哈喽,大家好,我是强哥。
不知道大家Scala学得怎么样了?不过不管你们学得怎么样,反正我是简单的过过一遍了。诶~就是这么牛逼。
今天我们就开始正式学Spark了。
Spark是什么?
既然要学Spark,首先就要弄懂Spark是什么?或者说Spark能为我们做什么?
别到处百度。记住,直接看官网是最权威的:

从上图中我们看出几个重点:
- 多语言:说明Spark引擎支持多语言操作。
- 单节点或集群:单节点这个我们自己学习还是很有帮助的,毕竟大数据学习,有时候环境搭建就是个大工程
- 数据工程、数据科学和机器学习:这个是能干什么,我们接下来再讲。
Spark能做什么呢?
还是看官网:

从图中可见,Spark主要特点分为四个模块。具体更详细的我们以后慢慢学。现在先有个大概的了解。
而这四个模块又和Spark的4个库有关,在官网的Libraries页签下,我们可以看到有如下4个库(额外的一个第三方项目暂且不管):

- SQL and DataFrames :Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
- Spark Streaming :Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。
- MLlib(machine learning) :MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
- GraphX(graph) :GraphX 是 Spark 面向图计算提供的框架与算法库。
在我们之后Spark的学习中,重点也就在这些库上,当然了。现在直接去学还为时过早。先多熟悉下Spark再说,说到要熟悉,自然少不了和其他的项目比较,秉承:“长江后浪推前浪,前浪死在沙滩上”的原则,我们自然是要拿Spark和Hadoop来比较下拉。
Spark or Hadoop
-
Hadoop MapReduce 由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。所以 Spark 应运而生,Spark 就是在传统的 MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的 RDD 计算模型。
-
机器学习中 ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR 这种模式不太合适,即使多 MR 串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR 显然不擅长。而Spark 所基于的 scala 语言恰恰擅长函数的处理。
-
Spark 是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比 MapReduce 丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。
-
Spark 和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘。
-
Spark Task 的启动时间快。Spark 采用 fork 线程的方式,而 Hadoop 采用创建新的进程的方式。
-
Spark 只有在 shuffle 的时候将数据写入磁盘,而 Hadoop 中多个 MR 作业之间的数据交互都要依赖于磁盘交互。
-
Spark 的缓存机制比 HDFS 的缓存机制高效。
经过上面的比较,我们可以看出在绝大多数的数据计算场景中,Spark 确实会比 MapReduce更有优势。但是 Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致 Job 执行失败,此时,MapReduce 其实是一个更好的选择,所以 Spark并不能完全替代Hadoop MR。
下载Spark
Spark了解得差不多了,之后肯定就是开始快速上手了。当然,要耕田首先得有锄头吧,我们先去把Spark下载下来再说。
直接在官网的Download的页签下下载。下什么版本?秉承“喜新厌旧”原则,先下载最新的再说。如果之后的学习有遇到版本问题大不了再换。强哥也知道大家公司里很多用的还是Spark2.x,这个看个人喜好哈,下载2.x的也不是不行。
强哥这里下载当前能下到的最新版本:spark-3.2.1-bin-hadoop3.2.tgz,下载地址如下:
https://dlcdn.apache.org/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgz
下完后,解压。然后进入解压目录输入如下命令:
./bin/spark-shell
效果如下:
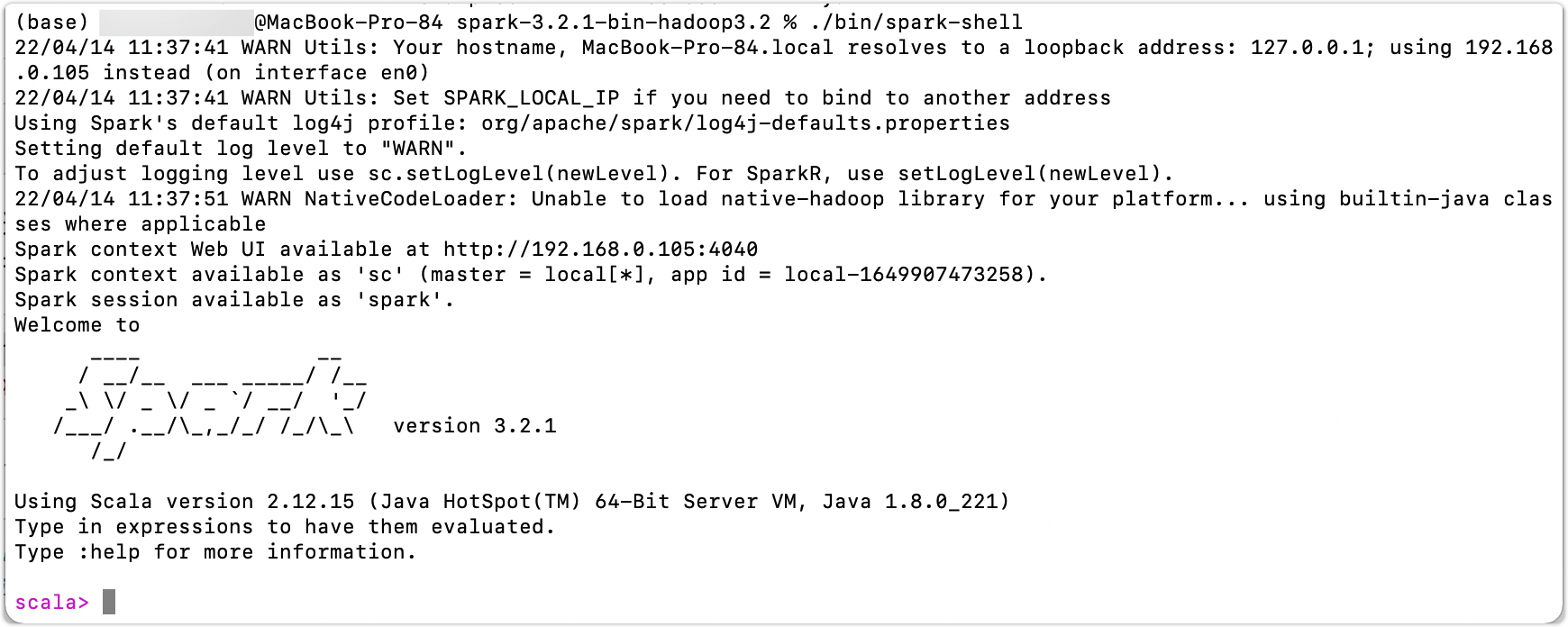
这样就说明我们的下载的包是正常能用的了。那么放着就行,我们后面会用到它进行学习。
Before Quick Start
在要进行进一步的学习之前。这里强哥也要提一句,官网有这么一个说明非常重要:
Note that, before Spark 2.0, the main programming interface of Spark was the Resilient Distributed Dataset (RDD). After Spark 2.0, RDDs are replaced by Dataset, which is strongly-typed like an RDD, but with richer optimizations under the hood. The RDD interface is still supported, and you can get a more detailed reference at the RDD programming guide. However, we highly recommend you to switch to use Dataset, which has better performance than RDD. See the SQL programming guide to get more information about Dataset.
在学习Spark之前,我们肯定有听很多人聊过RDD,但是具体是什么却可能不太熟悉。官网这里的说明告诉我们,RDD在Spark2.0之后被Dataset取代了,Dataset比RDD更牛逼,官网推荐我们使用Dataset,而不是RDD。
所以,大家之后的学习重点应该放在哪个应该不用我多说了吧。当然了,现在这俩玩意其实都还不是很懂。没事,跟着强哥一起学,慢慢会懂的。