RDD转换为DataFrame
为什么要将RDD转换为DataFrame?因为这样的话,我们就可以直接针对HDFS等任何可以构建为RDD的数据,使用Spark SQL进行SQL查询了。
这个功能是无比强大的。想象一下,针对HDFS中的数据,直接就可以使用SQL进行查询。
Spark SQL支持两种方式来将RDD转换为DataFrame。
第一种方式,是使用反射来推断包含了特定数据类型的RDD的元数据。
这种基于反射的方式,代码比较简洁,当你已经知道你的RDD的元数据时,是一种非常不错的方式。
第二种方式,是通过编程接口来创建DataFrame,你可以在程序运行时动态构建一份元数据,然后将其应用到已经存在的RDD上。
这种方式的代码比较冗长,但是如果在编写程序时,还不知道RDD的元数据,只有在程序运行时,才能动态得知其元数据,那么只能通过这种动态构建元数据的方式。
Java版本:Spark SQL是支持将包含了JavaBean的RDD转换为DataFrame的。JavaBean的信息,就定义了元数据。
Spark SQL现在是不支持将包含了嵌套JavaBean或者List等复杂数据的JavaBean,作为元数据的。只支持一个包含简单数据类型的field的JavaBean。
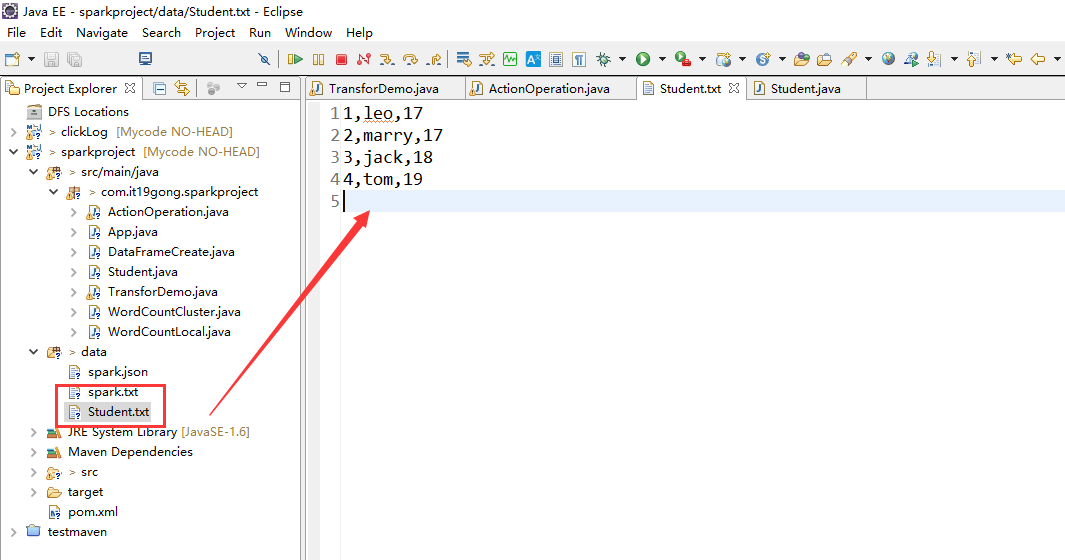
创建数据文件
创建Student对象
package com.it19gong.sparkproject; import java.io.Serializable; public class Student implements Serializable { private static final long serialVersionUID = 1L; private int id; private String name; private int age; public Student(){} public Student(int id, String name, int age) { super(); this.id = id; this.name = name; this.age = age; } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Student [id=" + id + ", name=" + name + ", age=" + age + "]"; } }
创建RDD2DataFrameReflection类
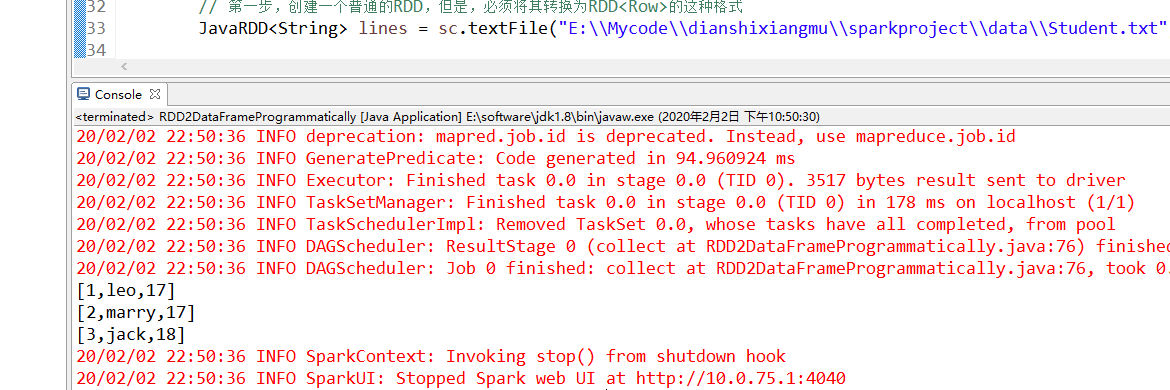
package com.it19gong.sparkproject; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.Row; import org.apache.spark.sql.SQLContext; public class RDD2DataFrameReflection { public static void main(String[] args) { // 创建普通的RDD SparkConf conf = new SparkConf() .setMaster("local") .setAppName("RDD2DataFrameReflection"); JavaSparkContext sc = new JavaSparkContext(conf); SQLContext sqlContext = new SQLContext(sc); JavaRDD<String> lines = sc.textFile("E:\Mycode\dianshixiangmu\sparkproject\data\Student.txt"); JavaRDD<Student> students = lines.map(new Function<String, Student>() { private static final long serialVersionUID = 1L; @Override public Student call(String line) throws Exception { String[] lineSplited = line.split(","); Student stu = new Student(); stu.setId(Integer.valueOf(lineSplited[0].trim())); stu.setName(lineSplited[1]); stu.setAge(Integer.valueOf(lineSplited[2].trim())); return stu; } }); // 使用反射方式,将RDD转换为DataFrame // 将Student.class传入进去,其实就是用反射的方式来创建DataFrame // 因为Student.class本身就是反射的一个应用 // 然后底层还得通过对Student Class进行反射,来获取其中的field // 这里要求,JavaBean必须实现Serializable接口,是可序列化的 DataFrame studentDF = sqlContext.createDataFrame(students, Student.class); // 拿到了一个DataFrame之后,就可以将其注册为一个临时表,然后针对其中的数据执行SQL语句 studentDF.registerTempTable("students"); // 针对students临时表执行SQL语句,查询年龄小于等于18岁的学生,就是teenageer DataFrame teenagerDF = sqlContext.sql("select * from students where age<= 18"); // 将查询出来的DataFrame,再次转换为RDD JavaRDD<Row> teenagerRDD = teenagerDF.javaRDD(); // 将RDD中的数据,进行映射,映射为Student JavaRDD<Student> teenagerStudentRDD = teenagerRDD.map(new Function<Row, Student>() { private static final long serialVersionUID = 1L; @Override public Student call(Row row) throws Exception { // row中的数据的顺序,可能是跟我们期望的是不一样的! Student stu = new Student(); stu.setAge(row.getInt(0)); stu.setId(row.getInt(1)); stu.setName(row.getString(2)); return stu; } }); // 将数据collect回来,打印出来 List<Student> studentList = teenagerStudentRDD.collect(); for(Student stu : studentList) { System.out.println(stu); } } }
