









拷贝hive-site.xml到spark的conf目录下面

打开spark的conf目录下的hive-site.xml文件

加上这段配置(我这里三个节点的spark都这样配置)

把hive中的mysql连接包放到spark中去

检查spark-env.sh的hadoop配置项

检查dfs是否启动了
启动Mysql服务

启动hive metastore服务

启动hive

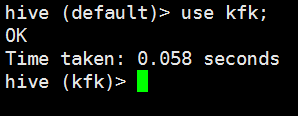
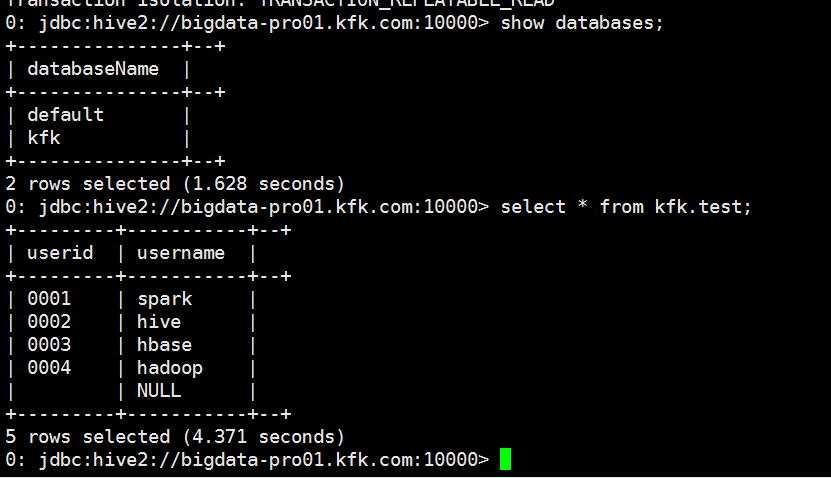
创建一个自己的数据库

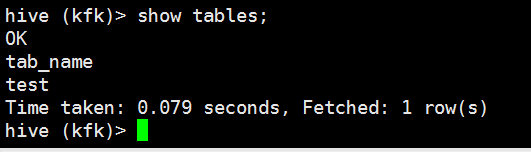
创建一个表

create table if not exists test(userid string,username string)ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS textfile;
我们现在本地建一个数据文件


把数据加载进这个表里来

load data local inpath "/opt/datas/kfk.txt" into table test;

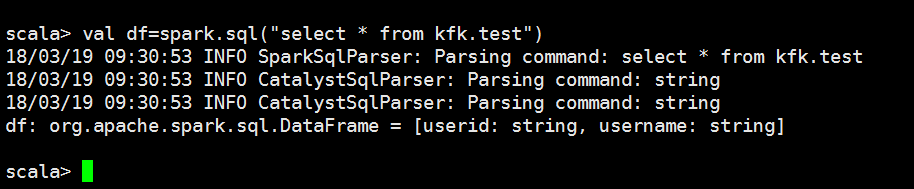
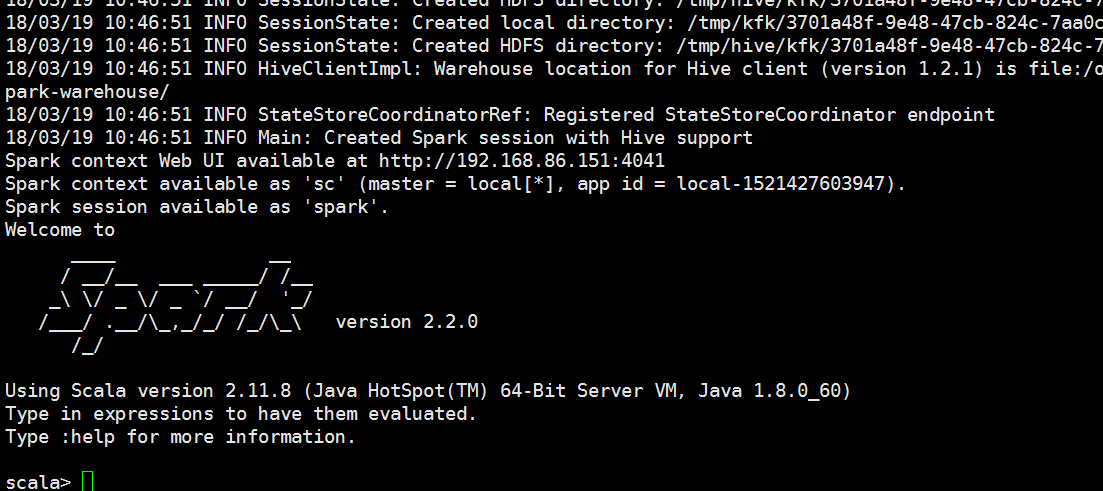
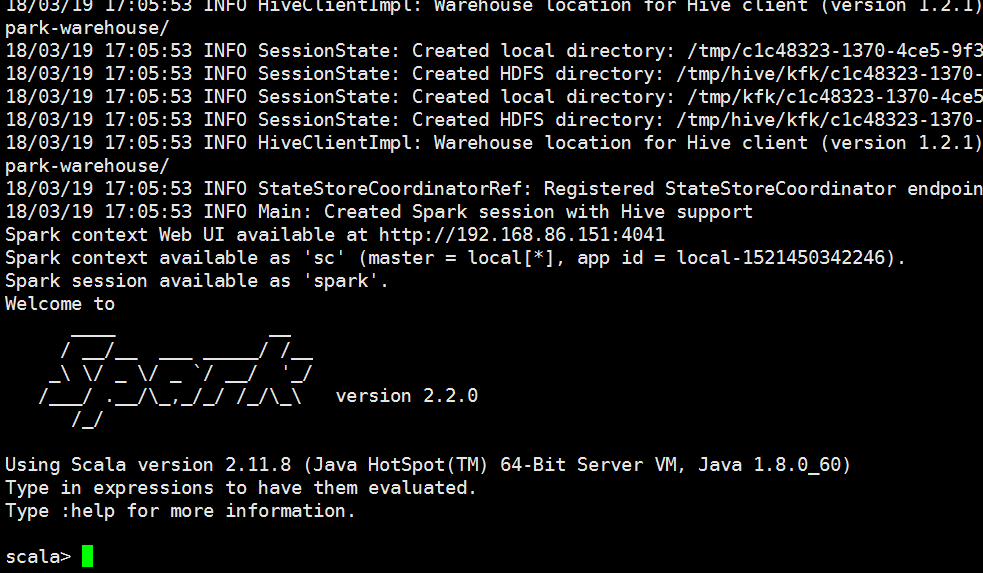
我们启动spark

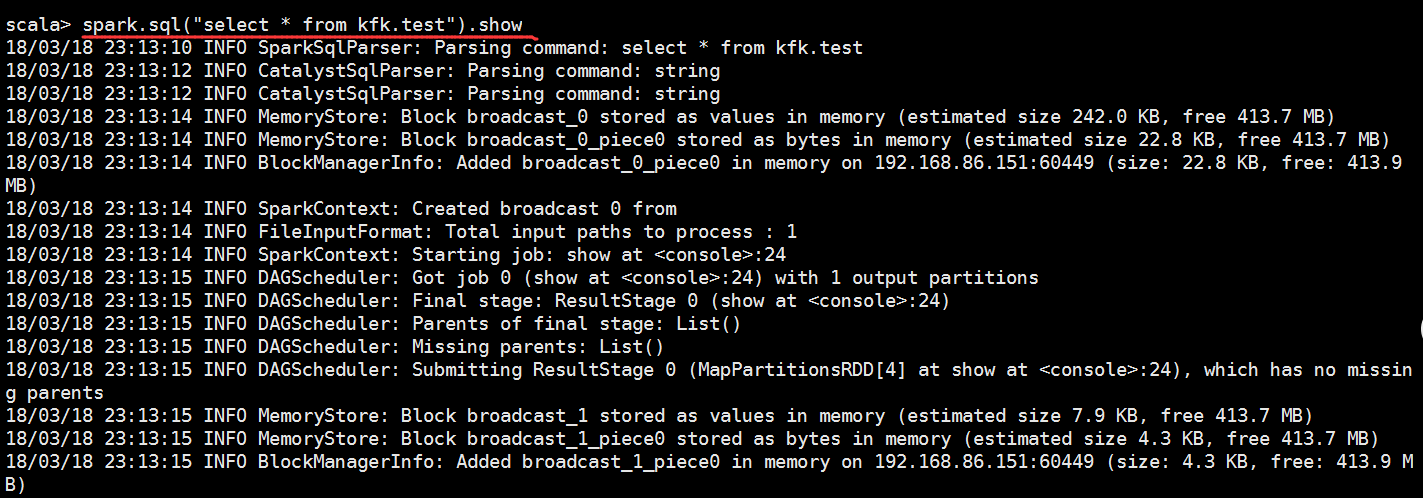

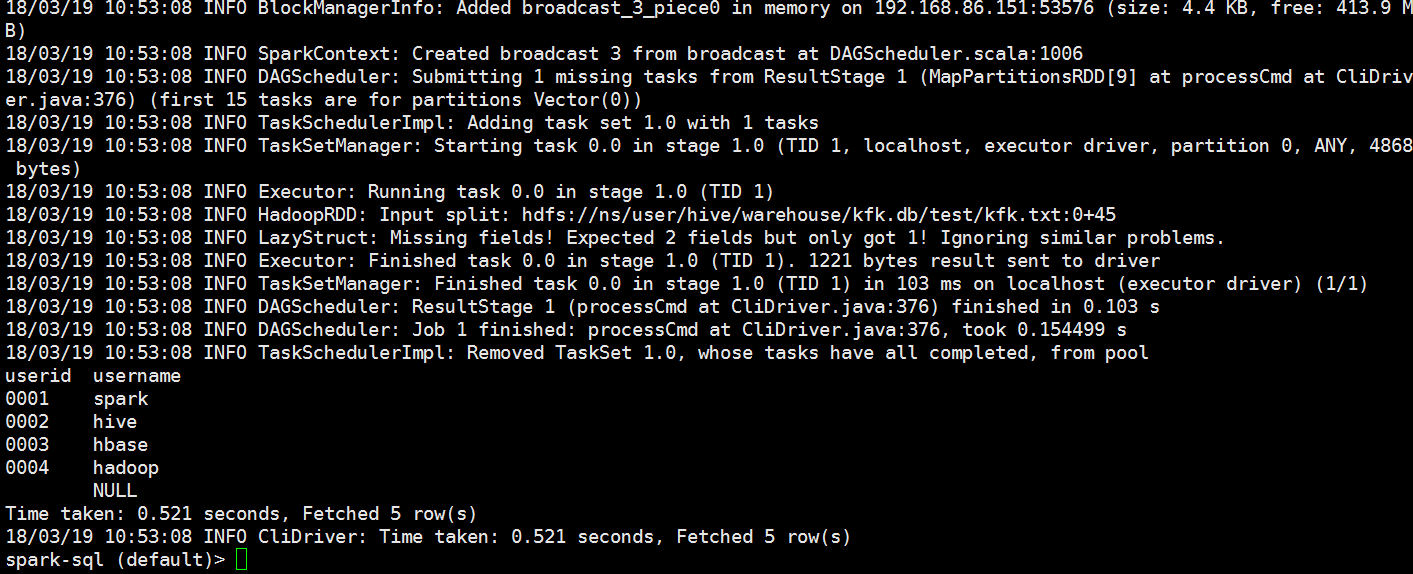
数据拿到了,说明我们的sparkSQL和hive集成是没有问题的
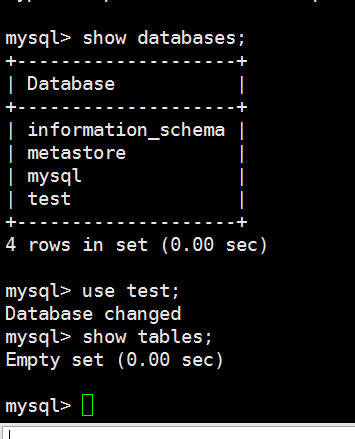
[kfk@bigdata-pro01 ~]$ mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 98 Server version: 5.1.73 Source distribution Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or 'h' for help. Type 'c' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | metastore | | mysql | | test | +--------------------+ 4 rows in set (0.00 sec) mysql> use test; Database changed mysql> show tables; Empty set (0.00 sec) mysql>


scala> val df=spark.sql("select * from kfk.test") 18/03/19 09:30:53 INFO SparkSqlParser: Parsing command: select * from kfk.test 18/03/19 09:30:53 INFO CatalystSqlParser: Parsing command: string 18/03/19 09:30:53 INFO CatalystSqlParser: Parsing command: string df: org.apache.spark.sql.DataFrame = [userid: string, username: string] scala> import java.util.Properties import java.util.Properties scala> val pro = new Properties() pro: java.util.Properties = {} scala> pro.setProperty("driver","com.mysql.jdbc.Driver") res1: Object = null scala> df.write.jdbc("jdbc:mysql://bigdata-pro01.kfk.com/test?user=root&password=root","spark1",pro) 18/03/19 09:55:31 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 242.0 KB, free 413.7 MB) 18/03/19 09:55:31 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 22.8 KB, free 413.7 MB) 18/03/19 09:55:31 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.86.151:34699 (size: 22.8 KB, free: 413.9 MB) 18/03/19 09:55:31 INFO SparkContext: Created broadcast 0 from 18/03/19 09:55:32 INFO FileInputFormat: Total input paths to process : 1 18/03/19 09:55:32 INFO SparkContext: Starting job: jdbc at <console>:29 18/03/19 09:55:32 INFO DAGScheduler: Got job 0 (jdbc at <console>:29) with 1 output partitions 18/03/19 09:55:32 INFO DAGScheduler: Final stage: ResultStage 0 (jdbc at <console>:29) 18/03/19 09:55:32 INFO DAGScheduler: Parents of final stage: List() 18/03/19 09:55:32 INFO DAGScheduler: Missing parents: List() 18/03/19 09:55:32 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[5] at jdbc at <console>:29), which has no missing parents 18/03/19 09:55:32 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 13.3 KB, free 413.7 MB) 18/03/19 09:55:32 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 7.2 KB, free 413.6 MB) 18/03/19 09:55:32 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.86.151:34699 (size: 7.2 KB, free: 413.9 MB) 18/03/19 09:55:32 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1006 18/03/19 09:55:33 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[5] at jdbc at <console>:29) (first 15 tasks are for partitions Vector(0)) 18/03/19 09:55:33 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks 18/03/19 09:55:33 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, ANY, 4868 bytes) 18/03/19 09:55:33 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 18/03/19 09:55:33 INFO HadoopRDD: Input split: hdfs://ns/user/hive/warehouse/kfk.db/test/kfk.txt:0+45 18/03/19 09:55:35 INFO TransportClientFactory: Successfully created connection to /192.168.86.151:40256 after 93 ms (0 ms spent in bootstraps) 18/03/19 09:55:35 INFO CodeGenerator: Code generated in 1278.378936 ms 18/03/19 09:55:35 INFO CodeGenerator: Code generated in 63.186243 ms 18/03/19 09:55:35 INFO LazyStruct: Missing fields! Expected 2 fields but only got 1! Ignoring similar problems. 18/03/19 09:55:35 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1142 bytes result sent to driver 18/03/19 09:55:35 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 2692 ms on localhost (executor driver) (1/1) 18/03/19 09:55:35 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 18/03/19 09:55:35 INFO DAGScheduler: ResultStage 0 (jdbc at <console>:29) finished in 2.764 s 18/03/19 09:55:35 INFO DAGScheduler: Job 0 finished: jdbc at <console>:29, took 3.546682 s scala>
在mysql里面我们可以看到多了一个表



