TReturn>
2 {
3 TReturn Compute(SampleVector<TElement> v1, SampleVector<TElement> v2);
4 }
5
常用的是MinkowskiMetric。
1 /// <summary>
2 /// Minkowski 测度。
3 /// </summary>
4 public class MinkowskiMetric<TElement> : IMetric<TElement, Double>
5 {
6 public Int32 Scale { get; private set; }
7 public MinkowskiMetric(Int32 scale)
8 { Scale = scale; }
9
10 public Double Compute(SampleVector<TElement> v1, SampleVector<TElement> v2)
11 {
12 if (v1 == null || v2 == null) throw new ArgumentNullException();
13 if (v1.Dimension != v2.Dimension) throw new ArgumentException("v1 和 v2 的维度不等.");
14 Double result = 0;
15 for (int i = 0; i < v1.Dimension; i++)
16 {
17 result += Math.Pow(Math.Abs(Convert.ToDouble(v1[i]) - Convert.ToDouble(v2[i])), Scale);
18 }
19 return Math.Pow(result, 1.0 / Scale);
20 }
21 }
22
23 MetricFactory 负责生产各种维度的MinkowskiMetric:
24
25 public class MetricFactory
26 {
27 public static IMetric<TElement, Double> CreateMinkowskiMetric<TElement>(Int32 scale)
28 {
29 return new MinkowskiMetric<TElement>(scale);
30 }
31
32 public static IMetric<TElement, Double> CreateEuclideanMetric<TElement>()
33 {
34 return CreateMinkowskiMetric<TElement>(2);
35 }
36 }
37
MinkowskiMetric是普遍使用的测度。但不一定是最有效的量。因为它对于矢量V中的每一个点都一视同仁。而在图像识别中,每一个点的重要性却并不一样,例如,Q和O的识别,特征在下半部分,下半部分的权重应该大于上半部分。对于这些易混淆的字符,需要设计特殊的测量方法。在车牌识别中,其它易混淆的有D和0,0和O,I和1。Minkowski Metric识别这些字符,效果很差。因此,当碰到这些字符时,需要进行特别的处理。由于当时时间紧,我就只用了Minkowski Metric。
我的代码中,只实现了哪个最近,就选哪个。更好的方案是用K近邻分类器或神经网络分类器。K近邻的原理是,找出和待识别的图片(矢量)距离最近的K个样本,然后让这K个样本使用某种规则计算(投票),这个新图片属于哪个类别(C);神经网络则将测量的过程和投票判决的过程参数化,使它可以随着样本的增加而改变,是这样的一种学习机。有兴趣的可以去看《模式分类》一书的第三章和第四章。
二、 变态字符的识别
有些字符变形很严重,有的字符连在一起互相交叉,有的字符被掩盖在一堆噪音海之中。对这类字符的识别需要用上特殊的手段。
下面介绍几种几个经典的处理方法,这些方法都是被证实对某些问题很有效的方法:
(1) 切线距离 (Tangent Distance):可用于处理字符的各种变形,OCR的核心技术之一。
(2) 霍夫变换(Hough Transform):对噪音极其不敏感,常用于从图片中提取各种形状。图像识别中最基本的方法之一。
(3) 形状上下文(Shape Context):将特征高维化,对形变不很敏感,对噪音也不很敏感。新世纪出现的新方法。
因为这几种方法我均未编码实现过,因此只简单介绍下原理及主要应用场景。
(1) 切线距离
前面介绍了MinkowskiMetric。这里我们看看下面这张图:一个正写的1与一个歪着的1.