运行代码

当JavaBean无法预先定义和知道的时候,比如要动态从一个文件中读取数据结构,那么就只能用编程方式动态指定元数据了。
首先要从原始RDD创建一个元素为Row的RDD;其次要创建一个StructType,来代表Row;最后将动态定义的元数据应用到RDD<Row>上。
创建RDD2DataFrameProgrammatically类
package com.it19gong.sparkproject; import java.util.ArrayList; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.DataFrame; import org.apache.spark.sql.Row; import org.apache.spark.sql.RowFactory; import org.apache.spark.sql.SQLContext; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; /** * 以编程方式动态指定元数据,将RDD转换为DataFrame * @author Administrator * */ public class RDD2DataFrameProgrammatically { public static void main(String[] args) { // 创建SparkConf、JavaSparkContext、SQLContext SparkConf conf = new SparkConf() .setMaster("local") .setAppName("RDD2DataFrameProgrammatically"); JavaSparkContext sc = new JavaSparkContext(conf); SQLContext sqlContext = new SQLContext(sc); // 第一步,创建一个普通的RDD,但是,必须将其转换为RDD<Row>的这种格式 JavaRDD<String> lines = sc.textFile("E:\Mycode\dianshixiangmu\sparkproject\data\Student.txt"); // 分析一下 // 它报了一个,不能直接从String转换为Integer的一个类型转换的错误 // 就说明什么,说明有个数据,给定义成了String类型,结果使用的时候,要用Integer类型来使用 // 而且,错误报在sql相关的代码中 // 所以,基本可以断定,就是说,在sql中,用到age<=18的语法,所以就强行就将age转换为Integer来使用 // 但是,肯定是之前有些步骤,将age定义为了String // 所以就往前找,就找到了这里 // 往Row中塞数据的时候,要注意,什么格式的数据,就用什么格式转换一下,再塞进去 JavaRDD<Row> studentRDD = lines.map(new Function<String, Row>() { private static final long serialVersionUID = 1L; @Override public Row call(String line) throws Exception { String[] lineSplited = line.split(","); return RowFactory.create( Integer.valueOf(lineSplited[0]), lineSplited[1], Integer.valueOf(lineSplited[2])); } }); // 第二步,动态构造元数据 // 比如说,id、name等,field的名称和类型,可能都是在程序运行过程中,动态从mysql db里 // 或者是配置文件中,加载出来的,是不固定的 // 所以特别适合用这种编程的方式,来构造元数据 List<StructField> structFields = new ArrayList<StructField>(); structFields.add(DataTypes.createStructField("id", DataTypes.IntegerType, true)); structFields.add(DataTypes.createStructField("name", DataTypes.StringType, true)); structFields.add(DataTypes.createStructField("age", DataTypes.IntegerType, true)); StructType structType = DataTypes.createStructType(structFields); // 第三步,使用动态构造的元数据,将RDD转换为DataFrame DataFrame studentDF = sqlContext.createDataFrame(studentRDD, structType); // 后面,就可以使用DataFrame了 studentDF.registerTempTable("students"); DataFrame teenagerDF = sqlContext.sql("select * from students where age<=18"); List<Row> rows = teenagerDF.javaRDD().collect(); for(Row row : rows) { System.out.println(row); } } }
运行代码