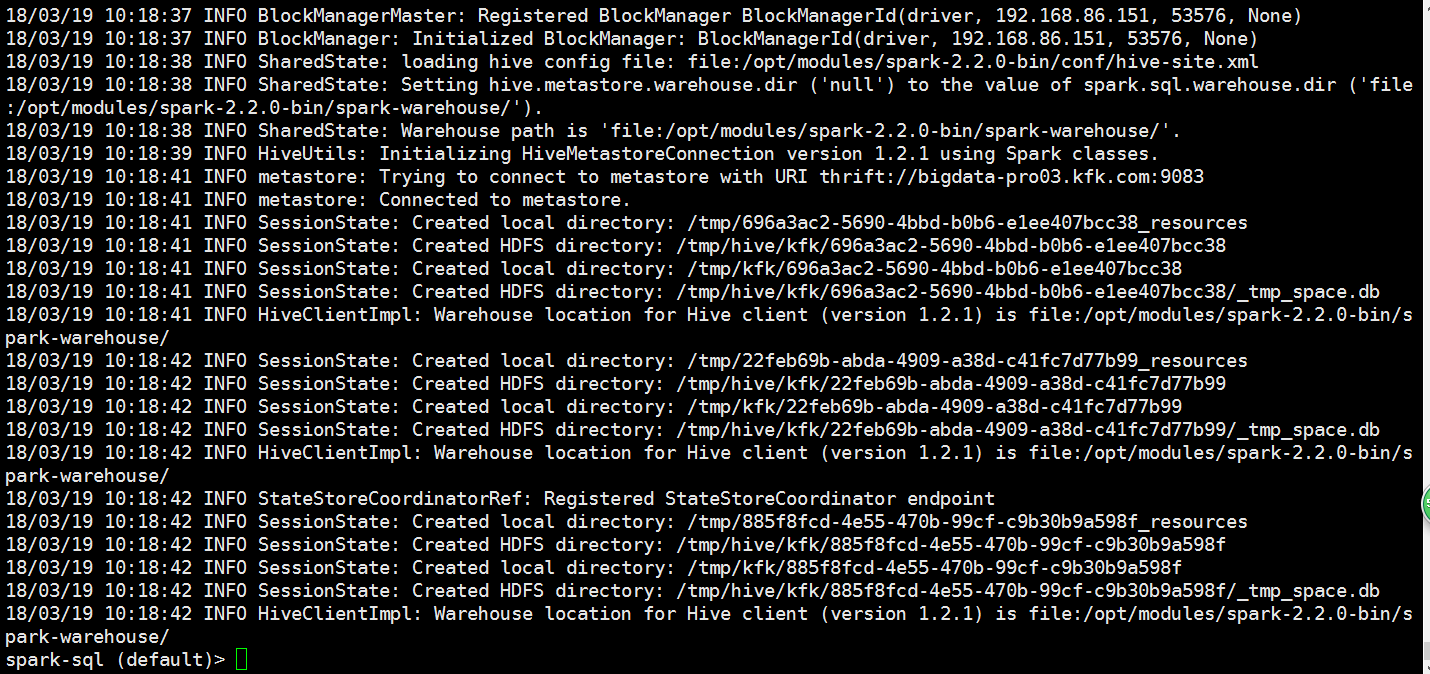
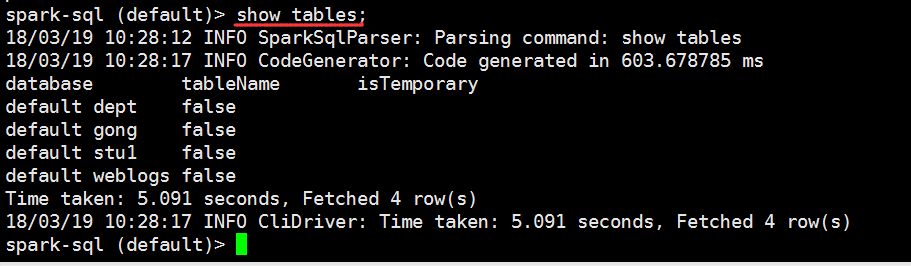
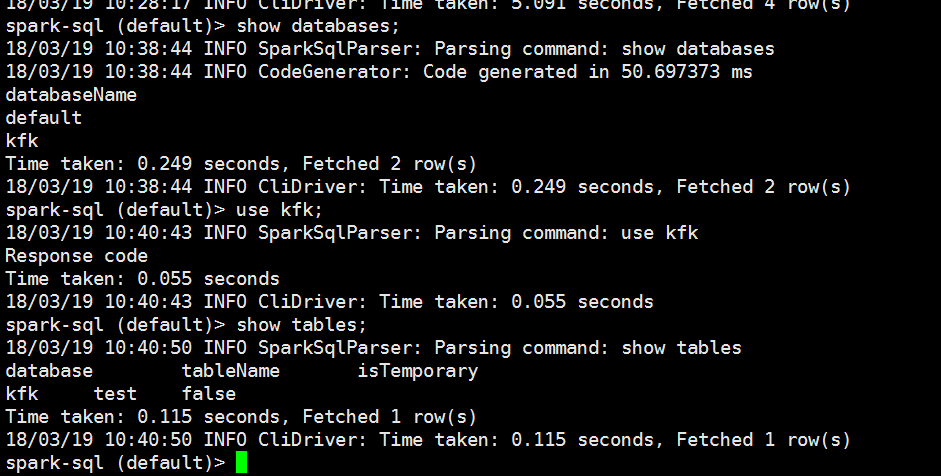
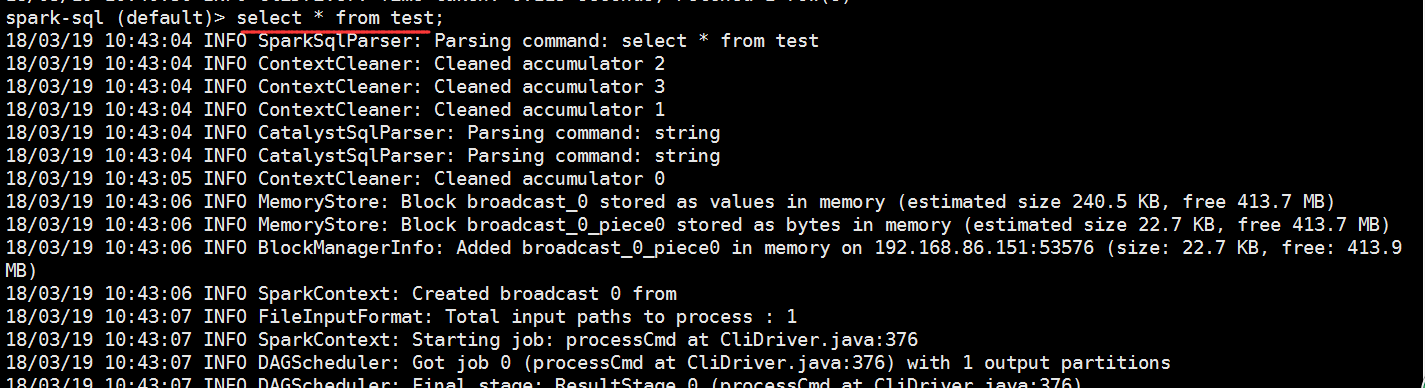

我们再启动一下spark-shell


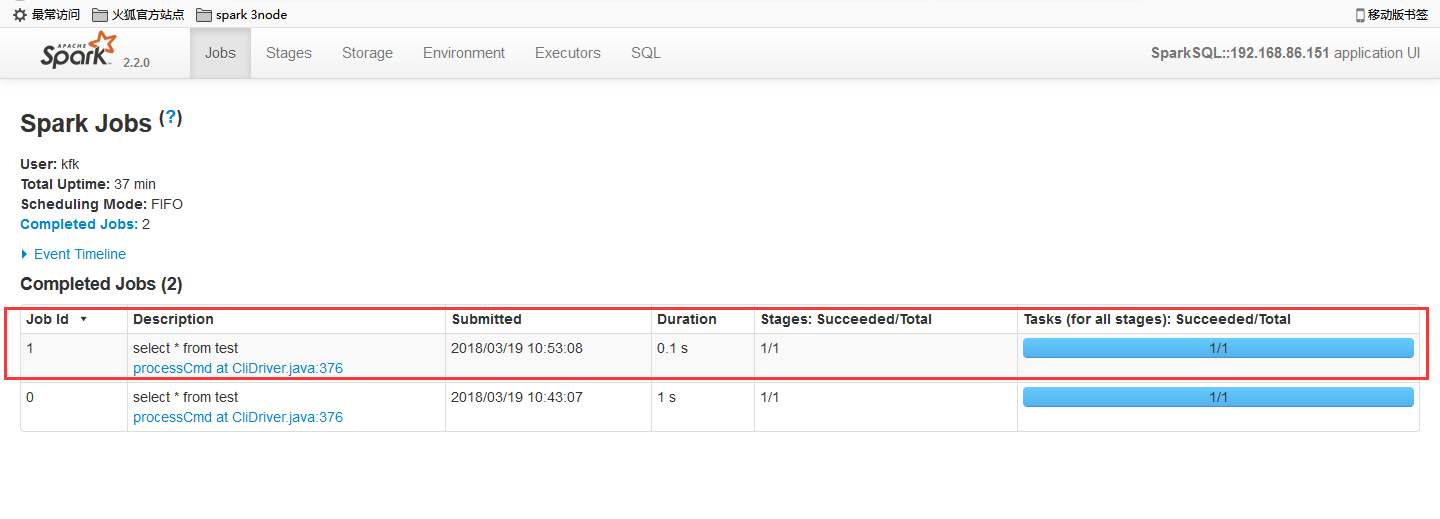
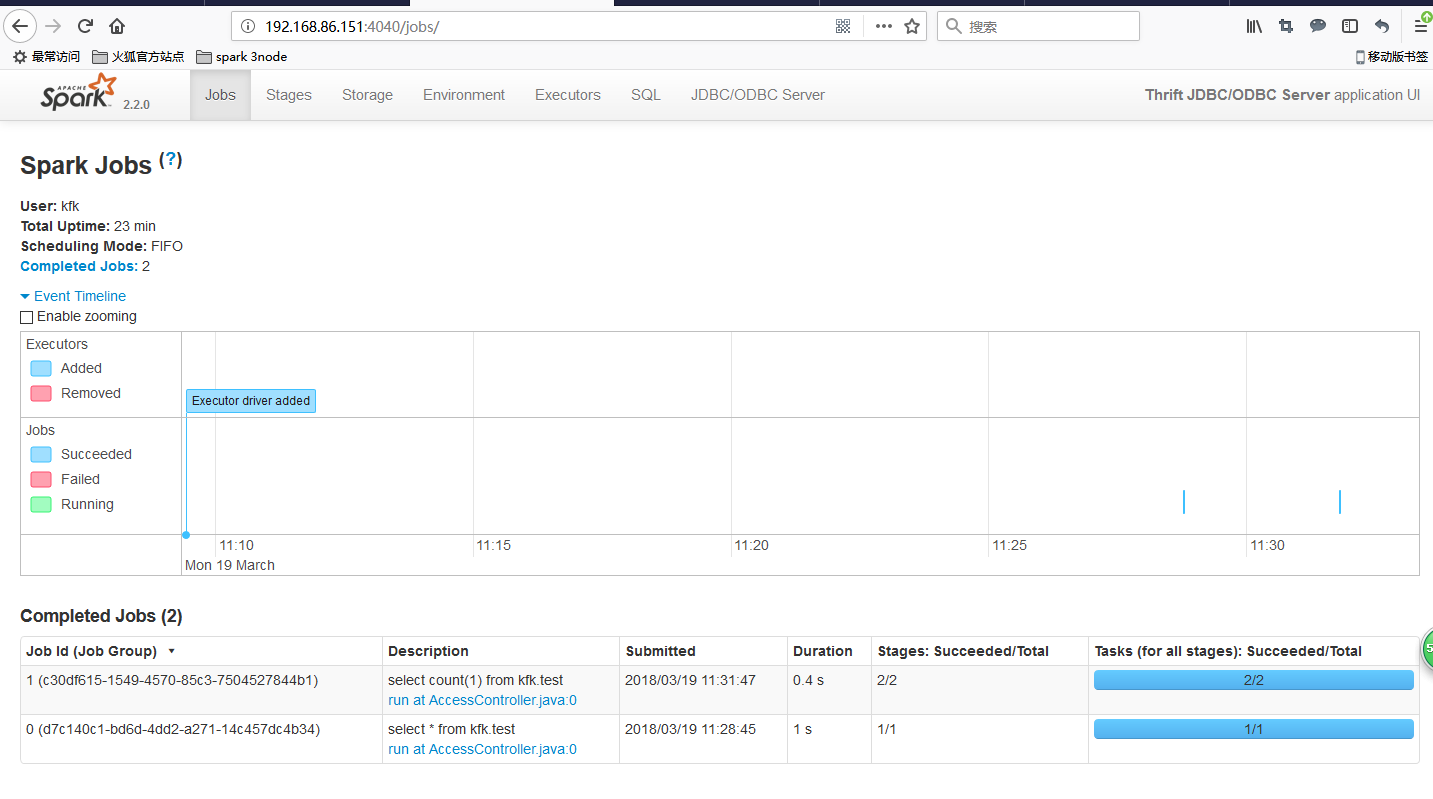
下面这个监控页面是spark-sql的

