https://blog.csdn.net/boling_cavalry/article/details/86747258
https://www.cnblogs.com/xuliangxing/p/7234014.html
第二个链接较为详细,但版本较旧

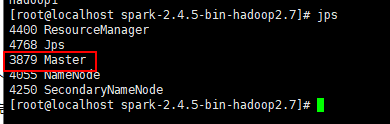
注意spark 7077端口URL,如果hostname没配置正确,spark-submit会报错
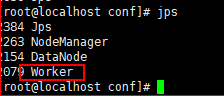
jps看了两个slaves是有worker进程的。
spark安装完毕,启动hadoop集群:./sbin/./start-all.sh
jps可查看
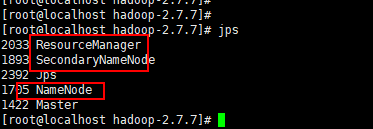
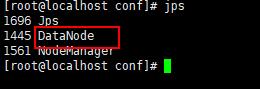
spark提交任务的三种的方法
https://www.cnblogs.com/itboys/p/9998666.html

虚拟机分配内存不足,解决方案参考:https://blog.csdn.net/u012848709/article/details/85425249


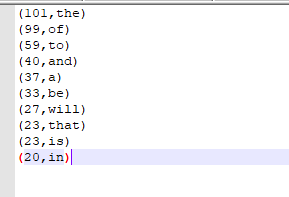
最后终于跑完了,把输出结果get下来
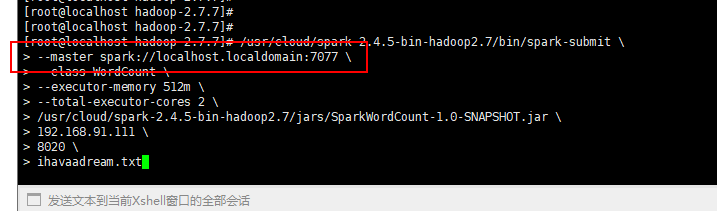
在master输入以下命令,最后三项为入参,9000为hadoop端口:
/usr/cloud/spark-2.4.5-bin-hadoop2.7/bin/spark-submit
--master spark://192.168.91.111:7077
--class WordCount
--executor-memory 512m
--total-executor-cores 2
/usr/cloud/spark-2.4.5-bin-hadoop2.7/jars/SparkWordCount-1.0-SNAPSHOT.jar
192.168.91.111
9000
ihavaadream.txt
=====================WordCount代码如下:======================
import org.apache.commons.lang3.StringUtils;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import scala.Tuple2;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
public class WordCount {
private static final Logger logger = LoggerFactory.getLogger(WordCount.class);
public static void main(String[] args) {
if(null==args
|| args.length<3
|| StringUtils.isEmpty(args[0])
|| StringUtils.isEmpty(args[1])
|| StringUtils.isEmpty(args[2])) {
logger.error("invalid params!");
}
String hdfsHost = args[0];
String hdfsPort = args[1];
String textFileName = args[2];
SparkConf sparkConf = new SparkConf().setAppName("Spark WordCount Application (java)");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
String hdfsBasePath = "hdfs://" + hdfsHost + ":" + hdfsPort;
//文本文件的hdfs路径
String inputPath = hdfsBasePath + "/input/" + textFileName;
//输出结果文件的hdfs路径
String outputPath = hdfsBasePath + "/output/"
+ new SimpleDateFormat("yyyyMMddHHmmss").format(new Date());
logger.info("input path : {}", inputPath);
logger.info("output path : {}", outputPath);
logger.info("import text");
//导入文件
JavaRDD<String> textFile = javaSparkContext.textFile(inputPath);
logger.info("do map operation");
JavaPairRDD<String, Integer> counts = textFile
//每一行都分割成单词,返回后组成一个大集合
.flatMap(s -> Arrays.asList(s.split(" ")).iterator())
//key是单词,value是1
.mapToPair(word -> new Tuple2<>(word, 1))
//基于key进行reduce,逻辑是将value累加
.reduceByKey((a, b) -> a + b);
logger.info("do convert");
//先将key和value倒过来,再按照key排序
JavaPairRDD<Integer, String> sorts = counts
//key和value颠倒,生成新的map
.mapToPair(tuple2 -> new Tuple2<>(tuple2._2(), tuple2._1()))
//按照key倒排序
.sortByKey(false);
// logger.info("take top 10");
//取前10个
List<Tuple2<Integer, String>> top10 = sorts.collect();
// List<Tuple2<Integer, String>> top10 = sorts.take(10);
StringBuilder sbud = new StringBuilder("top 10 word : ");
//打印出来
for(Tuple2<Integer, String> tuple2 : top10){
sbud.append(tuple2._2())
.append(" ")
.append(tuple2._1())
.append(" ");
}
logger.info(sbud.toString());
logger.info("merge and save as file");
//分区合并成一个,再导出为一个txt保存在hdfs
javaSparkContext.parallelize(top10).coalesce(1).saveAsTextFile(outputPath);
logger.info("close context");
//关闭context
javaSparkContext.close();
}
}
done!