1. PaddleHub 提供的深度学习简化流程
选择Baidu的预训练模型 -> 迁移学习 -> 超参搜索 -> 多端部署

2. 深度学习为何能够代替机器学习
2.1. 深度学习改变了AI应用的研发模式
深度学习改变了很多领域算法的实现模式。在深度学习兴起之前,很多领域建模的思路是投入大量精力做特征工程,将专家对某个领域的“人工理解”沉淀成特征表达,然后使用简单模型完成任务(如分类或回归)。而在数据充足的情况下,深度学习模型可以实现端到端的学习,即不需要专门做特征工程,将原始的特征输入模型中,模型可同时完成特征提取和分类任务。
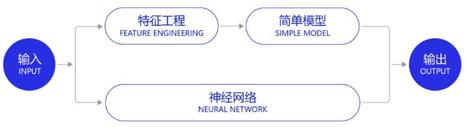
以计算机视觉任务为例,特征工程是诸多图像科学家基于人类对视觉理论的理解,设计出来的一系列提取特征的计算步骤,典型如SIFT特征。在2010年之前的计算机视觉领域,人们普遍使用SIFT一类特征+SVM一类的简单浅层模型完成建模任务。
SIFT特征由David Lowe在1999年提出,在2004年加以完善。SIFT特征是基于物体上的一些局部外观的兴趣点而与影像的大小和旋转无关。对于光线、噪声、微视角改变的容忍度也相当高。基于这些特性,它们是高度显著而且相对容易撷取,在母数庞大的特征数据库中,很容易辨识物体而且鲜有误认。使用SIFT特征描述对于部分物体遮蔽的侦测率也相当高,甚至只需要3个以上的SIFT物体特征就足以计算出位置与方位。在现今的电脑硬件速度下和小型的特征数据库条件下,辨识速度可接近即时运算。SIFT特征的信息量大,适合在海量数据库中快速准确匹配。
2.2. 实现了深度学习框架标准化
在此之前,不同流派的机器学习算法理论和实现均不同,导致每个算法均要独立实现,如随机森林和支撑向量机(SVM)。但在深度学习框架下,不同模型的算法结构有较大的通用性,如常用于计算机视觉的卷积神经网络模型(CNN)和常用于自然语言处理的长期短期记忆模型(LSTM),都可以分为组网模块、梯度下降的优化模块和预测模块等。这使得抽象出统一的框架成为了可能,并大大降低了编写建模代码的成本。一些相对通用的模块,如网络基础算子的实现、各种优化算法等都可以由框架实现。建模者只需要关注数据处理,配置组网的方式,以及用少量代码串起训练和预测的流程即可。
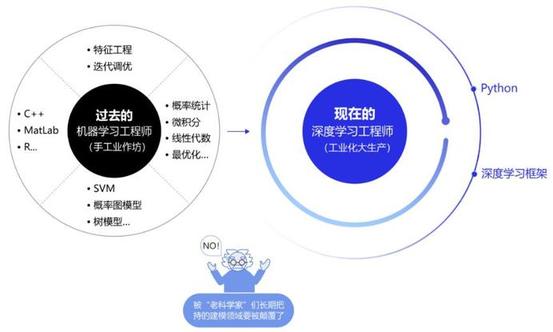
在深度学习框架出现之前,机器学习工程师处于手工业作坊生产的时代。为了完成建模,工程师需要储备大量数学知识,并为特征工程工作积累大量行业知识。每个模型是极其个性化的,建模者如同手工业者一样,将自己的积累形成模型的“个性化签名”。而今,“深度学习工程师”进入了工业化大生产时代。只要掌握深度学习必要但少量的理论知识,掌握Python编程,即可在深度学习框架上实现非常有效的模型,甚至与该领域最领先的模型不相上下。建模这个被“老科学家”们长期把持的建模领域面临着颠覆,也是新入行者的机遇。
3. 领域模型
├── audio
│ └── TTS
├── image
│ ├── classification
│ ├── face_detection
│ ├── gan, 生成式对抗网络
│ ├── humanseg, 人体解析
│ ├── keypoint_detection
│ ├── object_detection, 目标检测
│ ├── semantic_segmentation, 语义分割
│ ├── style_transfer, 风格迁移
│ ├── super_resolution, 超分辨率
│ └── text_recognition
├── text
│ ├── embedding
│ ├── language_model
│ ├── lexical_analysis
│ ├── semantic_model
│ ├── sentiment_analysis
│ ├── syntactic_analysis
│ │ └── DDParser
│ ├── text_generation
│ │ └── reading_pictures_writing_poems
│ └── text_review
└── video
└── classification
└── videotag_tsn_lstm
3.1. 工业级图像分割利器: PaddleSeg
目前,PaddleSeg 已经在百度无人车、AI开放平台人像分割、小度P图和百度地图等多个产品线上应用或实践,在工业质检行业也已经取得了很好的效果。
3.1.1. 图像分割是什么?
