哈喽,大家好,我是强哥。
这几天,鬼灭之刃游郭篇就要上线了,强哥的一个朋友非常喜欢鬼灭之刃,可以说是到了痴迷的地步。每次新篇上线都会第一时间观看。虽然这次上线之前,这家伙就已经看过了,不过这消息还是把他激动的不行,拉着我要我和他重温一遍。

这不,昨天,还找我要了个爬虫代码,去网上搜刮各种鬼灭之刃相关的图片。可是,在我给他代码后不到一个小时,这家伙就又骂骂咧咧的跑过来找我算账了,说用了我的代码,刚开始爬得还挺好,很舒服。可是过了将近半小时,就发现,有两个他经常看图的网站爬不到图片了。而且,不用软件,自己用电脑浏览器也没法访问这俩网站了,这让他非常恼火。
听了他这么一说,我就大概明白了个十有八九,应该是爬的有点凶IP被封了。用手机5G网络看了下对应的网站,确实还是可以正常访问,那就没错了。
赶紧和这家伙说了一些爬虫相关法律知识,爬虫虽好可以解脱我们的双手,可是爬的太凶容易被请喝茶。前几年不是还有个公司的CTO和程序员被抓判刑了吗。所以自己还是要控制好频率,不要没有节制……
大道理讲了一通,可是,现在他还想继续下怎么办呢?没办法,只好找找代理了,这家伙又是化石白嫖党,让他出钱是没办法了,强哥只好自己祭出大招了。
IP代理池
没错,要解决这个办法,最简单好用的就是IP代理池了,也就是搞到一大堆的可正常使用的代理IP,然后我们用爬虫的时候,请求不直接发送到目标网站,而是借助代理IP,把请求先发到代理服务器,代理服务器再帮我们把请求发送到目标网站。这样,假如被目标网站发现了,封的也是代理的IP不是我们自己的IP啦。
至于为什么要用到代理池,主要还是怕老用同一个代理IP被封了就又没法访问了,多搞几个宁滥毋缺嘛。
ProxyPool
既然要白嫖,那必须找找开源项目。既然要找开源项目,那必须要够专业的才配的上强哥的代码。所以,这次的主角是《Python3网络爬虫开发实战》的作者崔庆才的开源项目:ProxyPool。
先简单介绍下项目结构吧:

代理池分为四个部分,获取模块、存储模块、检测模块、接口模块。
- 存储模块使用 Redis 的有序集合,用以代理的去重和状态标识,同时它也是中心模块和基础模块,将其他模块串联起来。
- 获取模块定时从代理网站获取代理,将获取的代理传递给存储模块,保存到数据库。
- 检测模块定时通过存储模块获取所有代理,并对其进行检测,根据不同的检测结果对代理设置不同的标识。
- 接口模块通过 Web API 提供服务接口,其内部还是连接存储模块,获取可用的代理。
项目原理是在各大提供IP代理池的网站把IP搞过来然后程序测试能用之后,才会存下来供我们使用,相当于帮助我们省去了找免费IP代理的时间。
当然,如果只是拿来用,也不用过多的在意这些细节,我们直接冲。
上手
ProxyPool需要本地运行起来,运行起来后,会在本地暴露一个接口地址:
http://localhost:5555/random
直接访问即可获取一个随机可用代理IP。
强哥用Docker方式下载项目镜像后,用docker-compose up命令把服务运行起来了,然后浏览器访问效果如下:

没错,返回的120.196.112.6:3128就是代理IP啦。
Docker镜像下载方式:
docker pull germey/proxypool
也想搞一波的小伙伴,自己到GitHub上看看吧,用起来还是很简单的:
https://github.com/Python3WebSpider/ProxyPool
怎么帮朋友
既然工具有了,就把之前我给朋友的爬虫代码拿过来,把代理池怼上去就行了。当然,这里就不直接暴露我的爬虫代码了,给一个官方示例代码吧,和我写的也差不多:
import requests
proxypool_url = 'http://127.0.0.1:5555/random'
target_url = 'http://httpbin.org/get'
def get_random_proxy():
"""
get random proxy from proxypool
:return: proxy
"""
return requests.get(proxypool_url).text.strip()
def crawl(url, proxy):
"""
use proxy to crawl page
:param url: page url
:param proxy: proxy, such as 8.8.8.8:8888
:return: html
"""
proxies = {'http': 'http://' + proxy}
return requests.get(url, proxies=proxies).text
def main():
"""
main method, entry point
:return: none
"""
proxy = get_random_proxy()
print('get random proxy', proxy)
html = crawl(target_url, proxy)
print(html)
if __name__ == '__main__':
main()
可以看到,用到代理的方式关键就是这句:requests.get(url, proxies=proxies),直接把获取到的代理IP搞到proxies去就行了。
这里还要提到代码中用到的另一个开源项目的地址,对,就是http://httpbin.org/get,我们可以根据这个地址返回的数据判断我们发起访问该地址的IP。
强哥直接用浏览器访问的效果:

可以看到这里用了本地IP。
换用上面的代理代码访问的效果:
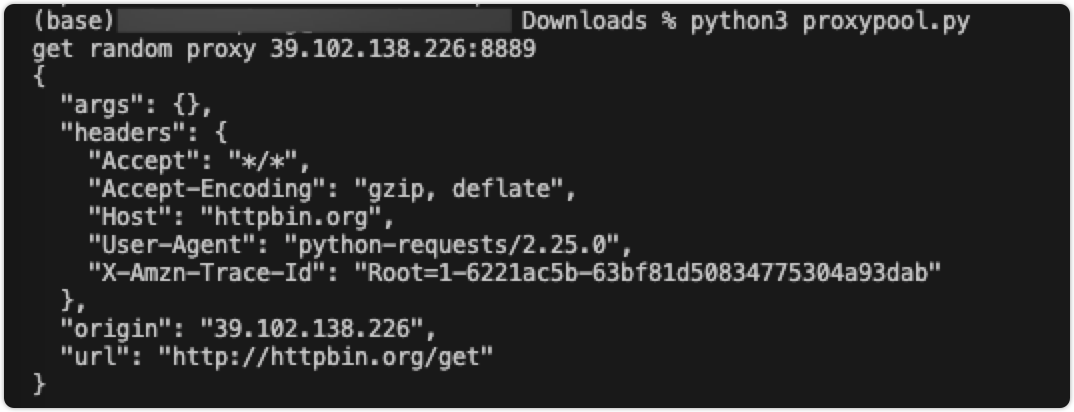
可以看到,返回的origin确实使用了代理IP。也就是说,我们的IP代理池使用成功了。
强哥朋友在拿到新的爬虫代码,并进行了频率的节制,终于不再怎么被封IP了。顺带送了我一张图:
怎么说呢?没咬竹子的祢豆子不是好豆子。
搞更深点
IP代理池这玩意除了用在爬虫上还会被用在哪呢?
嗯……如果看了强哥上篇文章的小伙伴应该能猜到,当然是DoS攻击了,其实爬虫和DoS攻击,在某些地方还是有交集的,爬虫控制的不好很可能就成了DoS。这个就不做过多扩展了。
强哥前天还看了个DoS攻击的项目,用到了反射原理来进行的攻击,哈哈,之前都是看DoS攻击方式介绍的时候有了解到,这回看到代码还挺激动,有机会和大家也介绍下。