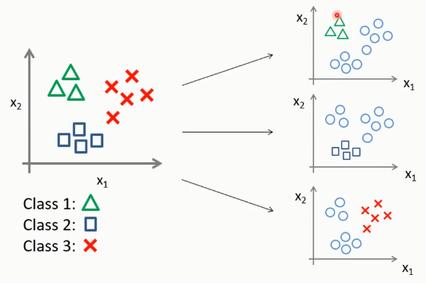
本文的目标,是“简单快速”的概括AI的模型和算法类型都有哪些,以及能够解决哪些问题。
1. 机器学习算法
1.1. 线性回归模型
回归分析(regression analysis)用来建立方程模拟两个或者多个变量之间如何关联。回归分析最典型的例子就是“房价预测”。
拓展知识:
- 代价函数(例如最小二乘法)
- 相关系数
- 决定系数
- 梯度下降法
- 数据归一化
- 交叉验证法
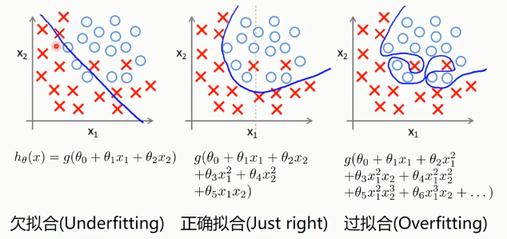
- 过拟合 & 欠拟合
- 正则化(Regularized)
- 阶惩罚函数
- L1正则
- L2正则

1.1.1. 多元线性回归

同样运用梯度下降法,求偏导,迭代更新权值,得到最优解。
1.1.2. 多项式回归

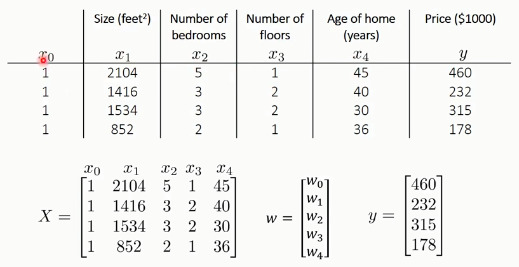
例如:以下为多元房价特征,进行房价预测:
1.1.3. 岭回归(Ridge Regression)
代价函数采用L2正则化:
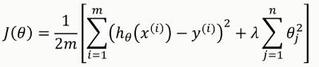
岭回归最早是用来处理特征数多于样本的情况,现在也用于在估计中加入偏差,从而得到更好的估计。同时也可以解决多重共线性的问题。岭回归是一种有偏估计。
1.1.4. LESSO
代价函数采用L1正则化:
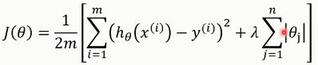
通过构造一个一获得一个精炼的模型;
- 擅长处理具有多重共线性的数据
- 与岭回归一样是有偏估计。
- L1正则化可以使一些指标(变量)的系数为零,解释力很强。相比而言,岭回归估计系数等于0的机会微乎其微,造成筛选变量困难。
1.2. 逻辑回归
Sigmoid/Logistic Function