![]()
用MinkowskiMetric计算的话,两者的MinkowskiMetric很大。
然而,在图像识别中,形状形变是常事。理论上,为了更好地识别,我们需要对每一种形变都采足够的样,这样一来,会发现样本数几乎无穷无尽,计算量越来越大。
怎么办呢?那就是通过计算切线距离,来代替直接距离。切线距离比较抽象,我们将问题简化为二维空间,以便以理解。
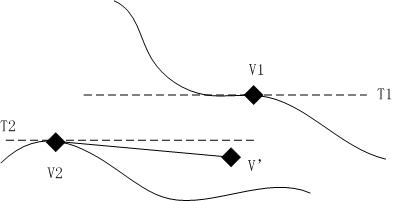
上图有两条曲线。分别是两个字符经过某一形变后所产生的轨迹。V1和V2是2个样本。V’是待识别图片。如果用样本之间的直接距离,比较哪个样本离V’最近,就将V’当作哪一类,这样的话,就要把V’分给V1了。理论上,如果我们无限取样的话,下面那一条曲线上的某个样本离V’最近,V’应该归类为V2。不过,无限取样不现实,于是就引出了切线距离:在样本V1,V2处做切线,然后计算V’离这两条切线的距离,哪个最近就算哪一类。这样一来,每一个样本,就可以代表它附近的一个样本区域,不需要海量的样本,也能有效的计算不同形状间的相似性。
深入了解切线距离,可参考这篇文章。Transformation invariance in pattern recognition – tangent distance and tangent propagation (http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.32.9482)这篇文章。
(2) 霍夫变换
霍夫变换出自1962年的一篇专利。它的原理非常简单:就是坐标变换的问题。
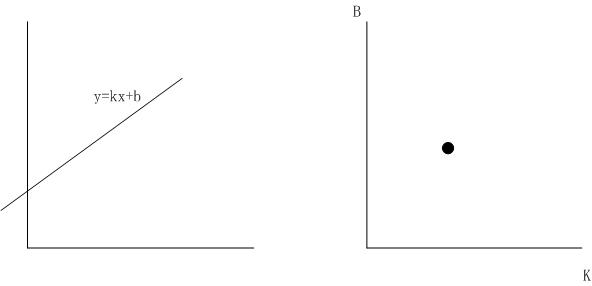
如,上图中左图中的直线,对应着有图中k-b坐标系中的一个点。通过坐标变换,可以将直线的识别转换为点的识别。点的识别就比直线识别简单的多。为了避免无限大无限小问题,常用的是如下变换公式:
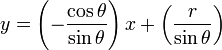
下面这张图是wikipedia上一张霍夫变换的示意图。左图中的两条直线变换后正对应着右图中的两个亮点。
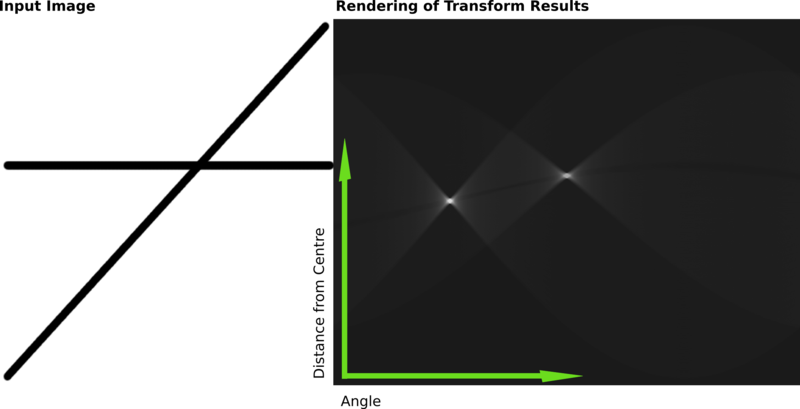
通过霍夫变换原理可以看出,它的抗干扰性极强极强:如果直线不是连续的,是断断续续的,变换之后仍然是一个点,只是这个点的强度要低一些。如果一个直线被一个矩形遮盖住了,同样不影响识别。因为这个特征,它的应用性非常广泛。
对于直线,圆这样容易被参数化的图像,霍夫变换是最擅长处理的。对于一般的曲线,可通过广义霍夫变换进行处理。感兴趣的可以google之,全是数学公式,看的人头疼。
(3) 形状上下文
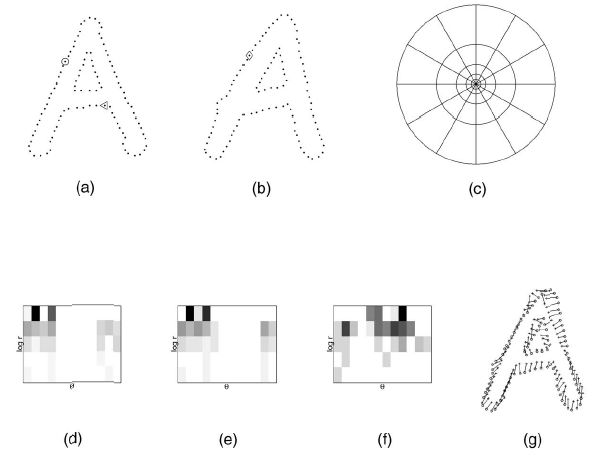
图像中的像素点不是孤立的,每个像素点,处于一个形状背景之下,因此,在提取特征时,需要将像素点的背景也作为该像素点的特征提取出来,数值化。
形状上下文(Shape Context,形状背景)就是这样一种方法:假定要提取像素点O的特征,采用上图(c)中的坐标系,以O点作为坐标系的圆心。这个坐标系将O点的上下左右切割成了12×5=60小块,然后统计这60小块之内的像素的特征,将其数值化为12×5的矩阵,上图中的(d),(e),(f)便分别是三个像素点的Shape Context数值化后的结果。如此一来,提取的每一个点的特征便包括了形状特征,加以计算,威力甚大。来看看Shape Context的威力:
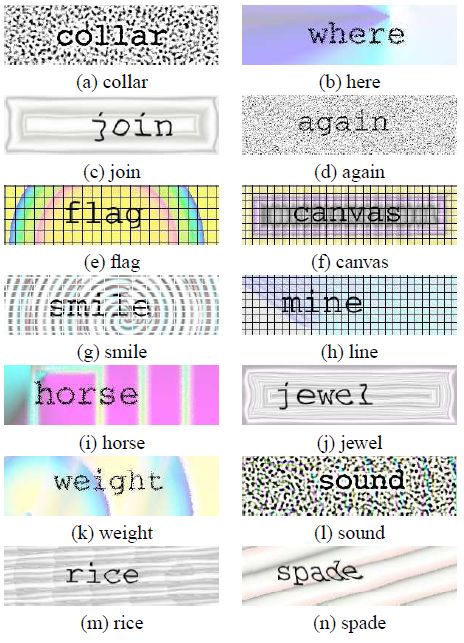
上图中的验证码,对Shape Context来说只是小Case。

看看这几张图。嘿嘿,硬是给识别出来了。
Shape Context是新出现的方法,其威力到底有多大目前还未见底。这篇文章是Shape context的必读文章:Shape Matching and Object Recognitiom using shape contexts(http://www.cs.berkeley.edu/~malik/papers/BMP-shape.pdf)。最后那两张验证码识别图出自Greg Mori,Jitendra Malik的《Recognizing Objects in Adversarial Clutter:Breaking a Visual CAPTCHA》一文。
===========================================================
附件:第一部分的代码(vcr.zip). 3个dll文件,反编译看的很清晰。源代码反而没dll好看,我就不放了。其中,Orc.Generics.dll是几个泛型类,Orc.ImageProcess.Common.dll 对图像进行处理和分割,Orc.PatternRecognition.dll 是识别部分。
这三个dll可以直接用在车牌识别上。用于车牌识别,对易混淆的那几个字符识别率较差,需要补充几个分类器,现有分类器识别结果为D ,O,0,I,1等时,用新分类器识别。用于识别验证码需要改一改。
有个asp.net的调用例子可实现在线上传图片识别,因为其中包含多张车牌信息,不方便放出来。我贴部分代码出来:
Global.asax:
void Application_Start(object sender, EventArgs e)
{
log4net.Config.XmlConfigurator.Configure();
Orc.Spider.Vcr.DaoConfig.Init();
Classifier.Update(Server);
}
DaoConfig:
using System;
using Castle.ActiveRecord;
using Castle.ActiveRecord.Framework;
using Castle.ActiveRecord.Framework.Config;
namespace Orc.Spider.Vcr
{
public static class DaoConfig
{
private static Boolean Inited = false;
