新建AccessLogDriverCluster类

package com.it19gong.clickproject; import java.sql.PreparedStatement; import java.util.ArrayList; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.VoidFunction; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.Row; import org.apache.spark.sql.RowFactory; import org.apache.spark.sql.SQLContext; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; public class AccessLogDriverCluster { static DBHelper db1=null; public static void main(String[] args) throws Exception { // 创建SparkConf、JavaSparkContext、SQLContext SparkConf conf = new SparkConf() .setAppName("RDD2DataFrameProgrammatically"); JavaSparkContext sc = new JavaSparkContext(conf); SQLContext sqlContext = new SQLContext(sc); // 第一步,创建一个普通的RDD,但是,必须将其转换为RDD<Row>的这种格式 //获取昨天时间 JavaRDD<String> lines = sc.textFile("hdfs://node1/data/clickLog/2019/08/31"); // 分析一下 // 它报了一个,不能直接从String转换为Integer的一个类型转换的错误 // 就说明什么,说明有个数据,给定义成了String类型,结果使用的时候,要用Integer类型来使用 // 而且,错误报在sql相关的代码中 // 所以,基本可以断定,就是说,在sql中,用到age<=18的语法,所以就强行就将age转换为Integer来使用 // 但是,肯定是之前有些步骤,将age定义为了String // 所以就往前找,就找到了这里 // 往Row中塞数据的时候,要注意,什么格式的数据,就用什么格式转换一下,再塞进去 JavaRDD<Row> clickRDD = lines.map(new Function<String, Row>() { private static final long serialVersionUID = 1L; @Override public Row call(String line) throws Exception { String itr[] = line.split(" "); String ip = itr[0]; String date = AnalysisNginxTool.nginxDateStmpToDate(itr[3]); String url = itr[6]; String upFlow = itr[9]; return RowFactory.create( ip, date, url, Integer.valueOf(upFlow) ); } }); // 第二步,动态构造元数据 // 比如说,id、name等,field的名称和类型,可能都是在程序运行过程中,动态从mysql db里 // 或者是配置文件中,加载出来的,是不固定的 // 所以特别适合用这种编程的方式,来构造元数据 List<StructField> structFields = new ArrayList<StructField>(); structFields.add(DataTypes.createStructField("ip", DataTypes.StringType, true)); structFields.add(DataTypes.createStructField("date", DataTypes.StringType, true)); structFields.add(DataTypes.createStructField("url", DataTypes.StringType, true)); structFields.add(DataTypes.createStructField("upflow", DataTypes.IntegerType, true)); StructType structType = DataTypes.createStructType(structFields); // 第三步,使用动态构造的元数据,将RDD转换为DataFrame DataFrame studentDF = sqlContext.createDataFrame(clickRDD, structType); // 后面,就可以使用DataFrame了 studentDF.registerTempTable("log"); DataFrame sumFlowDF = sqlContext.sql("select ip,sum(upflow) as sum from log group by ip order by sum desc"); db1=new DBHelper(); final String sql="insert into upflow(ip,sum) values(?,?) "; sumFlowDF.javaRDD().foreach(new VoidFunction<Row>() { @Override public void call(Row t) throws Exception { // TODO Auto-generated method stub PreparedStatement pt = db1.conn.prepareStatement(sql); pt.setString(1,t.getString(0)); pt.setString(2,String.valueOf(t.getLong(1))); pt.executeUpdate(); } });; } }
打包


报错

删除apptest文件

再次打包
把打好的包拷贝出来

并且重命名


vim project.sh
/opt/modules/spark-1.5.1-bin-hadoop2.6/bin/spark-submit --class com.it19gong.clickproject.AccessLogDriverCluster --num-executors 3 --driver-memory 100m --executor-memory 100m --executor-cores 3 --files /opt/modules/hive/conf/hive-site.xml --driver-class-path /opt/modules/hive/lib/mysql-connector-java-5.1.28.jar /home/hadoop/sparkproject.jar
把原来的包删除

上传新的包

执行脚本


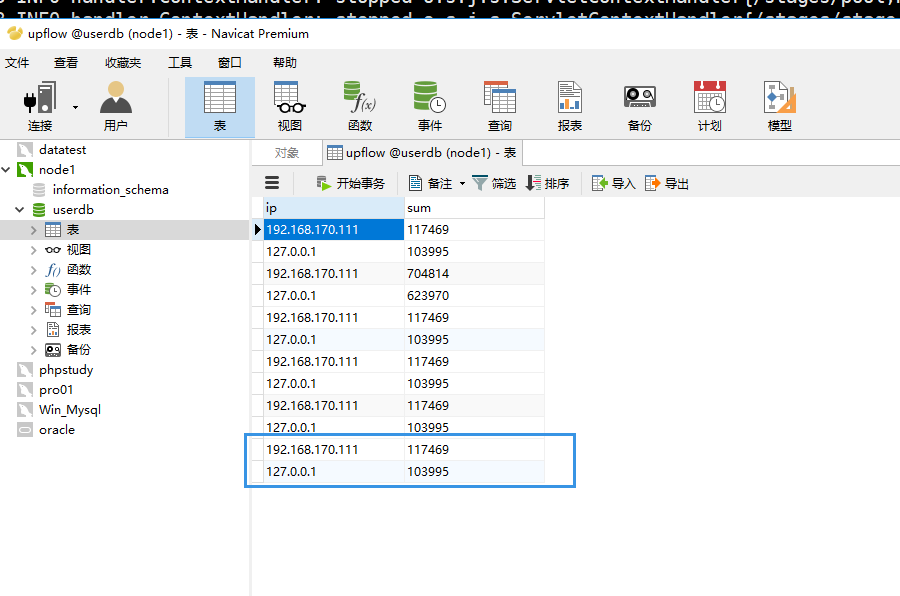
mysql数据多了两条
打开azkaban的页面,这里再次提醒要用谷歌浏览器
新建spark.job文件
#command.job type=command command=bash project.sh
打包成zip包





上传zip包

开始执行


mysql数据库多了两天数据

到此为止整个项目结束了,由于本次项目中途事情比较多,所以从开始到结束花的时间比较长,请谅解!!!