拓展知识:
- 正确率
- 召回率
1.3. KNN
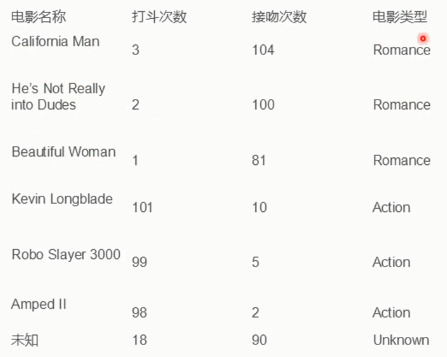
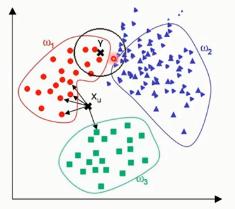
- 算法复杂度较高(需要比较所有已知实例与要分类的实例)
- 当其样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的末知实例实际并没有接近目标样本
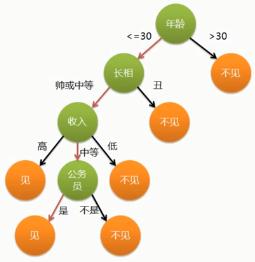
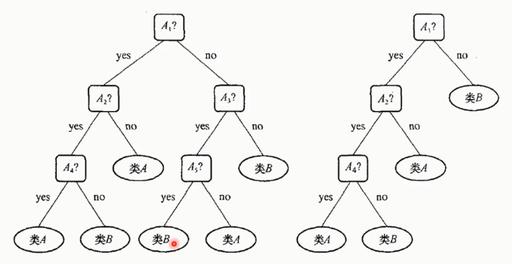
1.4. 决策树, Decision Tree
- 比较适合分析离散数据
- 如果是连续数据要先转成离散数据再做分析
1948年,香农提出了“信息熵”的概念。
一条信息的信息量大小和它的不确定性有直接的关系要搞清楚一件非常非常不确定的事情,或者是我们无所知的事情,需要了解大量信息->信息量的度量就等于不确定性的多少。
原理:通过各种“熵”来确认判断准则(条件优先级),常用的算法方式包括:
-
ID3算法
决策树会选择最大化信息增益来对结点进行划分
-
C4.5算法
信息增益的方法倾向于首先选择因子数较多的变量
-
CART算法
CART用基尼(Gin)系数最小化准则来进行特征选择
决策树的适用领域:
- 适用于小规模数据集
- 缺点:
- 处理连续变量不好
- 类别较多时,错误增加的比较快
- 不能处理大量数据
拓展知识:
- 预剪枝
- 后剪枝
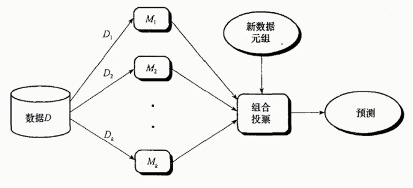
1.5. 集成学习
当做重要决定时,大家可能都会考虑吸取多个专家而不只是一个人的意见。集成学习也是如此。
集成学习就是组合多个学习器,最后可以得到一个更好的学习器。
集成学习算法:
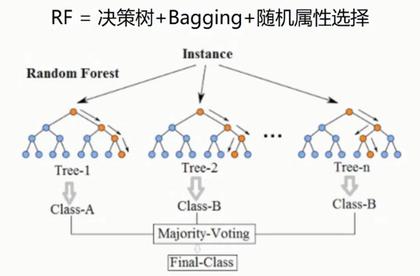
- 个体学习器之间不存在强依赖关系,装袋(bagging)
- 随机森林(Random forest)
- 个体学习器之间存在强依赖关系,提升(boosting)
- Stacking
1.5.1. Bagging
首先,进行一种有放回的抽样~
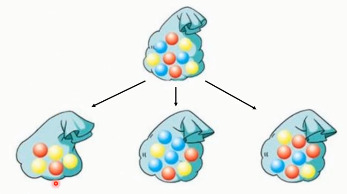

每个数据集,都采用一种不同的学习算法(或者同一个算法,得到不同的模型)
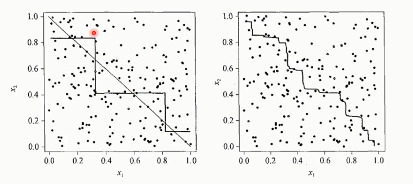
效果如下:
1.5.2. 随机森林
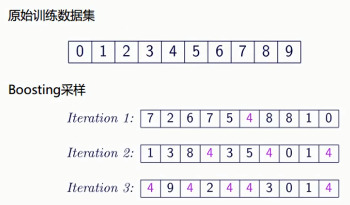
1.5.3. boosting(Adaptive Boosting,自适应增强)
学习器的重点放在“容易”出错的地方——增加出错数据的概率(样本采样的权值),从而优化权重。
1.6. 贝叶斯分类
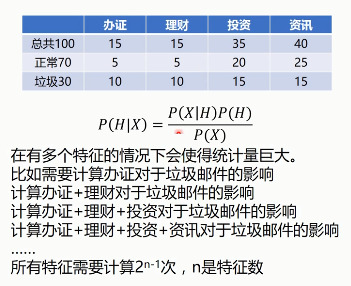
例如,判断垃圾邮件:
P(H): 垃圾邮件的先验概率
P(X): 特定特征的先验概率
P(X|H): 在垃圾邮件中,包含特定特征(比如“办证”)邮件的概率
P(H|X): 包含特定特征比如“办证”的邮件属于垃圾邮件的概率