图像语义分割通过给出每一个图像中像素点的标签,实现图像中像素级别的语义分割,它是由图像处理到图像分析的关键步骤。就像下图中所看到的那样,可以对车辆、马路、人行道等实例进行分割和标记!

相比于传统的图像分类任务,图像分割显然更难更复杂。但是,图像分割是图像理解的重要基石,在自动驾驶、无人机、工业质检等应用中都有着举足轻重的地位。
3.1.2. PaddleSeg
PaddleSeg 对所有内置的分割模型都提供了公开数据集下的预训练模型,全面覆盖了 DeepLabv3+、ICNet、U-Net 等图像分割领域的主流模型实现,并且内置了 ImageNet、COCO、CityScapes 等数据集下的 15 个预训练模型,可以满足不同场景下的不同精度需求和性能需求。
15 个预训练模型,请参考: https://github.com/PaddlePaddle/PaddleSeg/blob/master/docs/model_zoo.md
其中,最重要的三种模型介绍如下。
-
U-Net 模型:轻量级模型,参数少,计算快
U-Net 起源于医疗图像分割,整个网络是标准的 Encoder-Decoder 网络,特点是参数少,计算快,应用性强,对于一般场景的适应度很高。
-
DeepLabv3+模型 :PASCAL VOC SOTA 效果,支持多种 Backbone
DeepLabv3+是 DeepLab 系列的最后一篇文章,其前作有 DeepLabv1,DeepLabv2, DeepLabv3。在最新作中,DeepLab 的作者通过 Encoder-Decoder 进行多尺度信息的融合,同时保留了原来的空洞卷积和 ASSP 层,其骨干网络使用了 Xception 模型,提高了语义分割的健壮性和运行速率,在 PASCAL VOC 2012 dataset 取得新的 state-of-art performance,即 89.0mIOU。
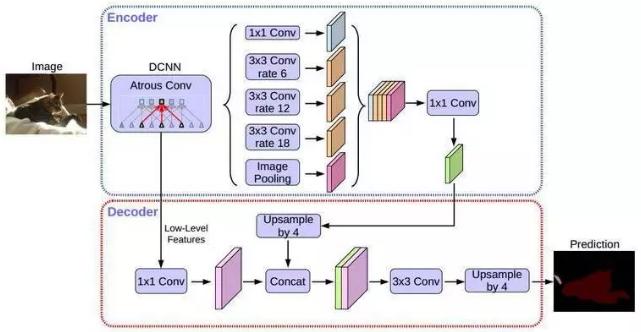
在 PaddleSeg 当前实现中,支持两种分类 Backbone 网络的切换:
-
Xception:
DeepLabv3+原始实现的 backbone 网络,兼顾了精度和性能,适用于服务端部署。PaddleSeg 提供了 41/65/71 三种不同深度的预训练模型。
-
MobileNetv2:
适用于移动端部署或者对分割预测速度有较高要求的场景,PaddleSeg 还提供从 0.5x 到 2.0x 不同 DepthMultiplier 的模型。
-
-
ICNet 模型:实时语义分割,适用于高性能预测场景
ICNet(Image Cascade Network)主要用于图像实时语义分割。相较于其它压缩计算的方法,ICNet 既考虑了速度,也考虑了准确性。ICNet 的主要思想是将输入图像变换为不同的分辨率,然后用不同计算复杂度的子网络计算不同分辨率的输入,然后将结果合并。ICNet 由三个子网络组成,计算复杂度高的网络处理低分辨率输入,计算复杂度低的网络处理分辨率高的网络,通过这种方式在高分辨率图像的准确性和低复杂度网络的效率之间获得平衡。
3.1.3. 数据增强
特别值得一提的是,考虑到在实际的企业场景中(如互娱场景等),往往存在标注成本高、标注数据少的问题,训练数据相对于整个样本空间的占比是非常小的。此时就很有必要采取数据增强策略,对训练集进行扩充。
PaddleSeg 内置了 10 余种数据增强策略,可以有效地帮助企业进行数据集扩充,显著提升模型的鲁棒性。

3.1.4. LIP挑战赛: 人体解析模型