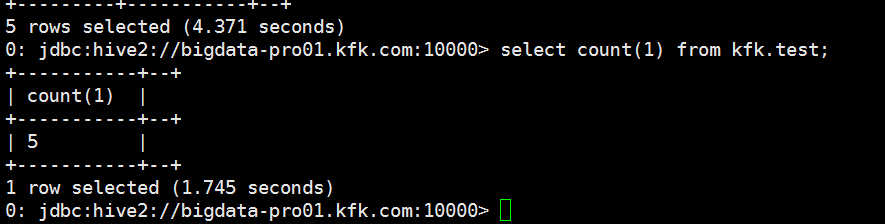
我们在spark-sql做以下操作

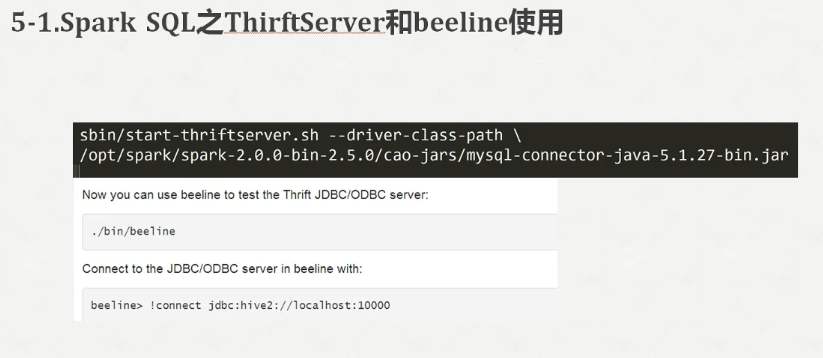
启动spark-thriftserver

输入的是当前的机器的用户名和密码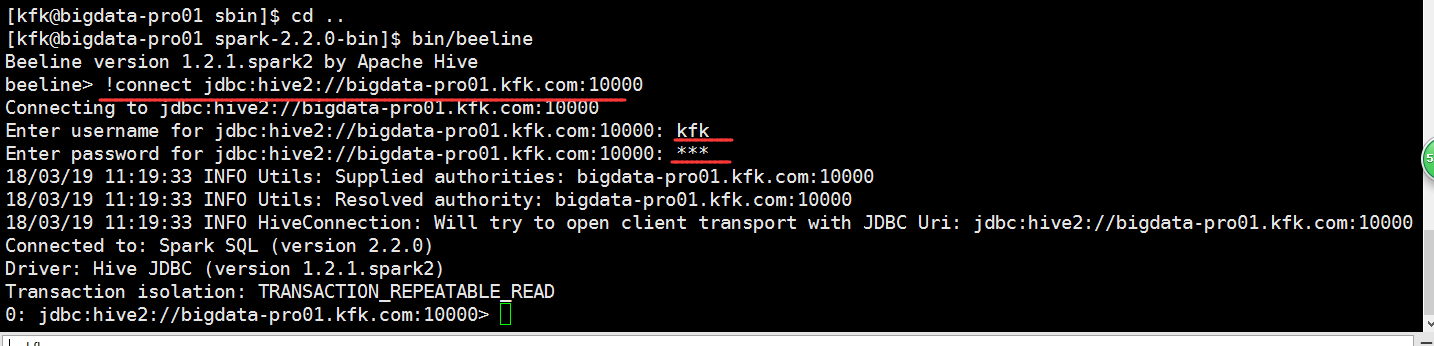
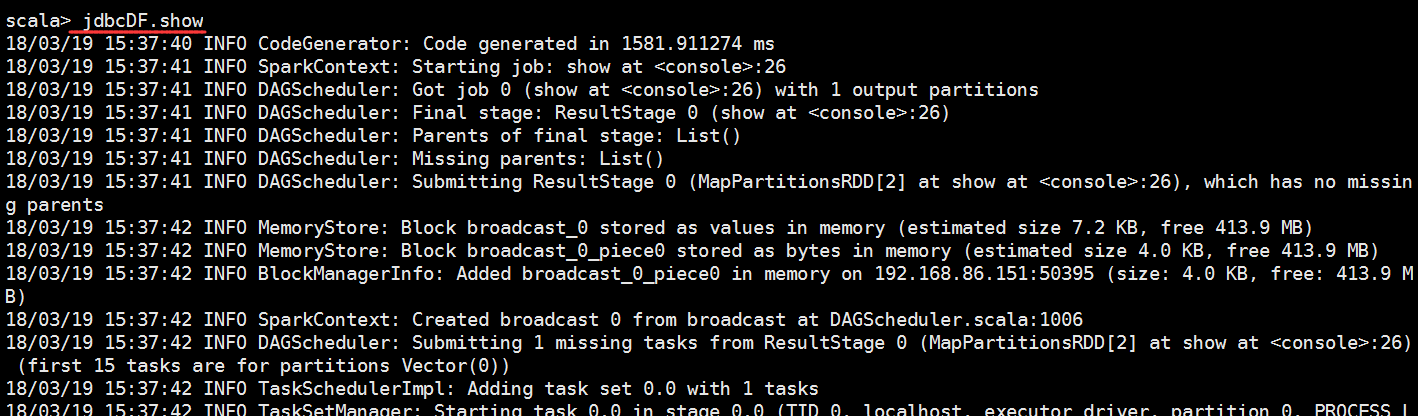
启动spark-shell


val jdbcDF=spark.read.format("jdbc").option("url","jdbc:mysql://bigdata-pro01.kfk.com:3306/test").option("dbtable","spark1").option("user","root").option("password","root").load()


因为需要hive1.2.1版本的包,所以我们需要下载一个hive1.2.1版本下来把里面的包取出来
这个就是我下载的hive1.2.1,下载地址http://archive.apache.org/dist/hive/hive-1.2.1/
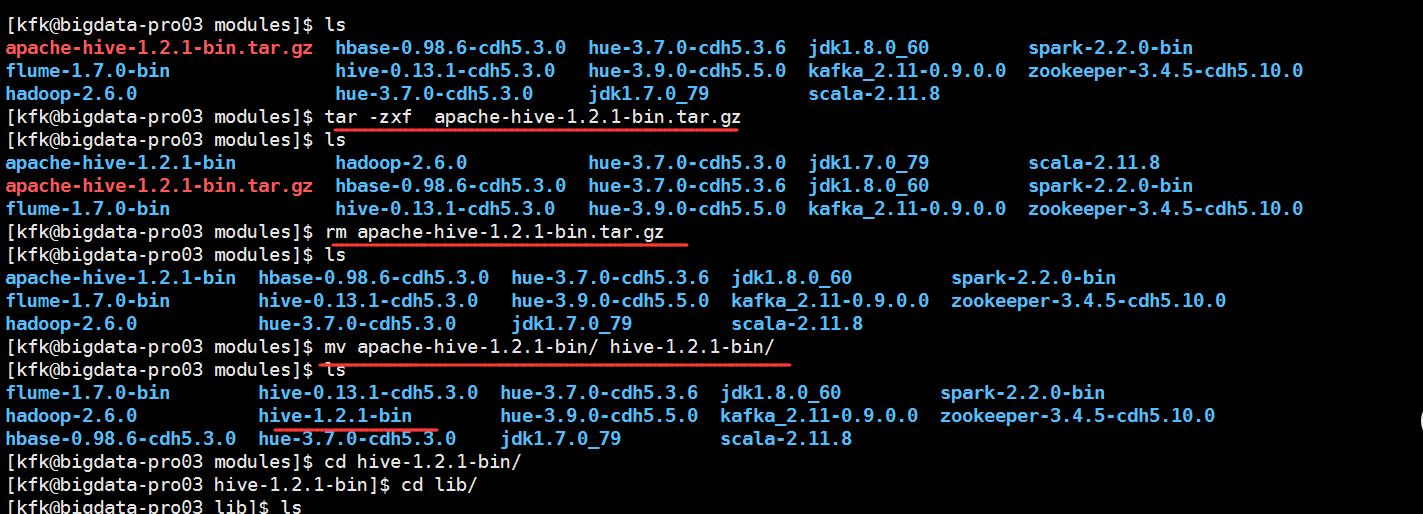
我把所有包都准备好了
把这些包都上传到spark的jar目录下(3个节点都这样做)
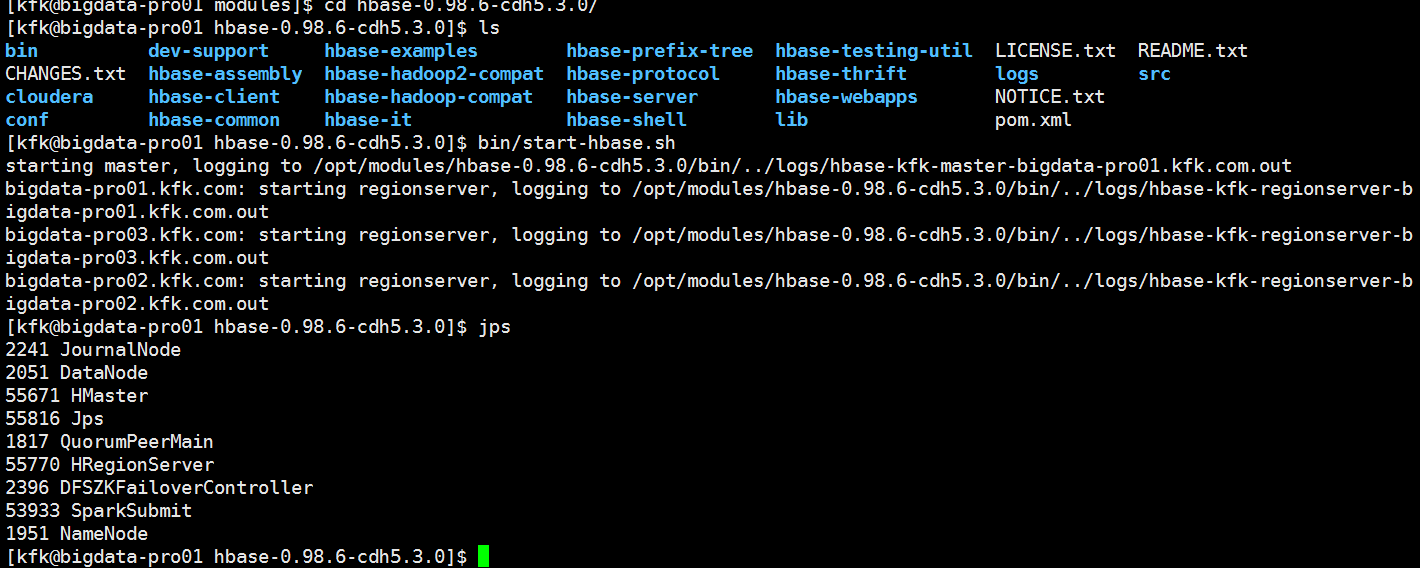
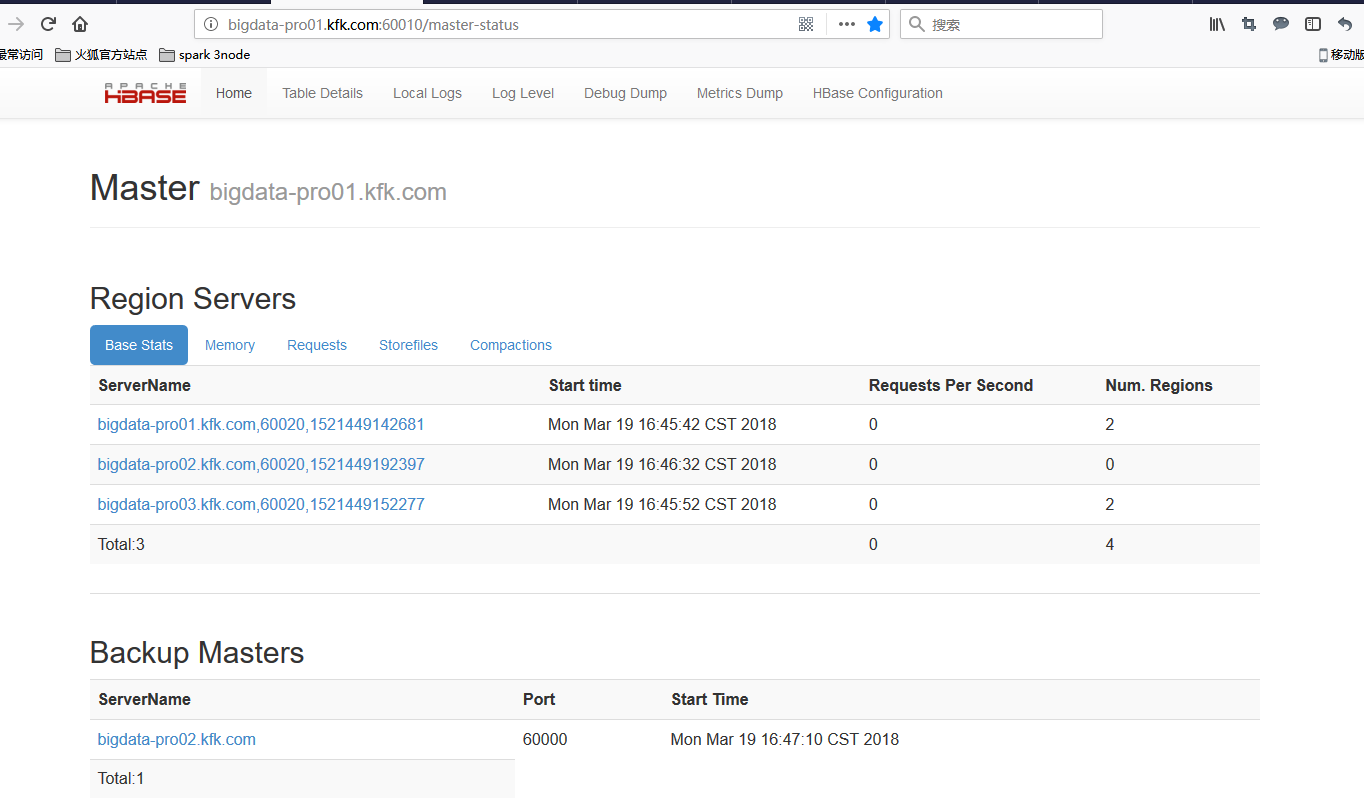
启动我们的hbase
再启动之前我们先修改一下jdk版本,原来我们用的是1.7,现在我们修改成1.8的(3个节点都修改)