已上是根据贝叶斯定理获得单一事件对概率的影响。
1.6.1. 朴素贝叶斯
多特征时的概率计算,会导致计算量巨大……
朴素贝叶斯算法,会假设特征X1, X2, X3...之间是相互独立的,则

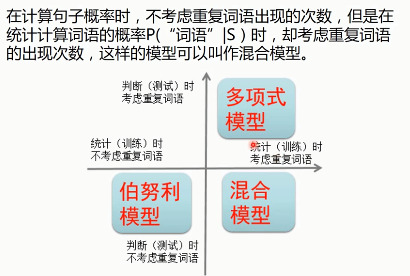
1.6.2. 贝叶斯多项式模型

1.6.3. 伯努利模型
1.6.4. 混合模型
1.6.5. 高斯模型
1.6.6. 大脑中的贝叶斯
Aoccdrnig to a rscheearch at Cmabrigde Uinervtisy, it deosn't mttaer in waht oredr the Itteers in a wrod are, the olny iprmoetnt ting is taht the frist and Isat Itter be at the rghit pclae. The rset can be a toatl mses and you can sitll raed it withuot porbelm. Tihs is bcuseae the huamn mnid deos not raed ervey I teter by istlef, but the wrod as a wlohe.
研表究明,汉字的序顺并不定一能影阅响读,比如当你看完这句话后,才发这现里的字全是乱的。
2. 聚类算法(无监督式学习)
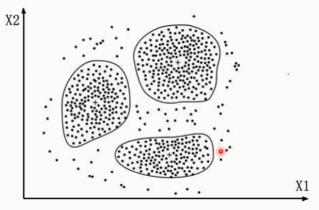
2.1. K-MEANS
以下为例,先随机定义元素的类型:
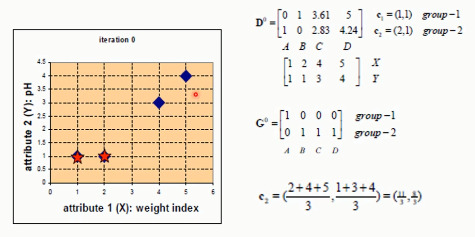
G:归类
C:计算重心,然后调整中心点
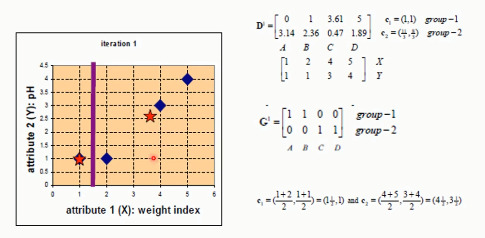
- 先从没有标签的元素集合A中随机取k个元素,作为 k 个子集各自的重心。
- 分别计算剩下的元素到 k 个子集重心的距离(这里的距离也可以使用欧氏距离),根据距离将这些元素分别划归到最近的子集
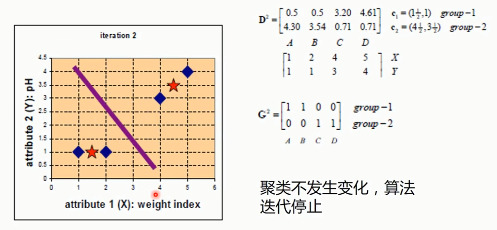
- 根据聚类结果,重新计算重心(重心的计算方法是计算子集中所有元素各个维度的算数平均数)
- 将集合A中全部元素按照新的重心然后再重新聚类。
- 重复第4步,直到聚类结果不再发生变化。