提供包揽 CVPR2019 LIP 挑战赛人体解析任务大满贯三冠王 ACE2P 模型,带你一步体验世界领先水平效果。

3.1.5. 应用场景: 工业质检
飞桨与国内稀土永磁零件质检领军企业合作,基于 PaddleSeg 模型库,对精密零件的质检工作进行了 AI 赋能升级。

传统的工作方式下,质检工人每天需要 8~12 小时在亮光下目视检查直径 45mm 以内零件的质量,工作强度非常大,对视力也有很大的损害。
目前,基于 PaddleSeg 内置 ICNet 模型实现的精密零件智能分拣系统,误收率已低于 0.1%。对于 1K*1K 分辨率的彩色图像,预测速度在 1080Ti 上达到了 25ms,单零件的分拣速度比用其他框架实现的快 20%。PaddleSeg 已帮助工厂达到:生产成本平均降低 15%,工厂效益平均提升 15%。同时,交付质量也大幅提升,投诉率平均降低 30%。
3.1.6. 应用场景: 地块分割
基于图像分割技术,开发一款地块智能分割系统,快速自动地获知农耕用地边境及面积,就可以更加有效地进行农作物产量预估和农作物分类,辅助农业决策。

目前,基于 PaddleSeg 内置模型 DeepLabv3 实现的地块智能分割系统,面积提取准确率已达到了 80% 以上,这对作物长势、作物分类、成熟期预测、灾害监测、估产等工作都起到了高效的辅助作用,大大节省了人力成本。
3.1.7. 应用场景: 车道线分割
车道线分割的难点主要有两个:
- 准确度: 由于涉及到车辆行驶的安全性,车道线分割对准确度的要求非常非常高的
- 实时性: 在车辆高速行驶的过程中,必须快速地、实时地提供车道线分割结果

3.1.8. 应用场景: 人像分割
不仅在工业场景下,在 C 端互娱领域,短视频人像特效、证件照智能抠图、影视后期处理等场景下,都需要对人像进行分割。例如,一寸照片换底色,蓝色、白色、红色切换。
基于 PaddleSeg 实现的人像分割模型,mIoU 指标已经达到了 0.93 以上,并且已经在百度 AI 开放平台上线,合作企业高达 60 余家,是真正的产业利器。
3.1.9. 代码实战体验
为了更好的体验分割库的效果,避免因为软硬件环境导致的各种问题,我们采用了 AIStudio 一站式实训开发平台作为体验环境,通过完整的人像分割的实例教程来熟悉 PaddleSeg 的使用。
传送门: https://aistudio.baidu.com/aistudio/projectdetail/110669
项目代码内容都是经过研发人员细心优化并封装好顶层逻辑,可以让开发者最快方式体验 PaddleSeg 的效果,以下代码内容供参考核心流程及思路,实际体验建议开发者完整 Fork 项目并点击全部运行即可。

3.2. 视频理解黑科技: VideoTag
面对海量的视频数据,如何推荐用户感兴趣的视频?
互联网视频分类任务的目标是理解视频的语义,并给视频打上标签,标签包括不限于美食、旅游、影视/游戏等等。标签越精细、在视频分发和推荐时,准确率越高。
熟悉深度学习的同学们都知道,数据集对于算法的研究起着非常重要的作用。对于视频分类任务而言,网络上虽然有大量用户上传的视频数据,但它们大多缺少类别标签,无法直接用于模型训练。在学术界,Kinetics系列是最热门的视频分类数据集,但其数据量(以Kinetics-400为例,包含23万个视频)与当前国内主流APP的数据量(千万/亿/十亿量级)相比较,也是云泥之别,且视频内容与互联网短视频也存在较大差异。
此外,视频中包含成百上千帧图像,处理这些帧图像需要大量的计算。基于TSN、TSM、SlowFast视频分类模型,使用Kinetics-400数据,模型训练大概需要1周才能达到70%~80%的Top-1精度,面对上千万的数据量,显然学术界模型是无法实现产业应用的。