现在启动我们的hive

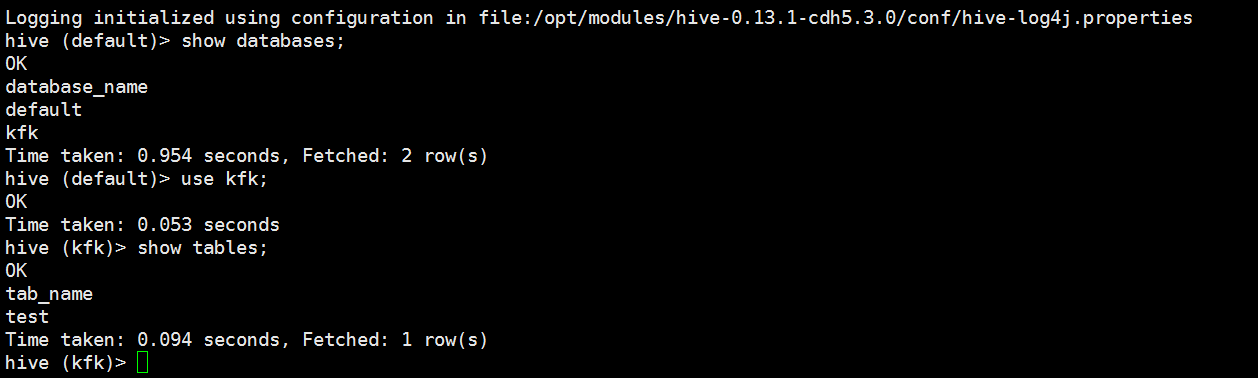
启动spark-shell

可以看到报错了
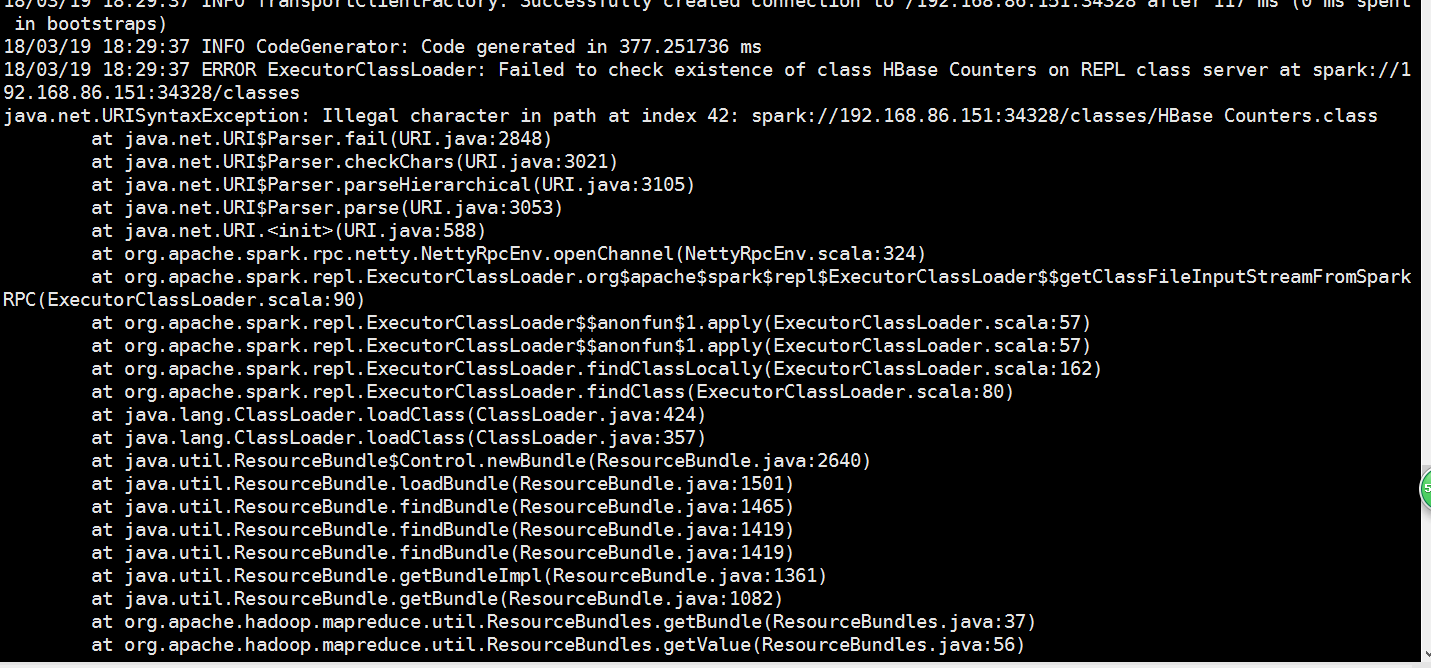
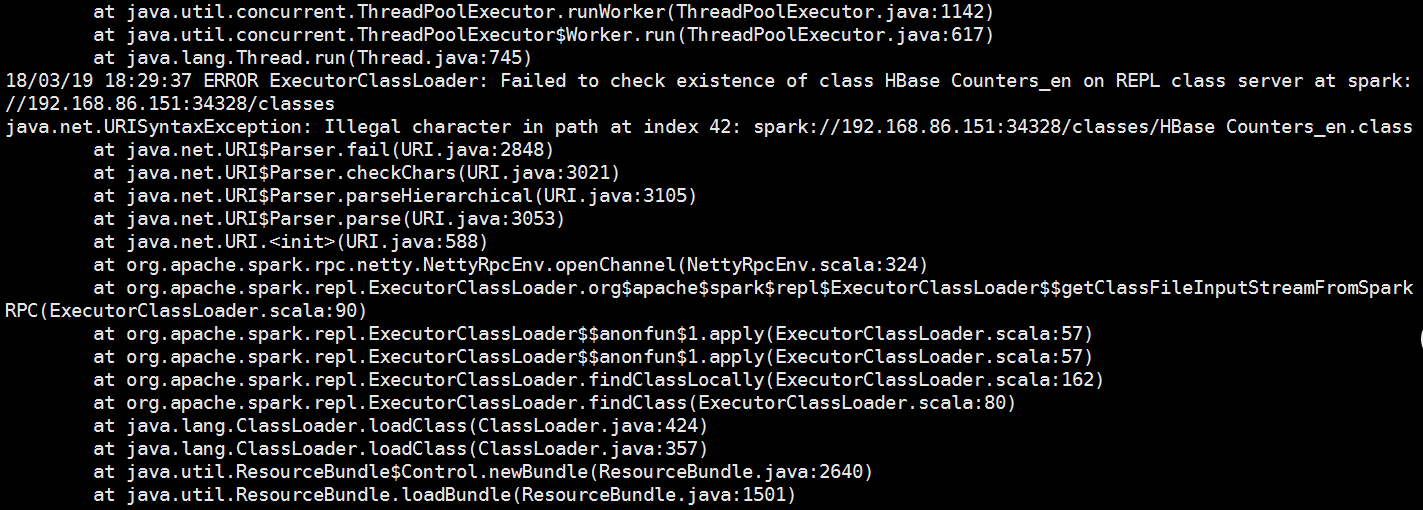
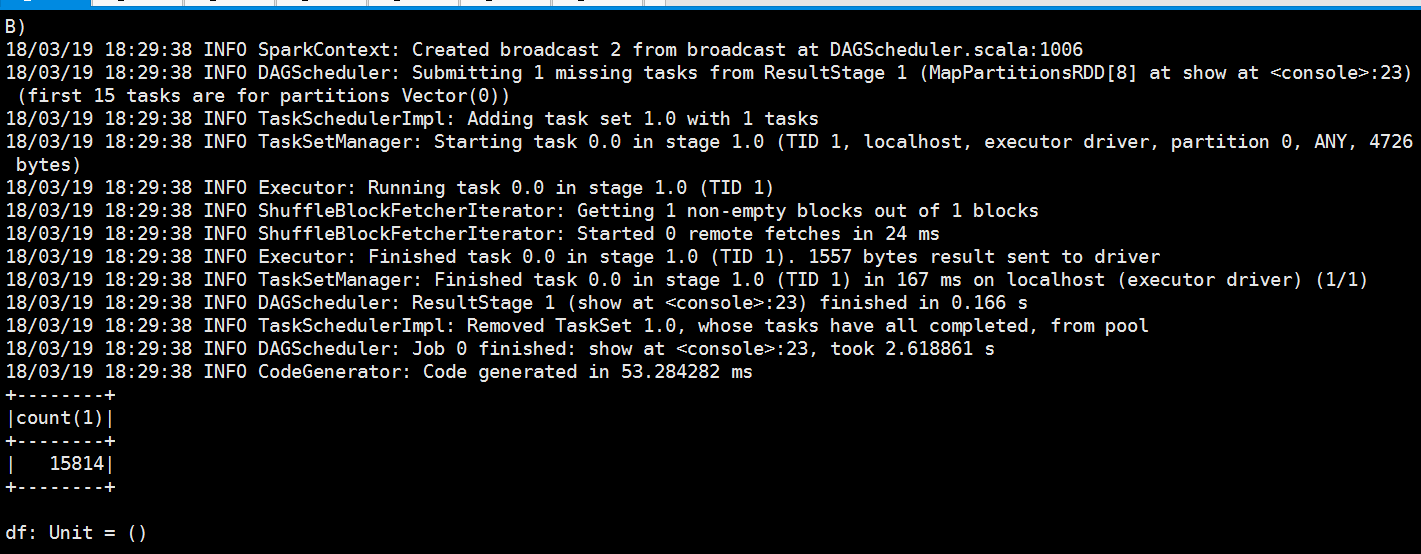
是因为我们的表数据太多了
我们县直一下条数


