【问题】
MySQL中,LIMIT的性能随着N的不断增大会急剧下降,但是分页这种设计又是随处可见的。
在上一篇(https://www.cnblogs.com/bruceChan0018/p/15191693.html)通过实际场景分析了为什么LIMIT N当N很大时会消耗系统的性能,并在最后一部分延伸说明了一个优化LIMIT的思路。但是按照其中的说法,要求还是苛刻的,即id不仅要自增,还必须连续。如果系统的数据删除了,id不连续,那不是没法用这个办法了?
------------------------------------------------------------------------------------
【环境】
先试用上一篇中的SQL脚本创建好表和基础数据,然后我们使用一个存储过程,批量插入到100万条数据。
#存储过程插入批量数据
#注意这个过程中最好将autocommit设置为OFF(set autocommit = 0;),关闭自动提交,执行完后再恢复为ON(set autocommit = 1;)。
DROP PROCEDURE IF EXISTS `batch_insert_goods`; DELIMITER $$ CREATE PROCEDURE batch_insert_goods() BEGIN DECLARE increase_id INTEGER; #上一次插入了27调数据,这里从id=28开始插入 set increase_id=28; START TRANSACTION; WHILE increase_id<1000000 DO INSERT INTO `goods_order`(`id`, `goods_name`, `goods_type_id`, `price`) VALUES (increase_id, '123', '1', ROUND(RAND()*10)); set increase_id=increase_id+1; END WHILE; COMMIT; END$$ DELIMITER ; #调用存储过程 CALL batch_insert_goods();
如果不想这么麻烦使用存储过程的话,还有一个比较简单的做法。
将id设为自增,而后利用表里的数据进行insert into...select...的思路,这个办法也可以在短时间内制造大量数据:
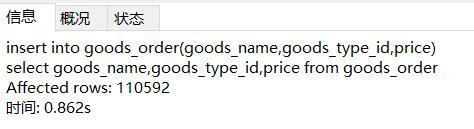
------------------------------------------------------------------------------------
【分析】
select * from goods_order order by goods_name,id limit 0,10 select * from goods_order order by goods_name,id limit 1000000,10
这两句在服务器中,第一条是服务器处理10条数据,返回排序好的10条;第二条是服务器要处理10010条数据的排序,最后返回末尾的10条数据,两者的消耗相差好几个数量级。无论MySQL优化器内部怎么优化,第二条的性能肯定都是远远不及第一条。
[注意:此时goods_name未加索引]

按照之前的思路,我们此时应该缩小排序范围,让其在有限的数据中进行排序。如:
select * from goods_order limit where id>=1000004 order by goods_name,id limit 0,10;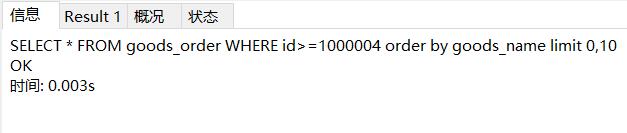
如果id自增且连续,或者我们在这里已经能够准确获取到id的临界值,那么构造出来的查询语句性能当然会比我们直接排序10010条数据好很多,当数据量很大且查询服务高频时,这样的优化方向就是我们需要的。但是有两个问题摆在面前:
1.如果id不连续怎么办,这个where中的条件数据该怎么界定?
2.如果不是按照id排序,而是其它的字段,比如一个特殊的金额,日期,字符串时我们又该怎么处理呢?
------------------------------------------------------------------------------------
【缩小范围】
关于缩小范围,常见的做法是子语句来确定范围。无论是直接定位到查找的临界值,还是通过索引覆盖的字段来排序定位到指定的临界值,最终查找外层内容时,这个堆的大小一定是很小的了。
假如我们要对这些数据按照日期进行排序(日期靠后的id也会更大),且日期在表中不重复,那么一个可行的方案就是:
在分页时不允许随机挑选页面码,只能从上到下或者从下到上去翻页。此时在前端请求数据时,可以将上一页的页码以及最大最小id一并传入,后端做判断,可以找到这个where条件对应的id,而limit后只需要设置单页条数即可。
SELECT * FROM goods_order WHERE id>${last_max_id} ORDER BY create_time LIMIT 10;
这其实是一种思路,不管我们是用什么手段,只要我们缩小了范围,那么这种查询效率必定大大提高。
再如:我们知道上下边界值以及对应的页码,那么我们可以在一个合理的范围内,对这批数据进行排序:
SELECT * FROM goods_order WHERE id between ${given_min_id} and ${given_max_id} ORDER BY create_time LIMIT 10;
具体的场景中可以灵活使用这种手段。
------------------------------------------------------------------------------------
【延迟关联】
思路是利用索引在子语句中找到我们需要的关联字段的值,在外层通过关联字段找到我们需要的数据。
[注意:此时goods_name已经添加了索引]
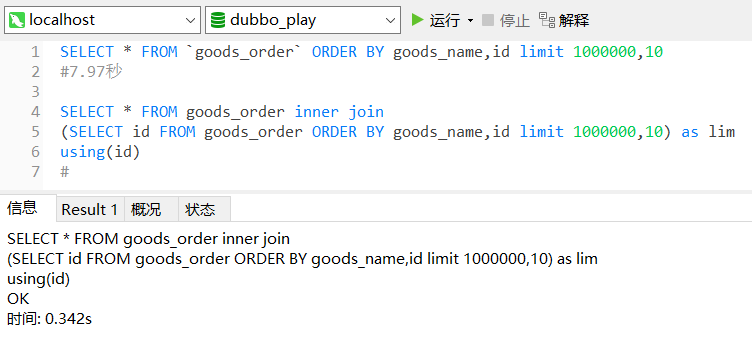
要注意的是,子语句中的查找字段排序字段都需要添加索引。另外外层如果使用where进行范围确定的话,有些时候查询速度会特别慢,这个问题我们放到以后分析。
------------------------------------------------------------------------------------
【终极杀器】
如果我们能够从源头限制住使用这种查询的场景,那么问题自然也就不存在了。比如只允许用户查询固定多少页的数据:
这是淘宝的PC端页面,当你搜索商品时,下面的翻页最大数总是100页。我去看了下京东,也是这样。
而在当当的电子书系列中,我看到了陈列的商品是下拉时才获取最新一页的数据,这就符合我们上述的只让用户查询后一页的数据,所以你无限翻下去性能上也没多大变化。
所以,在进行业务沟通时,我们需要将这种技术上的考虑跟产品进行充分地沟通,并在此基础上设计一个合理的业务方案。