Paddle大规模视频分类模型VideoTag,基于百度短视频业务千万级数据,在训练速度上进行了全面升级;支持3000个源于产业实践的实用标签;引入ActivityNet冠军模型 Attention Cluster 等,在测试集上达到90%的精度;具备良好的泛化能力,非常适用于国内大规模(千万/亿/十亿级别)短视频分类场景的应用。
考虑到国内主流APP视频数据量巨大,为了提升模型训练速度,VideoTag采用两阶段建模方式,即图像建模和序列学习。
- 第一阶段,使用少量视频样本(十万级别)训练大规模视频特征提取模型;
- 第二阶段,使用千万级数据进行序列学习,最终实现在超大规模(千万/亿/十亿级别)短视频上产业应用。
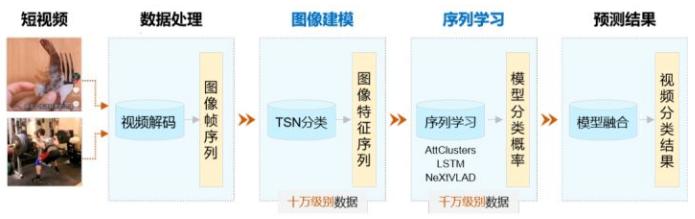
-
数据处理
视频是按特定顺序排列的一组图像的集合,这些图像也称为帧。视频分类任务需要先对短视频进行解码,然后再将输出的图像帧序列灌入到VideoTag中进行训练和预测。
-
图像建模
先从训练数据中,对每个类别均匀采样少量样本数据,构成十万量级的训练样本。然后使用TSN网络进行训练,提取所有视频帧的TSN模型分类层前一层的特征数据。在这个过程中,每一帧都被转化成相应的特征向量,一段视频被转化成一个特征序列。
-
序列学习
采用Attclusters、LSTM和Nextvlad对特征序列进行建模,学习各个特征之间的组合方式,进一步提高模型准确率。由于序列学习相比于图像建模耗时更短,因此可以融合多个具有互补性的序列模型。
-
预测结果
融合多个模型结果实现视频分类,进一步提高分类准确率。
在训练过程中,可以使用少量GPU和CPU Hadoop集群完成如上操作,实现较少耗时(1周左右),就可以完成VideoTag模型训练。
3.3. 中文字符识别: PaddleOCR
2020.08: GitHub Trending第一之后,PaddleOCR再发大招:百度自研顶会SOTA算法正式开源

模型画像:
- 总模型大小仅8.6M
- 仅1个检测模型(4.1M)+1个识别模型(4.5M)组成
- 同时支持中英文识别
- 支持倾斜、竖排等多种方向文字识别
- T4单次预测全程平均耗时仅60ms
- 支持GPU、CPU预测
- 可运行于Linux、Windows、MacOS等多种系统

我们知道,训练与测试数据的一致性直接影响模型效果,为了更好的模型效果,经常需要使用自己的数据训练超轻量模型。PaddleOCR本次开源内容除了8.6M超轻量模型,同时提供了2种文本检测算法、4种文本识别算法,并发布了相应的4种文本检测模型、8种文本识别模型,用户可以在此基础上打造自己的超轻量模型。
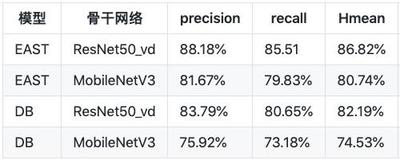
PaddleOCR本次开源了多种业界知名的文本检测和识别算法,每种算法的效果都达到或超越了原作。文本检测算法部分,实现了EAST[1]和DB[2]。在ICDAR2015文本检测公开数据集上,算法效果如下:
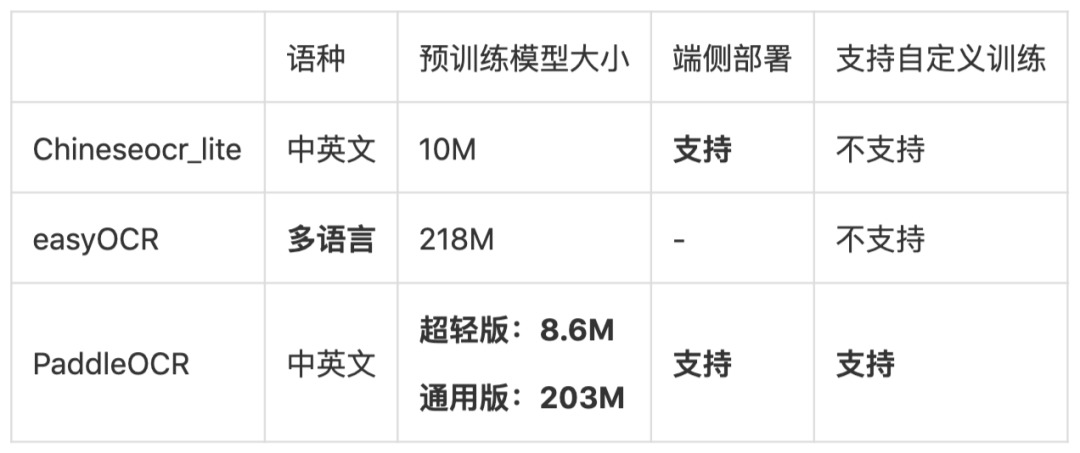
简单对比一下2020年主流OCR方向开源repo的核心能力:
3.3.1. 百度自研SAST、SRN两大SOTA算法