scala> val df =spark.sql("select count(1) from weblogs").show 18/03/19 18:29:27 INFO SparkSqlParser: Parsing command: select count(1) from weblogs 18/03/19 18:29:28 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:28 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:28 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:28 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:28 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:28 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:28 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:31 INFO CodeGenerator: Code generated in 607.706437 ms 18/03/19 18:29:31 INFO CodeGenerator: Code generated in 72.215236 ms 18/03/19 18:29:31 INFO ContextCleaner: Cleaned accumulator 0 18/03/19 18:29:32 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 242.1 KB, free 413.7 MB) 18/03/19 18:29:32 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 22.9 KB, free 413.7 MB) 18/03/19 18:29:32 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.86.151:42725 (size: 22.9 KB, free: 413.9 MB) 18/03/19 18:29:32 INFO SparkContext: Created broadcast 0 from 18/03/19 18:29:33 INFO HBaseStorageHandler: Configuring input job properties 18/03/19 18:29:33 INFO RecoverableZooKeeper: Process identifier=hconnection-0x490dfe25 connecting to ZooKeeper ensemble=bigdata-pro02.kfk.com:2181,bigdata-pro01.kfk.com:2181,bigdata-pro03.kfk.com:2181 18/03/19 18:29:33 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 18/03/19 18:29:33 INFO ZooKeeper: Client environment:host.name=bigdata-pro01.kfk.com 18/03/19 18:29:33 INFO ZooKeeper: Client environment:java.version=1.8.0_60 18/03/19 18:29:33 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation 18/03/19 18:29:33 INFO ZooKeeper: Client environment:java.home=/opt/modules/jdk1.8.0_60/jre 18/03/19 18:29:33 INFO ZooKeeper: Client environment:java.class.path=/opt/modules/spark-2.2.0-bin/conf/:/opt/modules/spark-2.2.0-bin/jars/htrace-core-3.0.4.jar:/opt/modules/spark-2.2.0-bin/jars/jpam-1.1.jar:/opt/modules/spark-2.2.0-bin/jars/mysql-connector-java-5.1.27-bin.jar:/opt/modules/spark-2.2.0-bin/jars/snappy-java-1.1.2.6.jar:/opt/modules/spark-2.2.0-bin/jars/commons-compress-1.4.1.jar:/opt/modules/spark-2.2.0-bin/jars/hbase-server-0.98.6-cdh5.3.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-sql_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-client-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/jetty-6.1.26.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-databind-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/javolution-5.5.1.jar:/opt/modules/spark-2.2.0-bin/jars/opencsv-2.3.jar:/opt/modules/spark-2.2.0-bin/jars/curator-framework-2.6.0.jar:/opt/modules/spark-2.2.0-bin/jars/commons-collections-3.2.2.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-mapreduce-client-jobclient-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/hk2-utils-2.4.0-b34.jar:/opt/modules/spark-2.2.0-bin/jars/metrics-graphite-3.1.2.jar:/opt/modules/spark-2.2.0-bin/jars/pmml-model-1.2.15.jar:/opt/modules/spark-2.2.0-bin/jars/compress-lzf-1.0.3.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-mapreduce-client-app-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-encoding-1.8.2.jar:/opt/modules/spark-2.2.0-bin/jars/xz-1.0.jar:/opt/modules/spark-2.2.0-bin/jars/datanucleus-core-3.2.10.jar:/opt/modules/spark-2.2.0-bin/jars/guice-servlet-3.0.jar:/opt/modules/spark-2.2.0-bin/jars/stax-api-1.0-2.jar:/opt/modules/spark-2.2.0-bin/jars/eigenbase-properties-1.1.5.jar:/opt/modules/spark-2.2.0-bin/jars/metrics-jvm-3.1.2.jar:/opt/modules/spark-2.2.0-bin/jars/stream-2.7.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-mllib-local_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/derby-10.12.1.1.jar:/opt/modules/spark-2.2.0-bin/jars/joda-time-2.9.3.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-common-1.8.2.jar:/opt/modules/spark-2.2.0-bin/jars/ivy-2.4.0.jar:/opt/modules/spark-2.2.0-bin/jars/slf4j-api-1.7.16.jar:/opt/modules/spark-2.2.0-bin/jars/jetty-util-6.1.26.jar:/opt/modules/spark-2.2.0-bin/jars/shapeless_2.11-2.3.2.jar:/opt/modules/spark-2.2.0-bin/jars/activation-1.1.1.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-module-scala_2.11-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/libthrift-0.9.3.jar:/opt/modules/spark-2.2.0-bin/jars/log4j-1.2.17.jar:/opt/modules/spark-2.2.0-bin/jars/antlr4-runtime-4.5.3.jar:/opt/modules/spark-2.2.0-bin/jars/chill-java-0.8.0.jar:/opt/modules/spark-2.2.0-bin/jars/snappy-0.2.jar:/opt/modules/spark-2.2.0-bin/jars/core-1.1.2.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-annotations-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-container-servlet-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/spark-network-shuffle_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-graphx_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/breeze_2.11-0.13.1.jar:/opt/modules/spark-2.2.0-bin/jars/scala-compiler-2.11.8.jar:/opt/modules/spark-2.2.0-bin/jars/aopalliance-1.0.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-mapreduce-client-common-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/aopalliance-repackaged-2.4.0-b34.jar:/opt/modules/spark-2.2.0-bin/jars/commons-beanutils-core-1.8.0.jar:/opt/modules/spark-2.2.0-bin/jars/jsr305-1.3.9.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-yarn-common-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/osgi-resource-locator-1.0.1.jar:/opt/modules/spark-2.2.0-bin/jars/univocity-parsers-2.2.1.jar:/opt/modules/spark-2.2.0-bin/jars/hive-exec-1.2.1.spark2.jar:/opt/modules/spark-2.2.0-bin/jars/commons-crypto-1.0.0.jar:/opt/modules/spark-2.2.0-bin/jars/metrics-json-3.1.2.jar:/opt/modules/spark-2.2.0-bin/jars/minlog-1.3.0.jar:/opt/modules/spark-2.2.0-bin/jars/JavaEWAH-0.3.2.jar:/opt/modules/spark-2.2.0-bin/jars/json4s-jackson_2.11-3.2.11.jar:/opt/modules/spark-2.2.0-bin/jars/javax.ws.rs-api-2.0.1.jar:/opt/modules/spark-2.2.0-bin/jars/commons-dbcp-1.4.jar:/opt/modules/spark-2.2.0-bin/jars/slf4j-log4j12-1.7.16.jar:/opt/modules/spark-2.2.0-bin/jars/javax.inject-2.4.0-b34.jar:/opt/modules/spark-2.2.0-bin/jars/scala-xml_2.11-1.0.2.jar:/opt/modules/spark-2.2.0-bin/jars/commons-pool-1.5.4.jar:/opt/modules/spark-2.2.0-bin/jars/jaxb-api-2.2.2.jar:/opt/modules/spark-2.2.0-bin/jars/spark-network-common_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/gson-2.2.4.jar:/opt/modules/spark-2.2.0-bin/jars/protobuf-java-2.5.0.jar:/opt/modules/spark-2.2.0-bin/jars/objenesis-2.1.jar:/opt/modules/spark-2.2.0-bin/jars/hive-metastore-1.2.1.spark2.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-container-servlet-core-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/stax-api-1.0.1.jar:/opt/modules/spark-2.2.0-bin/jars/super-csv-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/metrics-core-3.1.2.jar:/opt/modules/spark-2.2.0-bin/jars/scala-parser-combinators_2.11-1.0.4.jar:/opt/modules/spark-2.2.0-bin/jars/apacheds-i18n-2.0.0-M15.jar:/opt/modules/spark-2.2.0-bin/jars/spire_2.11-0.13.0.jar:/opt/modules/spark-2.2.0-bin/jars/xbean-asm5-shaded-4.4.jar:/opt/modules/spark-2.2.0-bin/jars/httpclient-4.5.2.jar:/opt/modules/spark-2.2.0-bin/jars/hive-beeline-1.2.1.spark2.jar:/opt/modules/spark-2.2.0-bin/jars/janino-3.0.0.jar:/opt/modules/spark-2.2.0-bin/jars/commons-beanutils-1.7.0.jar:/opt/modules/spark-2.2.0-bin/jars/javax.annotation-api-1.2.jar:/opt/modules/spark-2.2.0-bin/jars/curator-recipes-2.6.0.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-core-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/paranamer-2.6.jar:/opt/modules/spark-2.2.0-bin/jars/hk2-locator-2.4.0-b34.jar:/opt/modules/spark-2.2.0-bin/jars/spark-hive_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/bonecp-0.8.0.RELEASE.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-column-1.8.2.jar:/opt/modules/spark-2.2.0-bin/jars/calcite-linq4j-1.2.0-incubating.jar:/opt/modules/spark-2.2.0-bin/jars/commons-cli-1.2.jar:/opt/modules/spark-2.2.0-bin/jars/javax.inject-1.jar:/opt/modules/spark-2.2.0-bin/jars/hbase-common-0.98.6-cdh5.3.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-tags_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/bcprov-jdk15on-1.51.jar:/opt/modules/spark-2.2.0-bin/jars/stringtemplate-3.2.1.jar:/opt/modules/spark-2.2.0-bin/jars/RoaringBitmap-0.5.11.jar:/opt/modules/spark-2.2.0-bin/jars/hbase-client-0.98.6-cdh5.3.0.jar:/opt/modules/spark-2.2.0-bin/jars/commons-codec-1.10.jar:/opt/modules/spark-2.2.0-bin/jars/hive-cli-1.2.1.spark2.jar:/opt/modules/spark-2.2.0-bin/jars/scala-reflect-2.11.8.jar:/opt/modules/spark-2.2.0-bin/jars/jline-2.12.1.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-core-asl-1.9.13.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-server-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/xercesImpl-2.9.1.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-format-2.3.1.jar:/opt/modules/spark-2.2.0-bin/jars/jdo-api-3.0.1.jar:/opt/modules/spark-2.2.0-bin/jars/commons-lang-2.6.jar:/opt/modules/spark-2.2.0-bin/jars/jta-1.1.jar:/opt/modules/spark-2.2.0-bin/jars/commons-httpclient-3.1.jar:/opt/modules/spark-2.2.0-bin/jars/pyrolite-4.13.jar:/opt/modules/spark-2.2.0-bin/jars/jul-to-slf4j-1.7.16.jar:/opt/modules/spark-2.2.0-bin/jars/api-util-1.0.0-M20.jar:/opt/modules/spark-2.2.0-bin/jars/hive-hbase-handler-1.2.1.jar:/opt/modules/spark-2.2.0-bin/jars/commons-math3-3.4.1.jar:/opt/modules/spark-2.2.0-bin/jars/jets3t-0.9.3.jar:/opt/modules/spark-2.2.0-bin/jars/spark-catalyst_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-jackson-1.8.2.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-annotations-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-yarn-server-web-proxy-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/spark-hive-thriftserver_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-hadoop-1.8.2.jar:/opt/modules/spark-2.2.0-bin/jars/apacheds-kerberos-codec-2.0.0-M15.jar:/opt/modules/spark-2.2.0-bin/jars/ST4-4.0.4.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-mapper-asl-1.9.13.jar:/opt/modules/spark-2.2.0-bin/jars/machinist_2.11-0.6.1.jar:/opt/modules/spark-2.2.0-bin/jars/spark-mllib_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/scala-library-2.11.8.jar:/opt/modules/spark-2.2.0-bin/jars/guava-14.0.1.jar:/opt/modules/spark-2.2.0-bin/jars/javassist-3.18.1-GA.jar:/opt/modules/spark-2.2.0-bin/jars/api-asn1-api-1.0.0-M20.jar:/opt/modules/spark-2.2.0-bin/jars/antlr-2.7.7.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-module-paranamer-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/curator-client-2.6.0.jar:/opt/modules/spark-2.2.0-bin/jars/arpack_combined_all-0.1.jar:/opt/modules/spark-2.2.0-bin/jars/datanucleus-api-jdo-3.2.6.jar:/opt/modules/spark-2.2.0-bin/jars/calcite-avatica-1.2.0-incubating.jar:/opt/modules/spark-2.2.0-bin/jars/avro-mapred-1.7.7-hadoop2.jar:/opt/modules/spark-2.2.0-bin/jars/hive-jdbc-1.2.1.spark2.jar:/opt/modules/spark-2.2.0-bin/jars/breeze-macros_2.11-0.13.1.jar:/opt/modules/spark-2.2.0-bin/jars/hbase-protocol-0.98.6-cdh5.3.0.jar:/opt/modules/spark-2.2.0-bin/jars/json4s-core_2.11-3.2.11.jar:/opt/modules/spark-2.2.0-bin/jars/spire-macros_2.11-0.13.0.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-client-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/mx4j-3.0.2.jar:/opt/modules/spark-2.2.0-bin/jars/py4j-0.10.4.jar:/opt/modules/spark-2.2.0-bin/jars/scalap-2.11.8.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-guava-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-media-jaxb-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/commons-configuration-1.6.jar:/opt/modules/spark-2.2.0-bin/jars/json4s-ast_2.11-3.2.11.jar:/opt/modules/spark-2.2.0-bin/jars/htrace-core-2.04.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-common-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/kryo-shaded-3.0.3.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-auth-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/commons-compiler-3.0.0.jar:/opt/modules/spark-2.2.0-bin/jars/jtransforms-2.4.0.jar:/opt/modules/spark-2.2.0-bin/jars/commons-net-2.2.jar:/opt/modules/spark-2.2.0-bin/jars/jcl-over-slf4j-1.7.16.jar:/opt/modules/spark-2.2.0-bin/jars/spark-launcher_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-core_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/antlr-runtime-3.4.jar:/opt/modules/spark-2.2.0-bin/jars/spark-repl_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-streaming_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/datanucleus-rdbms-3.2.9.jar:/opt/modules/spark-2.2.0-bin/jars/netty-3.9.9.Final.jar:/opt/modules/spark-2.2.0-bin/jars/lz4-1.3.0.jar:/opt/modules/spark-2.2.0-bin/jars/zookeeper-3.4.6.jar:/opt/modules/spark-2.2.0-bin/jars/java-xmlbuilder-1.0.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-common-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/netty-all-4.0.43.Final.jar:/opt/modules/spark-2.2.0-bin/jars/validation-api-1.1.0.Final.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-mapreduce-client-core-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/avro-ipc-1.7.7.jar:/opt/modules/spark-2.2.0-bin/jars/jodd-core-3.5.2.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-xc-1.9.13.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-yarn-client-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/guice-3.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-yarn_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-hadoop-bundle-1.6.0.jar:/opt/modules/spark-2.2.0-bin/jars/leveldbjni-all-1.8.jar:/opt/modules/spark-2.2.0-bin/jars/hk2-api-2.4.0-b34.jar:/opt/modules/spark-2.2.0-bin/jars/javax.servlet-api-3.1.0.jar:/opt/modules/spark-2.2.0-bin/jars/mysql-connector-java-5.1.27.jar:/opt/modules/spark-2.2.0-bin/jars/libfb303-0.9.3.jar:/opt/modules/spark-2.2.0-bin/jars/httpcore-4.4.4.jar:/opt/modules/spark-2.2.0-bin/jars/chill_2.11-0.8.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-sketch_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/commons-lang3-3.5.jar:/opt/modules/spark-2.2.0-bin/jars/mail-1.4.7.jar:/opt/modules/spark-2.2.0-bin/jars/apache-log4j-extras-1.2.17.jar:/opt/modules/spark-2.2.0-bin/jars/xmlenc-0.52.jar:/opt/modules/spark-2.2.0-bin/jars/avro-1.7.7.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-yarn-server-common-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-yarn-api-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-hdfs-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/pmml-schema-1.2.15.jar:/opt/modules/spark-2.2.0-bin/jars/calcite-core-1.2.0-incubating.jar:/opt/modules/spark-2.2.0-bin/jars/spark-unsafe_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/base64-2.3.8.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-jaxrs-1.9.13.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-mapreduce-client-shuffle-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/oro-2.0.8.jar:/opt/modules/spark-2.2.0-bin/jars/commons-digester-1.8.jar:/opt/modules/spark-2.2.0-bin/jars/commons-io-2.4.jar:/opt/modules/spark-2.2.0-bin/jars/commons-logging-1.1.3.jar:/opt/modules/spark-2.2.0-bin/jars/macro-compat_2.11-1.1.1.jar:/opt/modules/hadoop-2.6.0/etc/hadoop/ 18/03/19 18:29:33 INFO ZooKeeper: Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib 18/03/19 18:29:33 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp 18/03/19 18:29:33 INFO ZooKeeper: Client environment:java.compiler=<NA> 18/03/19 18:29:33 INFO ZooKeeper: Client environment:os.name=Linux 18/03/19 18:29:33 INFO ZooKeeper: Client environment:os.arch=amd64 18/03/19 18:29:33 INFO ZooKeeper: Client environment:os.version=2.6.32-431.el6.x86_64 18/03/19 18:29:33 INFO ZooKeeper: Client environment:user.name=kfk 18/03/19 18:29:33 INFO ZooKeeper: Client environment:user.home=/home/kfk 18/03/19 18:29:33 INFO ZooKeeper: Client environment:user.dir=/opt/modules/spark-2.2.0-bin 18/03/19 18:29:33 INFO ZooKeeper: Initiating client connection, connectString=bigdata-pro02.kfk.com:2181,bigdata-pro01.kfk.com:2181,bigdata-pro03.kfk.com:2181 sessionTimeout=90000 watcher=hconnection-0x490dfe25, quorum=bigdata-pro02.kfk.com:2181,bigdata-pro01.kfk.com:2181,bigdata-pro03.kfk.com:2181, baseZNode=/hbase 18/03/19 18:29:33 INFO ClientCnxn: Opening socket connection to server bigdata-pro02.kfk.com/192.168.86.152:2181. Will not attempt to authenticate using SASL (unknown error) 18/03/19 18:29:33 INFO ClientCnxn: Socket connection established to bigdata-pro02.kfk.com/192.168.86.152:2181, initiating session 18/03/19 18:29:33 INFO ClientCnxn: Session establishment complete on server bigdata-pro02.kfk.com/192.168.86.152:2181, sessionid = 0x2623d3a0dea0018, negotiated timeout = 40000 18/03/19 18:29:33 INFO RegionSizeCalculator: Calculating region sizes for table "weblogs". 18/03/19 18:29:35 WARN TableInputFormatBase: Cannot resolve the host name for bigdata-pro03.kfk.com/192.168.86.153 because of javax.naming.NameNotFoundException: DNS name not found [response code 3]; remaining name '153.86.168.192.in-addr.arpa' 18/03/19 18:29:35 INFO SparkContext: Starting job: show at <console>:23 18/03/19 18:29:35 INFO DAGScheduler: Registering RDD 5 (show at <console>:23) 18/03/19 18:29:35 INFO DAGScheduler: Got job 0 (show at <console>:23) with 1 output partitions 18/03/19 18:29:35 INFO DAGScheduler: Final stage: ResultStage 1 (show at <console>:23) 18/03/19 18:29:35 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0) 18/03/19 18:29:35 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0) 18/03/19 18:29:35 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[5] at show at <console>:23), which has no missing parents 18/03/19 18:29:36 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 18.9 KB, free 413.6 MB) 18/03/19 18:29:36 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 9.9 KB, free 413.6 MB) 18/03/19 18:29:36 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.86.151:42725 (size: 9.9 KB, free: 413.9 MB) 18/03/19 18:29:36 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1006 18/03/19 18:29:36 INFO DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[5] at show at <console>:23) (first 15 tasks are for partitions Vector(0)) 18/03/19 18:29:36 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks 18/03/19 18:29:36 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, ANY, 4894 bytes) 18/03/19 18:29:36 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 18/03/19 18:29:36 INFO HadoopRDD: Input split: bigdata-pro03.kfk.com:, 18/03/19 18:29:36 INFO TableInputFormatBase: Input split length: 7 M bytes. 