public static void Init()
{
if (!Inited)
{
Inited = true;
XmlConfigurationSource con = new XmlConfigurationSource(AppDomain.CurrentDomain.BaseDirectory + @"\ActiveRecord.config");
ActiveRecordStarter.Initialize
(con,
typeof(TrainPattern)
);
}
}
}
}
TrainPattern:// TrainPattern存在数据库里
[ActiveRecord("TrainPattern")]
public class TrainPattern : ActiveRecordBase<TrainPattern>
{
[PrimaryKey(PrimaryKeyType.Native, "Id")]
public Int32 Id { get; set; }
[Property("FileName")]
public String FileName { get; set; }
[Property("Category")]
public String Category { get; set; }
public static TrainPattern[] FindAll()
{
String hql = "from TrainPattern ORDER BY Category DESC";
SimpleQuery<TrainPattern> query = new SimpleQuery<TrainPattern>(hql);
return query.Execute();
}
}
Classifier://主要调用封装在这里
public class Classifier
{
protected static Orc.PatternRecognition.KnnClassifier<Int32> DefaultChineseCharClassifier;
protected static Orc.PatternRecognition.KnnClassifier<Int32> DefaultEnglishAndNumberCharClassifier;
protected static Orc.PatternRecognition.KnnClassifier<Int32> DefaultNumberCharClassifier;
public static Int32 DefaultWidthSplitCount = 3;
public static Int32 DefaultHeightSplitCount = 3;
public static Int32 DefaultCharsCount = 7; // 一张图片中包含的字符个数
public static Int32 DefaultHeightTrimThresholdValue = 4;
public static ILog Log = LogManager.GetLogger("Vcr");
public static void Update(HttpServerUtility server)
{
TrainPattern[] TPList = TrainPattern.FindAll();
if (TPList == null) return;
DefaultChineseCharClassifier = new KnnClassifier<Int32>(DefaultWidthSplitCount * DefaultHeightSplitCount);
DefaultEnglishAndNumberCharClassifier = new KnnClassifier<Int32>(DefaultWidthSplitCount * DefaultHeightSplitCount);
DefaultNumberCharClassifier = new KnnClassifier<Int32>(DefaultWidthSplitCount * DefaultHeightSplitCount);
foreach (TrainPattern tp in TPList)
{
String path = server.MapPath(".") + "/VcrImage/" + tp.FileName;
using (Bitmap bitmap = new Bitmap(path))
{
TrainPattern<Int32> tpv = CreateTainPatternVector(bitmap, tp.Category.Substring(0, 1));
Char c = tpv.Category[0];
if (c >= '0' && c <= '9')
{
DefaultEnglishAndNumberCharClassifier.AddTrainPattern(tpv);
DefaultNumberCharClassifier.AddTrainPattern(tpv);
}
else if (c >= 'a' && c <= 'z')
DefaultEnglishAndNumberCharClassifier.AddTrainPattern(tpv);
else if (c >= 'A' && c <= 'Z')
DefaultEnglishAndNumberCharClassifier.AddTrainPattern(tpv);
else
DefaultChineseCharClassifier.AddTrainPattern(tpv);
}
}
}
protected static TrainPattern<Int32> CreateTainPatternVector(Bitmap bitmap, String categoryChars)
{
TrainPattern<int> tpv = new TrainPattern<int>( CreateSampleVector(bitmap), categoryChars);