面向自然场景任意形状文字检测问题,开源ACM Multimedia 2019上发表的SAST(A Single-Shot Arbitrarily-Shaped Text Detector based on,Context Attended Multi-Task Learning)算法,在多个公开数据集(包括SCUT-CTW1500,Total-Text,ICDAR15 和 MLT),准确度取得了SOTA或可比的结果,速度上位列领先行列。
面向场景文本图像中兼顾视觉信息和语义信息的需求,开源CVPR2020中发表的SRN(Towards Accurate Scene Text Recognition with Semantic Reasoning Networks )算法,在包括ICDAR13、ICDAR15,IIIT5K,SVT,SVTP,CUTE80数据集,准确度取得了SOTA或可比的结果。
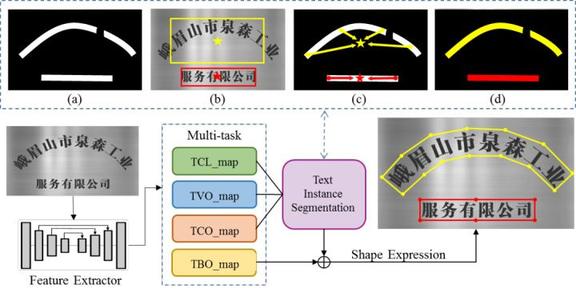
3.3.2. *开源算法详细解读


想要使用自定义数据训练超轻量模型的小伙伴,可以参考8.6M超轻量模型的打造方式,从PaddleOCR提供的基础算法库中选择适合自己的文本检测、识别算法,进行自定义的训练。PaddleOCR提供了详细的训练和模型串联指导: https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/customize.md
3.4. 目标检测
PaddleDetection此次发布的端侧模型涵盖了三类主流模型结构,按照设计思想可以分为单阶段和两阶段:
-
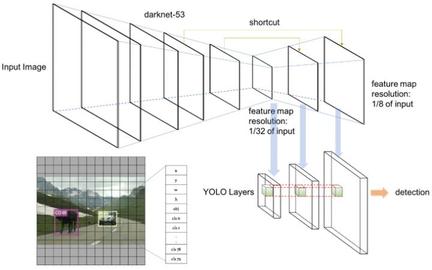
单阶段(One-stage)
这类模型结构相对简单,通常在全卷积网络(FCN)上直接连接检测头输出类别及位置信息。典型代表有:SSD系列、YOLO系列。这类结构由于其pipeline相对短,相对延时低,对移动应用比较友好。尤其是SSD系列,在端侧使用广泛,各种人脸,手势检测应用中都能见到它的身影。
-
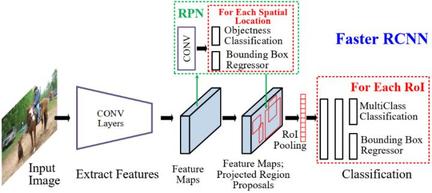
两阶段 (Two-stage)
顾名思义,这类结构将检测流程分为两个阶段:
- 第一阶段输出粗糙的候选框(proposal),
- 第二阶段将候选框对应特征提取出来,在其基础进一步预测类别并细化输出位置信息。
代表结构如Faster R-CNN。这种设计的好处是位置信息较为精确,小目标的检测精度更好。但是由于组成部分较多,整体流程较长,时延往往会比较高,很难在端侧成功落地(后面可以看到,通过使用百度的优化方法,这类模型在端侧也能取得不俗的成绩)。
3.4.1. 优化思路
上述两类模型的运行流程如下所示:
- 单阶段: 特征提取 -> 检测头 -> 后处理
- 两阶段: 特征提取 -> RPN (Region Proposal Network) -> ROI池化 -> 检测头 -> 后处理
其中,ROI池化和后处理多为手工设计的模块,依赖于部署框架的实现;RPN只有2个卷积层,且输出通道数仅为4和1,运行时间占比不高。综合来看,优化特征提取器和检测头是减少端侧运算量的关键。
3.4.2. 优化特征提取器
通用物体检测模型的特征提取器通常使用基于ImageNet预训练的CNN模型(ResNet, ResNeXt, MobileNet, ShuffleNet)等作为主干网络(Backbone)。主干网络预训练模型的精度和速度会极大的影响检测模型的最终表现。飞桨图像分类库PaddleClas的预训练模型为主干网络提供了丰富的选择。例如端侧通用检测模型常用的MobileNet系列,就有多个版本(部分精度及延时对比见下表)。