18/03/19 18:29:37 INFO TransportClientFactory: Successfully created connection to /192.168.86.151:34328 after 117 ms (0 ms spent in bootstraps) 18/03/19 18:29:37 INFO CodeGenerator: Code generated in 377.251736 ms 18/03/19 18:29:37 ERROR ExecutorClassLoader: Failed to check existence of class HBase Counters on REPL class server at spark://192.168.86.151:34328/classes java.net.URISyntaxException: Illegal character in path at index 42: spark://192.168.86.151:34328/classes/HBase Counters.class at java.net.URI$Parser.fail(URI.java:2848) at java.net.URI$Parser.checkChars(URI.java:3021) at java.net.URI$Parser.parseHierarchical(URI.java:3105) at java.net.URI$Parser.parse(URI.java:3053) at java.net.URI.<init>(URI.java:588) at org.apache.spark.rpc.netty.NettyRpcEnv.openChannel(NettyRpcEnv.scala:324) at org.apache.spark.repl.ExecutorClassLoader.org$apache$spark$repl$ExecutorClassLoader$$getClassFileInputStreamFromSparkRPC(ExecutorClassLoader.scala:90) at org.apache.spark.repl.ExecutorClassLoader$$anonfun$1.apply(ExecutorClassLoader.scala:57) at org.apache.spark.repl.ExecutorClassLoader$$anonfun$1.apply(ExecutorClassLoader.scala:57) at org.apache.spark.repl.ExecutorClassLoader.findClassLocally(ExecutorClassLoader.scala:162) at org.apache.spark.repl.ExecutorClassLoader.findClass(ExecutorClassLoader.scala:80) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at java.util.ResourceBundle$Control.newBundle(ResourceBundle.java:2640) at java.util.ResourceBundle.loadBundle(ResourceBundle.java:1501) at java.util.ResourceBundle.findBundle(ResourceBundle.java:1465) at java.util.ResourceBundle.findBundle(ResourceBundle.java:1419) at java.util.ResourceBundle.findBundle(ResourceBundle.java:1419) at java.util.ResourceBundle.getBundleImpl(ResourceBundle.java:1361) at java.util.ResourceBundle.getBundle(ResourceBundle.java:1082) at org.apache.hadoop.mapreduce.util.ResourceBundles.getBundle(ResourceBundles.java:37) at org.apache.hadoop.mapreduce.util.ResourceBundles.getValue(ResourceBundles.java:56) at org.apache.hadoop.mapreduce.util.ResourceBundles.getCounterGroupName(ResourceBundles.java:77) at org.apache.hadoop.mapreduce.counters.CounterGroupFactory.newGroup(CounterGroupFactory.java:94) at org.apache.hadoop.mapreduce.counters.AbstractCounters.getGroup(AbstractCounters.java:226) at org.apache.hadoop.mapreduce.counters.AbstractCounters.findCounter(AbstractCounters.java:153) at org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl$DummyReporter.getCounter(TaskAttemptContextImpl.java:110) at org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl.getCounter(TaskAttemptContextImpl.java:76) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at org.apache.hadoop.hbase.mapreduce.TableRecordReaderImpl.updateCounters(TableRecordReaderImpl.java:285) at org.apache.hadoop.hbase.mapreduce.TableRecordReaderImpl.updateCounters(TableRecordReaderImpl.java:273) at org.apache.hadoop.hbase.mapreduce.TableRecordReaderImpl.nextKeyValue(TableRecordReaderImpl.java:241) at org.apache.hadoop.hbase.mapreduce.TableRecordReader.nextKeyValue(TableRecordReader.java:138) at org.apache.hadoop.hive.hbase.HiveHBaseTableInputFormat$1.next(HiveHBaseTableInputFormat.java:154) at org.apache.hadoop.hive.hbase.HiveHBaseTableInputFormat$1.next(HiveHBaseTableInputFormat.java:113) at org.apache.spark.rdd.HadoopRDD$$anon$1.getNext(HadoopRDD.scala:266) at org.apache.spark.rdd.HadoopRDD$$anon$1.getNext(HadoopRDD.scala:203) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.agg_doAggregateWithoutKey$(Unknown Source) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8$$anon$1.hasNext(WholeStageCodegenExec.scala:395) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:125) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53) at org.apache.spark.scheduler.Task.run(Task.scala:108) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) 18/03/19 18:29:37 ERROR ExecutorClassLoader: Failed to check existence of class HBase Counters_en on REPL class server at spark://192.168.86.151:34328/classes java.net.URISyntaxException: Illegal character in path at index 42: spark://192.168.86.151:34328/classes/HBase Counters_en.class at java.net.URI$Parser.fail(URI.java:2848) at java.net.URI$Parser.checkChars(URI.java:3021) at java.net.URI$Parser.parseHierarchical(URI.java:3105) at java.net.URI$Parser.parse(URI.java:3053) at java.net.URI.<init>(URI.java:588) at org.apache.spark.rpc.netty.NettyRpcEnv.openChannel(NettyRpcEnv.scala:324) at org.apache.spark.repl.ExecutorClassLoader.org$apache$spark$repl$ExecutorClassLoader$$getClassFileInputStreamFromSparkRPC(ExecutorClassLoader.scala:90) at org.apache.spark.repl.ExecutorClassLoader$$anonfun$1.apply(ExecutorClassLoader.scala:57) at org.apache.spark.repl.ExecutorClassLoader$$anonfun$1.apply(ExecutorClassLoader.scala:57) at org.apache.spark.repl.ExecutorClassLoader.findClassLocally(ExecutorClassLoader.scala:162) at org.apache.spark.repl.ExecutorClassLoader.findClass(ExecutorClassLoader.scala:80) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at java.util.ResourceBundle$Control.newBundle(ResourceBundle.java:2640) at java.util.ResourceBundle.loadBundle(ResourceBundle.java:1501) at java.util.ResourceBundle.findBundle(ResourceBundle.java:1465) at java.util.ResourceBundle.findBundle(ResourceBundle.java:1419) at java.util.ResourceBundle.getBundleImpl(ResourceBundle.java:1361) at java.util.ResourceBundle.getBundle(ResourceBundle.java:1082) at org.apache.hadoop.mapreduce.util.ResourceBundles.getBundle(ResourceBundles.java:37) at org.apache.hadoop.mapreduce.util.ResourceBundles.getValue(ResourceBundles.java:56) at org.apache.hadoop.mapreduce.util.ResourceBundles.getCounterGroupName(ResourceBundles.java:77) at org.apache.hadoop.mapreduce.counters.CounterGroupFactory.newGroup(CounterGroupFactory.java:94) at org.apache.hadoop.mapreduce.counters.AbstractCounters.getGroup(AbstractCounters.java:226) at org.apache.hadoop.mapreduce.counters.AbstractCounters.findCounter(AbstractCounters.java:153) at org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl$DummyReporter.getCounter(TaskAttemptContextImpl.java:110) at org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl.getCounter(TaskAttemptContextImpl.java:76) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at org.apache.hadoop.hbase.mapreduce.TableRecordReaderImpl.updateCounters(TableRecordReaderImpl.java:285) at org.apache.hadoop.hbase.mapreduce.TableRecordReaderImpl.updateCounters(TableRecordReaderImpl.java:273) at org.apache.hadoop.hbase.mapreduce.TableRecordReaderImpl.nextKeyValue(TableRecordReaderImpl.java:241) at org.apache.hadoop.hbase.mapreduce.TableRecordReader.nextKeyValue(TableRecordReader.java:138) at org.apache.hadoop.hive.hbase.HiveHBaseTableInputFormat$1.next(HiveHBaseTableInputFormat.java:154) at org.apache.hadoop.hive.hbase.HiveHBaseTableInputFormat$1.next(HiveHBaseTableInputFormat.java:113) at org.apache.spark.rdd.HadoopRDD$$anon$1.getNext(HadoopRDD.scala:266) at org.apache.spark.rdd.HadoopRDD$$anon$1.getNext(HadoopRDD.scala:203) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.agg_doAggregateWithoutKey$(Unknown Source) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8$$anon$1.hasNext(WholeStageCodegenExec.scala:395) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:125) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53) at org.apache.spark.scheduler.Task.run(Task.scala:108) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) 18/03/19 18:29:37 ERROR ExecutorClassLoader: Failed to check existence of class HBase Counters_en_US on REPL class server at spark://192.168.86.151:34328/classes java.net.URISyntaxException: Illegal character in path at index 42: spark://192.168.86.151:34328/classes/HBase Counters_en_US.class at java.net.URI$Parser.fail(URI.java:2848) at java.net.URI$Parser.checkChars(URI.java:3021) at java.net.URI$Parser.parseHierarchical(URI.java:3105) at java.net.URI$Parser.parse(URI.java:3053) at java.net.URI.<init>(URI.java:588) at org.apache.spark.rpc.netty.NettyRpcEnv.openChannel(NettyRpcEnv.scala:324) at org.apache.spark.repl.ExecutorClassLoader.org$apache$spark$repl$ExecutorClassLoader$$getClassFileInputStreamFromSparkRPC(ExecutorClassLoader.scala:90) at org.apache.spark.repl.ExecutorClassLoader$$anonfun$1.apply(ExecutorClassLoader.scala:57) at org.apache.spark.repl.ExecutorClassLoader$$anonfun$1.apply(ExecutorClassLoader.scala:57) at org.apache.spark.repl.ExecutorClassLoader.findClassLocally(ExecutorClassLoader.scala:162) at org.apache.spark.repl.ExecutorClassLoader.findClass(ExecutorClassLoader.scala:80) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at java.util.ResourceBundle$Control.newBundle(ResourceBundle.java:2640) at java.util.ResourceBundle.loadBundle(ResourceBundle.java:1501) at java.util.ResourceBundle.findBundle(ResourceBundle.java:1465) at java.util.ResourceBundle.getBundleImpl(ResourceBundle.java:1361) at java.util.ResourceBundle.getBundle(ResourceBundle.java:1082) at org.apache.hadoop.mapreduce.util.ResourceBundles.getBundle(ResourceBundles.java:37) at org.apache.hadoop.mapreduce.util.ResourceBundles.getValue(ResourceBundles.java:56) at org.apache.hadoop.mapreduce.util.ResourceBundles.getCounterGroupName(ResourceBundles.java:77) at org.apache.hadoop.mapreduce.counters.CounterGroupFactory.newGroup(CounterGroupFactory.java:94) at org.apache.hadoop.mapreduce.counters.AbstractCounters.getGroup(AbstractCounters.java:226) at org.apache.hadoop.mapreduce.counters.AbstractCounters.findCounter(AbstractCounters.java:153) at org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl$DummyReporter.getCounter(TaskAttemptContextImpl.java:110) at org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl.getCounter(TaskAttemptContextImpl.java:76) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at org.apache.hadoop.hbase.mapreduce.TableRecordReaderImpl.updateCounters(TableRecordReaderImpl.java:285) at org.apache.hadoop.hbase.mapreduce.TableRecordReaderImpl.updateCounters(TableRecordReaderImpl.java:273) at org.apache.hadoop.hbase.mapreduce.TableRecordReaderImpl.nextKeyValue(TableRecordReaderImpl.java:241) at org.apache.hadoop.hbase.mapreduce.TableRecordReader.nextKeyValue(TableRecordReader.java:138) at org.apache.hadoop.hive.hbase.HiveHBaseTableInputFormat$1.next(HiveHBaseTableInputFormat.java:154) at org.apache.hadoop.hive.hbase.HiveHBaseTableInputFormat$1.next(HiveHBaseTableInputFormat.java:113) at org.apache.spark.rdd.HadoopRDD$$anon$1.getNext(HadoopRDD.scala:266) at org.apache.spark.rdd.HadoopRDD$$anon$1.getNext(HadoopRDD.scala:203) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.agg_doAggregateWithoutKey$(Unknown Source) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8$$anon$1.hasNext(WholeStageCodegenExec.scala:395) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408) at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:125) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53) at org.apache.spark.scheduler.Task.run(Task.scala:108) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) 18/03/19 18:29:37 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1633 bytes result sent to driver 18/03/19 18:29:38 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1714 ms on localhost (executor driver) (1/1) 18/03/19 18:29:38 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 18/03/19 18:29:38 INFO DAGScheduler: ShuffleMapStage 0 (show at <console>:23) finished in 1.772 s 18/03/19 18:29:38 INFO DAGScheduler: looking for newly runnable stages 18/03/19 18:29:38 INFO DAGScheduler: running: Set() 18/03/19 18:29:38 INFO DAGScheduler: waiting: Set(ResultStage 1) 18/03/19 18:29:38 INFO DAGScheduler: failed: Set() 18/03/19 18:29:38 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[8] at show at <console>:23), which has no missing parents 18/03/19 18:29:38 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 6.9 KB, free 413.6 MB) 18/03/19 18:29:38 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 3.7 KB, free 413.6 MB) 18/03/19 18:29:38 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.86.151:42725 (size: 3.7 KB, free: 413.9 MB) 18/03/19 18:29:38 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1006 18/03/19 18:29:38 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[8] at show at <console>:23) (first 15 tasks are for partitions Vector(0)) 18/03/19 18:29:38 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks 18/03/19 18:29:38 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, executor driver, partition 0, ANY, 4726 bytes) 18/03/19 18:29:38 INFO Executor: Running task 0.0 in stage 1.0 (TID 1) 18/03/19 18:29:38 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks 18/03/19 18:29:38 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 24 ms 18/03/19 18:29:38 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1557 bytes result sent to driver 18/03/19 18:29:38 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 167 ms on localhost (executor driver) (1/1) 18/03/19 18:29:38 INFO DAGScheduler: ResultStage 1 (show at <console>:23) finished in 0.166 s 18/03/19 18:29:38 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 18/03/19 18:29:38 INFO DAGScheduler: Job 0 finished: show at <console>:23, took 2.618861 s 18/03/19 18:29:38 INFO CodeGenerator: Code generated in 53.284282 ms +--------+ |count(1)| +--------+ | 15814| +--------+ df: Unit = () scala> val df =spark.sql("select * from weblogs limit 10").show 18/03/19 18:29:53 INFO BlockManagerInfo: Removed broadcast_2_piece0 on 192.168.86.151:42725 in memory (size: 3.7 KB, free: 413.9 MB) 18/03/19 18:29:53 INFO SparkSqlParser: Parsing command: select * from weblogs limit 10 18/03/19 18:29:53 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:53 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:53 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:53 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:53 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:53 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:53 INFO CatalystSqlParser: Parsing command: string 18/03/19 18:29:53 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 242.3 KB, free 413.4 MB) 18/03/19 18:29:53 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 23.0 KB, free 413.4 MB) 18/03/19 18:29:53 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.86.151:42725 (size: 23.0 KB, free: 413.9 MB) 18/03/19 18:29:53 INFO SparkContext: Created broadcast 3 from 18/03/19 18:29:54 INFO HBaseStorageHandler: Configuring input job properties 18/03/19 18:29:54 INFO RegionSizeCalculator: Calculating region sizes for table "weblogs". 18/03/19 18:29:55 WARN TableInputFormatBase: Cannot resolve the host name for bigdata-pro03.kfk.com/192.168.86.153 because of javax.naming.NameNotFoundException: DNS name not found [response code 3]; remaining name '153.86.168.192.in-addr.arpa' 18/03/19 18:29:55 INFO SparkContext: Starting job: show at <console>:23 18/03/19 18:29:55 INFO DAGScheduler: Got job 1 (show at <console>:23) with 1 output partitions 18/03/19 18:29:55 INFO DAGScheduler: Final stage: ResultStage 2 (show at <console>:23) 18/03/19 18:29:55 INFO DAGScheduler: Parents of final stage: List() 18/03/19 18:29:55 INFO DAGScheduler: Missing parents: List() 18/03/19 18:29:55 INFO DAGScheduler: Submitting ResultStage 2 (MapPartitionsRDD[13] at show at <console>:23), which has no missing parents 18/03/19 18:29:55 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 15.8 KB, free 413.4 MB) 18/03/19 18:29:55 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 8.4 KB, free 413.4 MB) 18/03/19 18:29:55 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.86.151:42725 (size: 8.4 KB, free: 413.9 MB) 18/03/19 18:29:55 INFO SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:1006 18/03/19 18:29:55 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 2 (MapPartitionsRDD[13] at show at <console>:23) (first 15 tasks are for partitions Vector(0)) 18/03/19 18:29:55 INFO TaskSchedulerImpl: Adding task set 2.0 with 1 tasks 18/03/19 18:29:55 INFO TaskSetManager: Starting task 0.0 in stage 2.0 (TID 2, localhost, executor driver, partition 0, ANY, 4905 bytes) 18/03/19 18:29:55 INFO Executor: Running task 0.0 in stage 2.0 (TID 2) 18/03/19 18:29:55 INFO HadoopRDD: Input split: bigdata-pro03.kfk.com:, 18/03/19 18:29:55 INFO TableInputFormatBase: Input split length: 7 M bytes. 18/03/19 18:29:55 INFO CodeGenerator: Code generated in 94.66518 ms 18/03/19 18:29:55 INFO Executor: Finished task 0.0 in stage 2.0 (TID 2). 1685 bytes result sent to driver 18/03/19 18:29:55 INFO TaskSetManager: Finished task 0.0 in stage 2.0 (TID 2) in 368 ms on localhost (executor driver) (1/1) 18/03/19 18:29:55 INFO DAGScheduler: ResultStage 2 (show at <console>:23) finished in 0.361 s 18/03/19 18:29:55 INFO DAGScheduler: Job 1 finished: show at <console>:23, took 0.421794 s 18/03/19 18:29:55 INFO TaskSchedulerImpl: Removed TaskSet 2.0, whose tasks have all completed, from pool 18/03/19 18:29:55 INFO CodeGenerator: Code generated in 95.678505 ms +--------------------+--------+-------------------+----------+--------+--------+--------------------+ | id|datatime| userid|searchname|retorder|cliorder| cliurl| +--------------------+--------+-------------------+----------+--------+--------+--------------------+ |00127896594320375...|00:05:51|0012789659432037581| [蒙古国地图]| 1| 3|maps.blogtt.com/m...| |00127896594320375...|00:05:51|0012789659432037581| [蒙古国地图]| 1| 3|maps.blogtt.com/m...| |00143454165872647...|00:05:46|0014345416587264736| [ppg]| 3| 2|www.ppg.cn/yesppg...| |00143454165872647...|00:05:46|0014345416587264736| [ppg]| 3| 2|www.ppg.cn/yesppg...| |00143621727586595...|00:02:09|0014362172758659586| [明星合成]| 78| 24|scsdcsadwa.blog.s...| |00143621727586595...|00:02:09|0014362172758659586| [明星合成]| 78| 24|scsdcsadwa.blog.s...| |00143621727586595...|00:02:28|0014362172758659586| [明星合成]| 82| 26| av.avbox.us/| |00143621727586595...|00:02:28|0014362172758659586| [明星合成]| 82| 26| av.avbox.us/| |00143621727586595...|00:02:44|0014362172758659586| [明星合成]| 83| 27|csdfhnuop.blog.so...| |00143621727586595...|00:02:44|0014362172758659586| [明星合成]| 83| 27|csdfhnuop.blog.so...| +--------------------+--------+-------------------+----------+--------+--------+--------------------+ df: Unit = () scala> 18/03/19 18:33:57 INFO BlockManagerInfo: Removed broadcast_4_piece0 on 192.168.86.151:42725 in memory (size: 8.4 KB, free: 413.9 MB) 18/03/19 18:33:57 INFO BlockManagerInfo: Removed broadcast_3_piece0 on 192.168.86.151:42725 in memory (size: 23.0 KB, free: 413.9 MB) 18/03/19 18:33:57 INFO ContextCleaner: Cleaned accumulator 85