tpv.XNormalSample = CreateXNormalSampleVector(bitmap);
tpv.YNormalSample = CreateYNormalSampleVector(bitmap);
return tpv;
}
protected static SampleVector<Int32> CreateSampleVector(Bitmap bitmap)
{
ImageSpliter spliter = new ImageSpliter(bitmap);
spliter.WidthSplitCount = DefaultWidthSplitCount;
spliter.HeightSplitCount = DefaultHeightSplitCount;
spliter.Init();
return new SampleVector<Int32>(spliter.ValueList);
}
protected static SampleVector<Int32> CreateYNormalSampleVector(Bitmap bitmap)
{
ImageSpliter spliter = new ImageSpliter(bitmap);
spliter.WidthSplitCount = 1;
spliter.HeightSplitCount = DefaultHeightSplitCount;
spliter.Init();
return new SampleVector<Int32>(spliter.ValueList);
}
protected static SampleVector<Int32> CreateXNormalSampleVector(Bitmap bitmap)
{
ImageSpliter spliter = new ImageSpliter(bitmap);
spliter.WidthSplitCount = DefaultWidthSplitCount;
spliter.HeightSplitCount = 1;
spliter.Init();
return new SampleVector<Int32>(spliter.ValueList);
}
public static String Classify(String imageFileName)
{
Log.Debug("识别文件:" + imageFileName);
String result = String.Empty;
if (DefaultChineseCharClassifier == null || DefaultEnglishAndNumberCharClassifier == null) throw new Exception("识别器未初始化.");
using (Bitmap bitmap = new Bitmap(imageFileName))
{
BitmapConverter.ToGrayBmp(bitmap);
BitmapConverter.Binarizate(bitmap);
IList<Bitmap> mapList = BitmapConverter.Split(bitmap, DefaultCharsCount);
if (mapList.Count == DefaultCharsCount)
{
Bitmap map0 = BitmapConverter.TrimHeight(mapList[0], DefaultHeightTrimThresholdValue);
TrainPattern<Int32> tp0 = CreateTainPatternVector(map0, " ");
String sv0Result = DefaultChineseCharClassifier.Classify(tp0);
Console.WriteLine("识别样本: " + tp0.Sample.ToString());
result += sv0Result;
for (int i = 1; i < mapList.Count; i++)
{
Bitmap mapi = BitmapConverter.TrimHeight(mapList[i], DefaultHeightTrimThresholdValue);
TrainPattern<Int32> tpi = CreateTainPatternVector(mapi, " ");
Console.WriteLine("识别样本: " + tpi.Sample.ToString());
if (i < mapList.Count - 3)
result += DefaultEnglishAndNumberCharClassifier.Classify(tpi);
else
result += DefaultNumberCharClassifier.Classify(tpi);
}
}
return result;
}
}
/*
public static IList<Tuple<Double,String>> ComputeDistance(String imageFileName)
{
if (DefaultChineseCharClassifier == null) throw new Exception("识别器未初始化.");
using (Bitmap bitmap = new Bitmap(imageFileName))
{
ImageSpliter spliter = new ImageSpliter(bitmap);
spliter.WidthSplitCount = DefaultWidthSplitCount;
spliter.HeightSplitCount = DefaultHeightSplitCount;
spliter.Init();
SampleVector<Int32> sv = new SampleVector<Int32>(spliter.ValueList);
return DefaultChineseCharClassifier.ComputeDistance(sv);
}
}*/
}