我们统一使用了半监督学习知识蒸馏预训练的MobileNetV3,最终各检测模型在COCO mAP上均获得了0.7%~1.5%的精度提升。以YOLOv3为例,用MobileNetV3替换MobileNetV1作为主干网络,COCO的精度从29.3提升到31.4,而且骁龙855芯片上推理时延从187.13ms降低到155.95ms。
需要注意的是,由于蒸馏的预训练模型的特征非常精细,需要适当减小主干网络的相对学习率及L2 decay,防止在训练的过程中破坏其特征。
3.4.3. 优化特征融合FPN
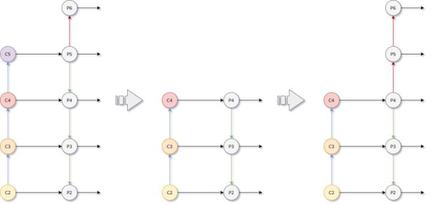
为了进一步将多层的特征进行有效融合(fusion)及细化(refine),Faster R-CNN模型使用了FPN(Feature Pyramid Network )模块,其中选择哪些特征层进行FPN融合及后续处理非常关键。对于MobileNet主干网络,通常使用C2~C5特征层进行特征融合。
融合处理后,输出5个特征层(P2P6),分辨率从1/4到1/64。为了提升预测速度,我们尝试减少一个特征层,即只输入C2C4,生成P2P4,该调整可以减少21%的延时,但在COCO数据集上mAP仅降低了0.9%。进一步分析发现在此特征组合下,RPN输出大物体的召回率很低。由此,我们在FPN模块里添加降采样卷积,额外生成P5P6,此修改将COCO mAP提升了1.3%,但预测时间仅增加9%左右。
3.4.4. 优化检测头
检测头通常由多层卷积组成。当提取特征的骨干网络的运算量减少后,如果继续使用检测头的标准配置,耗时将会成为优化的主要瓶颈。例如,在YOLOv3-MobileNetv3中,检测头部分的耗时约占50%。缩小检测头,减少检测头的预算量,对于端侧模型来说是一个非常重要的优化环节。一般是通过手动设计或者通过模型压缩裁剪策略,对检测头的卷积层进行结构化裁剪来实现。
比如,我们对两阶段Faster R-CNN模型,大幅减少FPN的卷积通道数量(256->48)及检测头的全连接层通道数量(1024->128)。在YOLOv3模型中,通过模型压缩的裁剪方法对检测头进行裁剪,下文有详细的实战说明。
3.4.5. 已发布模型
这次PaddleDetection发布了三类模型,根据模型本身的设计特点选择使用上述技巧,最终的收益非常显著。
- Faster-RCNN: 在调整FPN结构的基础上手动减少了FPN及检测头的通道数,并使用AutoAugment数据增强、余弦学习率策略及Balanced L1 loss进行训练
- YOLOv3:使用剪裁缩小检测头提升速度,并使用蒸馏训练来提升模型精度。
- SSDLite:使用余弦学习率策略训练,并使用量化训练进一步加速。
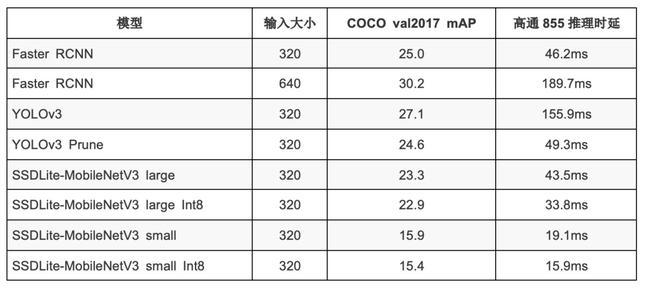
最终发布的模型测评结果可参考下表:
3.4.6. PP-Yolo
目标检测的王牌家族——YOLO系列模型,作为单阶段目标检测算法的代表之一,一经出世,便以快速精准的检测效果而迅速蹿红。其不仅在速度上做到真正实时,精度上也可以达到很多非实时两阶段模型才有的水平。
而学术界和开源社区中的YOLO拥趸、大神们,并未止步于此, YOLO v4、”YOLO v5”也在今年被相继推出,它们大量整合了计算机视觉 state-of-the-art 技巧,例如在数据增强、锚定框、骨架网络、训练方式等维度进行优化,从而达到大幅提升YOLO目标检测性能的效果。