我们基于集群模式启动spark-shell



scala> spark.sql("select count(1) from weblogs").show 18/03/19 21:26:13 INFO SparkSqlParser: Parsing command: select count(1) from weblogs 18/03/19 21:26:15 INFO CatalystSqlParser: Parsing command: string 18/03/19 21:26:15 INFO CatalystSqlParser: Parsing command: string 18/03/19 21:26:15 INFO CatalystSqlParser: Parsing command: string 18/03/19 21:26:15 INFO CatalystSqlParser: Parsing command: string 18/03/19 21:26:15 INFO CatalystSqlParser: Parsing command: string 18/03/19 21:26:15 INFO CatalystSqlParser: Parsing command: string 18/03/19 21:26:15 INFO CatalystSqlParser: Parsing command: string 18/03/19 21:26:18 INFO ContextCleaner: Cleaned accumulator 0 18/03/19 21:26:18 INFO CodeGenerator: Code generated in 1043.849585 ms 18/03/19 21:26:18 INFO CodeGenerator: Code generated in 79.914587 ms 18/03/19 21:26:20 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 242.2 KB, free 413.7 MB) 18/03/19 21:26:20 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 22.9 KB, free 413.7 MB) 18/03/19 21:26:20 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.86.151:35979 (size: 22.9 KB, free: 413.9 MB) 18/03/19 21:26:20 INFO SparkContext: Created broadcast 0 from 18/03/19 21:26:21 INFO HBaseStorageHandler: Configuring input job properties 18/03/19 21:26:21 INFO RecoverableZooKeeper: Process identifier=hconnection-0x25131637 connecting to ZooKeeper ensemble=bigdata-pro02.kfk.com:2181,bigdata-pro01.kfk.com:2181,bigdata-pro03.kfk.com:2181 18/03/19 21:26:21 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 18/03/19 21:26:21 INFO ZooKeeper: Client environment:host.name=bigdata-pro01.kfk.com 18/03/19 21:26:21 INFO ZooKeeper: Client environment:java.version=1.8.0_60 18/03/19 21:26:21 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation 18/03/19 21:26:21 INFO ZooKeeper: Client environment:java.home=/opt/modules/jdk1.8.0_60/jre 18/03/19 21:26:21 INFO ZooKeeper: Client environment:java.class.path=/opt/modules/spark-2.2.0-bin/conf/:/opt/modules/spark-2.2.0-bin/jars/htrace-core-3.0.4.jar:/opt/modules/spark-2.2.0-bin/jars/jpam-1.1.jar:/opt/modules/spark-2.2.0-bin/jars/mysql-connector-java-5.1.27-bin.jar:/opt/modules/spark-2.2.0-bin/jars/snappy-java-1.1.2.6.jar:/opt/modules/spark-2.2.0-bin/jars/commons-compress-1.4.1.jar:/opt/modules/spark-2.2.0-bin/jars/hbase-server-0.98.6-cdh5.3.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-sql_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-client-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/jetty-6.1.26.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-databind-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/javolution-5.5.1.jar:/opt/modules/spark-2.2.0-bin/jars/opencsv-2.3.jar:/opt/modules/spark-2.2.0-bin/jars/curator-framework-2.6.0.jar:/opt/modules/spark-2.2.0-bin/jars/commons-collections-3.2.2.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-mapreduce-client-jobclient-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/hk2-utils-2.4.0-b34.jar:/opt/modules/spark-2.2.0-bin/jars/metrics-graphite-3.1.2.jar:/opt/modules/spark-2.2.0-bin/jars/pmml-model-1.2.15.jar:/opt/modules/spark-2.2.0-bin/jars/compress-lzf-1.0.3.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-mapreduce-client-app-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-encoding-1.8.2.jar:/opt/modules/spark-2.2.0-bin/jars/xz-1.0.jar:/opt/modules/spark-2.2.0-bin/jars/datanucleus-core-3.2.10.jar:/opt/modules/spark-2.2.0-bin/jars/guice-servlet-3.0.jar:/opt/modules/spark-2.2.0-bin/jars/stax-api-1.0-2.jar:/opt/modules/spark-2.2.0-bin/jars/eigenbase-properties-1.1.5.jar:/opt/modules/spark-2.2.0-bin/jars/metrics-jvm-3.1.2.jar:/opt/modules/spark-2.2.0-bin/jars/stream-2.7.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-mllib-local_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/derby-10.12.1.1.jar:/opt/modules/spark-2.2.0-bin/jars/joda-time-2.9.3.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-common-1.8.2.jar:/opt/modules/spark-2.2.0-bin/jars/ivy-2.4.0.jar:/opt/modules/spark-2.2.0-bin/jars/slf4j-api-1.7.16.jar:/opt/modules/spark-2.2.0-bin/jars/jetty-util-6.1.26.jar:/opt/modules/spark-2.2.0-bin/jars/shapeless_2.11-2.3.2.jar:/opt/modules/spark-2.2.0-bin/jars/activation-1.1.1.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-module-scala_2.11-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/libthrift-0.9.3.jar:/opt/modules/spark-2.2.0-bin/jars/log4j-1.2.17.jar:/opt/modules/spark-2.2.0-bin/jars/antlr4-runtime-4.5.3.jar:/opt/modules/spark-2.2.0-bin/jars/chill-java-0.8.0.jar:/opt/modules/spark-2.2.0-bin/jars/snappy-0.2.jar:/opt/modules/spark-2.2.0-bin/jars/core-1.1.2.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-annotations-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-container-servlet-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/spark-network-shuffle_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-graphx_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/breeze_2.11-0.13.1.jar:/opt/modules/spark-2.2.0-bin/jars/scala-compiler-2.11.8.jar:/opt/modules/spark-2.2.0-bin/jars/aopalliance-1.0.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-mapreduce-client-common-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/aopalliance-repackaged-2.4.0-b34.jar:/opt/modules/spark-2.2.0-bin/jars/commons-beanutils-core-1.8.0.jar:/opt/modules/spark-2.2.0-bin/jars/jsr305-1.3.9.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-yarn-common-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/osgi-resource-locator-1.0.1.jar:/opt/modules/spark-2.2.0-bin/jars/univocity-parsers-2.2.1.jar:/opt/modules/spark-2.2.0-bin/jars/hive-exec-1.2.1.spark2.jar:/opt/modules/spark-2.2.0-bin/jars/commons-crypto-1.0.0.jar:/opt/modules/spark-2.2.0-bin/jars/metrics-json-3.1.2.jar:/opt/modules/spark-2.2.0-bin/jars/minlog-1.3.0.jar:/opt/modules/spark-2.2.0-bin/jars/JavaEWAH-0.3.2.jar:/opt/modules/spark-2.2.0-bin/jars/json4s-jackson_2.11-3.2.11.jar:/opt/modules/spark-2.2.0-bin/jars/javax.ws.rs-api-2.0.1.jar:/opt/modules/spark-2.2.0-bin/jars/commons-dbcp-1.4.jar:/opt/modules/spark-2.2.0-bin/jars/slf4j-log4j12-1.7.16.jar:/opt/modules/spark-2.2.0-bin/jars/javax.inject-2.4.0-b34.jar:/opt/modules/spark-2.2.0-bin/jars/scala-xml_2.11-1.0.2.jar:/opt/modules/spark-2.2.0-bin/jars/commons-pool-1.5.4.jar:/opt/modules/spark-2.2.0-bin/jars/jaxb-api-2.2.2.jar:/opt/modules/spark-2.2.0-bin/jars/spark-network-common_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/gson-2.2.4.jar:/opt/modules/spark-2.2.0-bin/jars/protobuf-java-2.5.0.jar:/opt/modules/spark-2.2.0-bin/jars/objenesis-2.1.jar:/opt/modules/spark-2.2.0-bin/jars/hive-metastore-1.2.1.spark2.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-container-servlet-core-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/stax-api-1.0.1.jar:/opt/modules/spark-2.2.0-bin/jars/super-csv-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/metrics-core-3.1.2.jar:/opt/modules/spark-2.2.0-bin/jars/scala-parser-combinators_2.11-1.0.4.jar:/opt/modules/spark-2.2.0-bin/jars/apacheds-i18n-2.0.0-M15.jar:/opt/modules/spark-2.2.0-bin/jars/spire_2.11-0.13.0.jar:/opt/modules/spark-2.2.0-bin/jars/xbean-asm5-shaded-4.4.jar:/opt/modules/spark-2.2.0-bin/jars/httpclient-4.5.2.jar:/opt/modules/spark-2.2.0-bin/jars/hive-beeline-1.2.1.spark2.jar:/opt/modules/spark-2.2.0-bin/jars/janino-3.0.0.jar:/opt/modules/spark-2.2.0-bin/jars/commons-beanutils-1.7.0.jar:/opt/modules/spark-2.2.0-bin/jars/javax.annotation-api-1.2.jar:/opt/modules/spark-2.2.0-bin/jars/curator-recipes-2.6.0.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-core-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/paranamer-2.6.jar:/opt/modules/spark-2.2.0-bin/jars/hk2-locator-2.4.0-b34.jar:/opt/modules/spark-2.2.0-bin/jars/spark-hive_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/bonecp-0.8.0.RELEASE.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-column-1.8.2.jar:/opt/modules/spark-2.2.0-bin/jars/calcite-linq4j-1.2.0-incubating.jar:/opt/modules/spark-2.2.0-bin/jars/commons-cli-1.2.jar:/opt/modules/spark-2.2.0-bin/jars/javax.inject-1.jar:/opt/modules/spark-2.2.0-bin/jars/hbase-common-0.98.6-cdh5.3.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-tags_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/bcprov-jdk15on-1.51.jar:/opt/modules/spark-2.2.0-bin/jars/stringtemplate-3.2.1.jar:/opt/modules/spark-2.2.0-bin/jars/RoaringBitmap-0.5.11.jar:/opt/modules/spark-2.2.0-bin/jars/hbase-client-0.98.6-cdh5.3.0.jar:/opt/modules/spark-2.2.0-bin/jars/commons-codec-1.10.jar:/opt/modules/spark-2.2.0-bin/jars/hive-cli-1.2.1.spark2.jar:/opt/modules/spark-2.2.0-bin/jars/scala-reflect-2.11.8.jar:/opt/modules/spark-2.2.0-bin/jars/jline-2.12.1.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-core-asl-1.9.13.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-server-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/xercesImpl-2.9.1.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-format-2.3.1.jar:/opt/modules/spark-2.2.0-bin/jars/jdo-api-3.0.1.jar:/opt/modules/spark-2.2.0-bin/jars/commons-lang-2.6.jar:/opt/modules/spark-2.2.0-bin/jars/jta-1.1.jar:/opt/modules/spark-2.2.0-bin/jars/commons-httpclient-3.1.jar:/opt/modules/spark-2.2.0-bin/jars/pyrolite-4.13.jar:/opt/modules/spark-2.2.0-bin/jars/jul-to-slf4j-1.7.16.jar:/opt/modules/spark-2.2.0-bin/jars/api-util-1.0.0-M20.jar:/opt/modules/spark-2.2.0-bin/jars/hive-hbase-handler-1.2.1.jar:/opt/modules/spark-2.2.0-bin/jars/commons-math3-3.4.1.jar:/opt/modules/spark-2.2.0-bin/jars/jets3t-0.9.3.jar:/opt/modules/spark-2.2.0-bin/jars/spark-catalyst_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-jackson-1.8.2.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-annotations-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-yarn-server-web-proxy-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/spark-hive-thriftserver_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-hadoop-1.8.2.jar:/opt/modules/spark-2.2.0-bin/jars/apacheds-kerberos-codec-2.0.0-M15.jar:/opt/modules/spark-2.2.0-bin/jars/ST4-4.0.4.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-mapper-asl-1.9.13.jar:/opt/modules/spark-2.2.0-bin/jars/machinist_2.11-0.6.1.jar:/opt/modules/spark-2.2.0-bin/jars/spark-mllib_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/scala-library-2.11.8.jar:/opt/modules/spark-2.2.0-bin/jars/guava-14.0.1.jar:/opt/modules/spark-2.2.0-bin/jars/javassist-3.18.1-GA.jar:/opt/modules/spark-2.2.0-bin/jars/api-asn1-api-1.0.0-M20.jar:/opt/modules/spark-2.2.0-bin/jars/antlr-2.7.7.