飞桨目标检测套件PaddleDetection的研发团队也为了让YOLOv3模型在工业实际应用场景拥有更优异的精度与推理速度,以尽量不增加模型计算量和推理开销为前提,探索出了一整套更深度的算法优化秘籍,将原先YOLOv3模型的精度(在COCO test-dev2017数据集)从33.0%提升了12.9个绝对百分点,达到45.9%,处于业界领先行列!而在该精度下,其推理速度在V100上达到了72.9 FPS。
也就是说,它在精度和预测速度都超越原生的YOLOv4,并且体积更小,实打实的成为工业应用场景最实用目标检测模型。
而PP-YOLO所应用的这套优化策略,也可以被尝试应用到该系列的其它模型上,产业开发者或者科研人员可借鉴这套优化算法展开进一步的探索。
-
基于YOLOv3-DarkNet53的初步优化
-
更优的骨干网络: ResNet50vd-DCN
-
ResNet50vd: 拥有50个卷积层的ResNet-D网络
ResNet系列模型是在2015年提出后,在学术界和工业届得到了广泛的应用,其模型结构也在被业界开发者持续改进,在经过了B、C、D三个版本的改进后,最新的ResNet-D结构能在基本不增加计算量的情况下先住提高模型精度。经飞桨团队的多重实验发现,使用ResNet50vd结构作为骨干网络,相比于原始的ResNet,可以提高1%-2%的目标检测精度,且推理速度基本保持不变。
-
DCN(Deformable Convolution)可变形卷积
其卷积核在每一个元素上额外增加了一个可学习的偏移参数。这样的卷积核在学习过程中可以调整卷积的感受野,从而能够更好的提取图像特征,以达到提升目标检测精度的目的。但它会在一定程度上引入额外的计算开销。经过多翻尝试,PaddleDetection团队发现只在ResNet的最后一个stage(C5)增加可变形卷积,是实现引入极少计算量并提升模型精度的最佳策略。
在使用ResNet50vd-DCN作为骨干网络后,YOLOv3模型的检测精度从原先的38.9% 达到39.1%,而推理速度得到了36%的大幅提高(58.2FPS -> 79.2FPS)。
-
-
稳定的训练方式:EMA、DropBlock和更大的batch size
-
IoU学习
-
Grid Sensitive
-
后处理优化: Matrix NMS
-
特征提取优化: CoordConv, 空间金字塔池化
-
更优的预训练模型: SSLD

3.5. Paddle-Inference
3.6. Semantic label
4. 调参
4.1. 数据增强: AutoAugment
数据增强是提高神经网络准确性的有效技术,但是大部分的数据增强实现是手动设计的。自动增广AutoAugment,是将若干种组合策略,如图像平移、旋转、直方图均衡化等,组合为一个增广的集合,每次随机从其中选择一个子策略(该子策略也可能是多种增广的融合),并使用该策略对输入图像进行增广。经实验验证,在两阶段端侧检测模型上,使用该策略能够带来0.5%的精度提升。
值得提醒的一点:对小模型而言,由于本身学习能力有限,过度的数据增强很难提升模型的最终精度,甚至还可能起到相反的效果。例如,实验发现,两阶段端侧检测模型采用GridMask后,精度不升反降。
4.2. 学习率策略
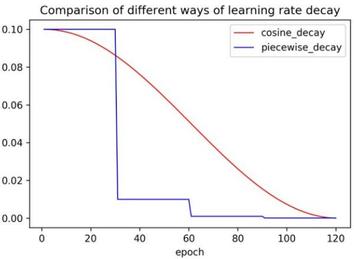
深度学习的训练是一个优化过程,训练过程中模型的权重会不断变化,而这个变化的速度由学习率决定。随着训练的进行,学习率本身也要不断的调整,从而避免模型陷入局部最优,鞍点或者最优点一直在附近振荡。合适的学习率调整策略会使得训练过程更加平滑,从而提升模型的最终精度。实验发现,相比通常的三段学习率,使用余弦学习率策略训练可以达到更高的精度,而且该策略不引入额外超参,鲁棒性较高。余弦学习率策略的计算公式如下:
decayed_lr = learning_rate ∗ 0.5∗(cos(epoch ∗ math.piepochs) + 1)
余弦学习率策略同三阶段学习率策略对比曲线如下:
4.3. Balanced L1 loss
Libra R-CNN 提出了 Balanced L1 loss 损失函数。中心思想是平衡目标检测的两种任务(定位及分类)及样本难度对模型训练的影响,从而达到更优的精度表现。具体做法是对定位任务的smooth L1 loss进行改进,通过对难样本(outlier)进行梯度裁剪(gradient clip),避免模型权重更新不平衡。
两阶段检测模型中,最后在检测头部分进行边框回归时,使用 Balanced L1 loss 替换传统的 smooth L1 loss ,可以带来0.4%的mAP提升。
4.4. 模型裁剪
卷积通道裁剪是一种很有效的在保证模型精度的情况下减小模型大小的解决方案。通过一定的裁剪机制,将重要性低的卷积通道剪裁掉,从而减小运算量。相比于手工设计缩小网络,基于模型压缩的裁剪算法更具通用性和迁移性。
目前PaddleDetection集成了飞桨模型压缩工具PaddleSlim,提供针对检测模型的压缩方案。在MobileNetv3-YOLOv3中就是通过此方案实现的模型加速。感兴趣的同学可以猛戳这里进行YOLOv3剪裁的实操实验。
4.5. 知识蒸馏
知识蒸馏 是一种很有效的提升模型精度的解决方案,该技术已被广泛应用于CV,NLP等多个领域。
主要原理是使用复杂、学习能力强的网络作为teacher,通过深度监督的方式将其学到的特征”知识” 传递给参数量小、学习能力弱的student网络。如下图所示,student模型在学习真实标签的同时,也会学习teacher网络预测的结果,将teacher网络的预测结果作为软标签作为目标计算损失和与正式标签作为目标计算的损失一起作为最终损失,从而在训练过程中能学习到高精度的teacher网络学习到的更优的知识。
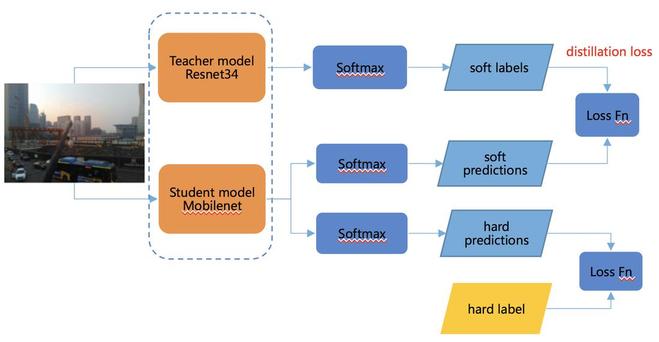
就CV而言,知识蒸馏的有效性在分类任务已获得大量验证,但目前在检测领域的应用还相对较少。我们在YOLOv3的检测头优化过程中尝试了蒸馏方式来fine tune剪裁后的模型,使用精度更高的YOLOv3-ResNet34模型作为teacher模型,对YOLOv3-MobileNetV3模型进行蒸馏。最终的实验结果表明,在COCO数据集上可以获得2-3个点的精度收益。感兴趣的同学可以继续猛戳这里进行实操实验。
4.6. 模型量化
考虑到端侧模型通常使用CPU部署,通常有较好的Int8 vectorization运算支持。使用Int8精度对FP32的模型进行量化,不仅可以减小存储体积,还能够对常见卷积、全连接的计算进行加速。
模型量化主流方式有:训练后量化 (Post training quantization)和量化训练(Quantization aware training)。
- 前者使用少量样本数据对模型进行校准,获取其权重及激活的动态数值范围,再根据该数据对权重进行量化。
- 后者在模型训练过程中对模型权重进行伪量化(fake quantization)使得模型能够适应量化带来的噪音,从而减少最终得精度损失。
我们在SSDLite的训练过程中使用这种量化方式,最终实现在少量精度损失(mAP -0.4%)的基础上加速22%左右的效果。
5. PaddleHub Samples
5.1. 图像识别
- 人像分割(HumanSeg)
- 人体部件分割 (ACE2P)
- 车道线分割(RoadLine)