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-module-paranamer-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/curator-client-2.6.0.jar:/opt/modules/spark-2.2.0-bin/jars/arpack_combined_all-0.1.jar:/opt/modules/spark-2.2.0-bin/jars/datanucleus-api-jdo-3.2.6.jar:/opt/modules/spark-2.2.0-bin/jars/calcite-avatica-1.2.0-incubating.jar:/opt/modules/spark-2.2.0-bin/jars/avro-mapred-1.7.7-hadoop2.jar:/opt/modules/spark-2.2.0-bin/jars/hive-jdbc-1.2.1.spark2.jar:/opt/modules/spark-2.2.0-bin/jars/breeze-macros_2.11-0.13.1.jar:/opt/modules/spark-2.2.0-bin/jars/hbase-protocol-0.98.6-cdh5.3.0.jar:/opt/modules/spark-2.2.0-bin/jars/json4s-core_2.11-3.2.11.jar:/opt/modules/spark-2.2.0-bin/jars/spire-macros_2.11-0.13.0.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-client-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/mx4j-3.0.2.jar:/opt/modules/spark-2.2.0-bin/jars/py4j-0.10.4.jar:/opt/modules/spark-2.2.0-bin/jars/scalap-2.11.8.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-guava-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-media-jaxb-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/commons-configuration-1.6.jar:/opt/modules/spark-2.2.0-bin/jars/json4s-ast_2.11-3.2.11.jar:/opt/modules/spark-2.2.0-bin/jars/htrace-core-2.04.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-common-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/kryo-shaded-3.0.3.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-auth-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/commons-compiler-3.0.0.jar:/opt/modules/spark-2.2.0-bin/jars/jtransforms-2.4.0.jar:/opt/modules/spark-2.2.0-bin/jars/commons-net-2.2.jar:/opt/modules/spark-2.2.0-bin/jars/jcl-over-slf4j-1.7.16.jar:/opt/modules/spark-2.2.0-bin/jars/spark-launcher_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-core_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/antlr-runtime-3.4.jar:/opt/modules/spark-2.2.0-bin/jars/spark-repl_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-streaming_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/datanucleus-rdbms-3.2.9.jar:/opt/modules/spark-2.2.0-bin/jars/netty-3.9.9.Final.jar:/opt/modules/spark-2.2.0-bin/jars/lz4-1.3.0.jar:/opt/modules/spark-2.2.0-bin/jars/zookeeper-3.4.6.jar:/opt/modules/spark-2.2.0-bin/jars/java-xmlbuilder-1.0.jar:/opt/modules/spark-2.2.0-bin/jars/jersey-common-2.22.2.jar:/opt/modules/spark-2.2.0-bin/jars/netty-all-4.0.43.Final.jar:/opt/modules/spark-2.2.0-bin/jars/validation-api-1.1.0.Final.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-mapreduce-client-core-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/avro-ipc-1.7.7.jar:/opt/modules/spark-2.2.0-bin/jars/jodd-core-3.5.2.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-xc-1.9.13.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-yarn-client-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/guice-3.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-yarn_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/parquet-hadoop-bundle-1.6.0.jar:/opt/modules/spark-2.2.0-bin/jars/leveldbjni-all-1.8.jar:/opt/modules/spark-2.2.0-bin/jars/hk2-api-2.4.0-b34.jar:/opt/modules/spark-2.2.0-bin/jars/javax.servlet-api-3.1.0.jar:/opt/modules/spark-2.2.0-bin/jars/mysql-connector-java-5.1.27.jar:/opt/modules/spark-2.2.0-bin/jars/libfb303-0.9.3.jar:/opt/modules/spark-2.2.0-bin/jars/httpcore-4.4.4.jar:/opt/modules/spark-2.2.0-bin/jars/chill_2.11-0.8.0.jar:/opt/modules/spark-2.2.0-bin/jars/spark-sketch_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/commons-lang3-3.5.jar:/opt/modules/spark-2.2.0-bin/jars/mail-1.4.7.jar:/opt/modules/spark-2.2.0-bin/jars/apache-log4j-extras-1.2.17.jar:/opt/modules/spark-2.2.0-bin/jars/xmlenc-0.52.jar:/opt/modules/spark-2.2.0-bin/jars/avro-1.7.7.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-yarn-server-common-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-yarn-api-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-hdfs-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/pmml-schema-1.2.15.jar:/opt/modules/spark-2.2.0-bin/jars/calcite-core-1.2.0-incubating.jar:/opt/modules/spark-2.2.0-bin/jars/spark-unsafe_2.11-2.2.0.jar:/opt/modules/spark-2.2.0-bin/jars/base64-2.3.8.jar:/opt/modules/spark-2.2.0-bin/jars/jackson-jaxrs-1.9.13.jar:/opt/modules/spark-2.2.0-bin/jars/hadoop-mapreduce-client-shuffle-2.6.5.jar:/opt/modules/spark-2.2.0-bin/jars/oro-2.0.8.jar:/opt/modules/spark-2.2.0-bin/jars/commons-digester-1.8.jar:/opt/modules/spark-2.2.0-bin/jars/commons-io-2.4.jar:/opt/modules/spark-2.2.0-bin/jars/commons-logging-1.1.3.jar:/opt/modules/spark-2.2.0-bin/jars/macro-compat_2.11-1.1.1.jar:/opt/modules/hadoop-2.6.0/etc/hadoop/ 18/03/19 21:26:21 INFO ZooKeeper: Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib 18/03/19 21:26:21 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp 18/03/19 21:26:21 INFO ZooKeeper: Client environment:java.compiler=<NA> 18/03/19 21:26:21 INFO ZooKeeper: Client environment:os.name=Linux 18/03/19 21:26:21 INFO ZooKeeper: Client environment:os.arch=amd64 18/03/19 21:26:21 INFO ZooKeeper: Client environment:os.version=2.6.32-431.el6.x86_64 18/03/19 21:26:21 INFO ZooKeeper: Client environment:user.name=kfk 18/03/19 21:26:21 INFO ZooKeeper: Client environment:user.home=/home/kfk 18/03/19 21:26:21 INFO ZooKeeper: Client environment:user.dir=/opt/modules/spark-2.2.0-bin 18/03/19 21:26:21 INFO ZooKeeper: Initiating client connection, connectString=bigdata-pro02.kfk.com:2181,bigdata-pro01.kfk.com:2181,bigdata-pro03.kfk.com:2181 sessionTimeout=90000 watcher=hconnection-0x25131637, quorum=bigdata-pro02.kfk.com:2181,bigdata-pro01.kfk.com:2181,bigdata-pro03.kfk.com:2181, baseZNode=/hbase 18/03/19 21:26:21 INFO ClientCnxn: Opening socket connection to server bigdata-pro01.kfk.com/192.168.86.151:2181. Will not attempt to authenticate using SASL (unknown error) 18/03/19 21:26:21 INFO ClientCnxn: Socket connection established to bigdata-pro01.kfk.com/192.168.86.151:2181, initiating session 18/03/19 21:26:22 INFO ClientCnxn: Session establishment complete on server bigdata-pro01.kfk.com/192.168.86.151:2181, sessionid = 0x1623bd7ca740014, negotiated timeout = 40000 18/03/19 21:26:22 INFO RegionSizeCalculator: Calculating region sizes for table "weblogs". 18/03/19 21:26:54 WARN TableInputFormatBase: Cannot resolve the host name for bigdata-pro03.kfk.com/192.168.86.153 because of javax.naming.CommunicationException: DNS error [Root exception is java.net.SocketTimeoutException: Receive timed out]; remaining name '153.86.168.192.in-addr.arpa' 18/03/19 21:26:54 INFO SparkContext: Starting job: show at <console>:24 18/03/19 21:26:54 INFO DAGScheduler: Registering RDD 5 (show at <console>:24) 18/03/19 21:26:54 INFO DAGScheduler: Got job 0 (show at <console>:24) with 1 output partitions 18/03/19 21:26:54 INFO DAGScheduler: Final stage: ResultStage 1 (show at <console>:24) 18/03/19 21:26:54 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0) 18/03/19 21:26:54 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0) 18/03/19 21:26:54 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[5] at show at <console>:24), which has no missing parents 18/03/19 21:26:54 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 18.9 KB, free 413.6 MB) 18/03/19 21:26:54 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 9.9 KB, free 413.6 MB) 18/03/19 21:26:54 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.86.151:35979 (size: 9.9 KB, free: 413.9 MB) 18/03/19 21:26:54 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1006 18/03/19 21:26:55 INFO DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[5] at show at <console>:24) (first 15 tasks are for partitions Vector(0)) 18/03/19 21:26:55 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks 18/03/19 21:26:55 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 192.168.86.153, executor 0, partition 0, ANY, 4898 bytes) 18/03/19 21:26:56 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.86.153:43492 (size: 9.9 KB, free: 413.9 MB) 18/03/19 21:26:59 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.86.153:43492 (size: 22.9 KB, free: 413.9 MB) 18/03/19 21:27:12 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 17658 ms on 192.168.86.153 (executor 0) (1/1) 18/03/19 21:27:12 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 18/03/19 21:27:12 INFO DAGScheduler: ShuffleMapStage 0 (show at <console>:24) finished in 17.708 s 18/03/19 21:27:12 INFO DAGScheduler: looking for newly runnable stages 18/03/19 21:27:12 INFO DAGScheduler: running: Set() 18/03/19 21:27:12 INFO DAGScheduler: waiting: Set(ResultStage 1) 18/03/19 21:27:12 INFO DAGScheduler: failed: Set() 18/03/19 21:27:12 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[8] at show at <console>:24), which has no missing parents 18/03/19 21:27:12 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 6.9 KB, free 413.6 MB) 18/03/19 21:27:12 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 3.7 KB, free 413.6 MB) 18/03/19 21:27:12 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.86.151:35979 (size: 3.7 KB, free: 413.9 MB) 18/03/19 21:27:12 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1006 18/03/19 21:27:12 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[8] at show at <console>:24) (first 15 tasks are for partitions Vector(0)) 18/03/19 21:27:12 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks 18/03/19 21:27:12 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, 192.168.86.153, executor 0, partition 0, NODE_LOCAL, 4730 bytes) 18/03/19 21:27:13 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.86.153:43492 (size: 3.7 KB, free: 413.9 MB) 18/03/19 21:27:13 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 0 to 192.168.86.153:46380 18/03/19 21:27:13 INFO MapOutputTrackerMaster: Size of output statuses for shuffle 0 is 145 bytes 18/03/19 21:27:13 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 688 ms on 192.168.86.153 (executor 0) (1/1) 18/03/19 21:27:13 INFO DAGScheduler: ResultStage 1 (show at <console>:24) finished in 0.695 s 18/03/19 21:27:13 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 18/03/19 21:27:13 INFO DAGScheduler: Job 0 finished: show at <console>:24, took 19.203658 s 18/03/19 21:27:13 INFO CodeGenerator: Code generated in 57.823649 ms +--------+ |count(1)| +--------+ | 15814| +--------+ scala>
我们在hive里面查看一下统计的条数
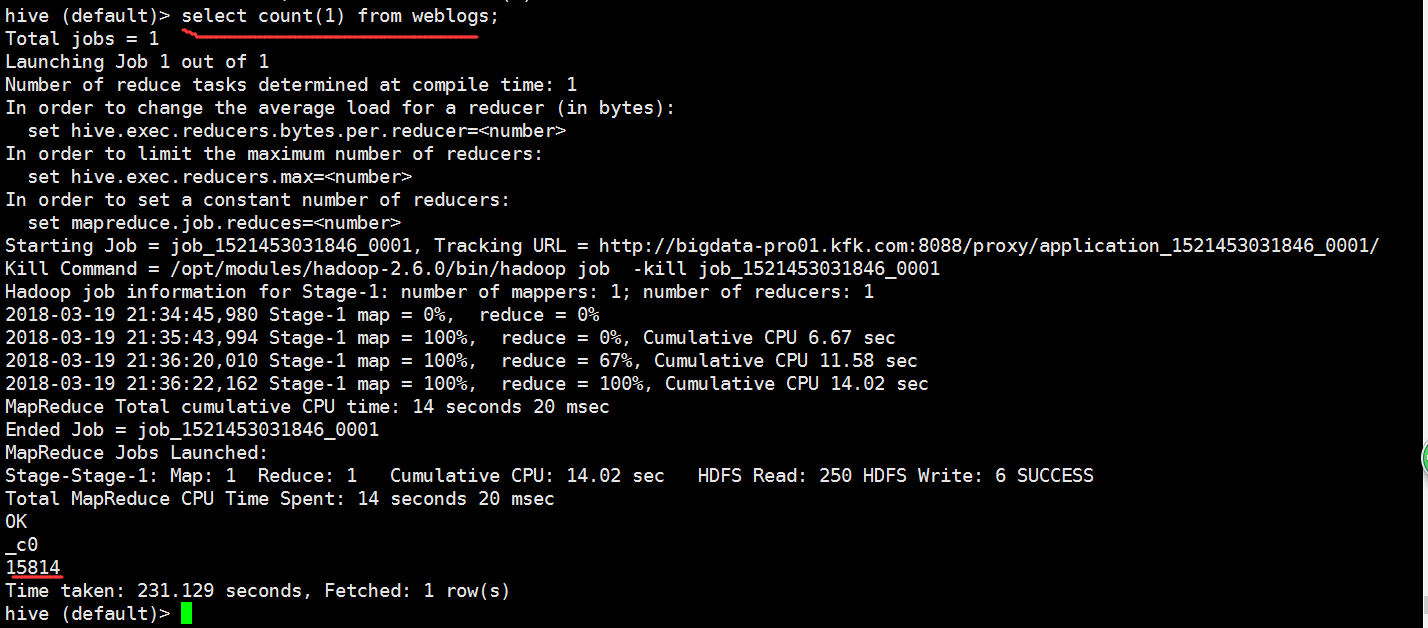
可以看到统计的结果是一样的,证明我们的spark和hbase的集成是成功了