一、任务队列(Task Queues)
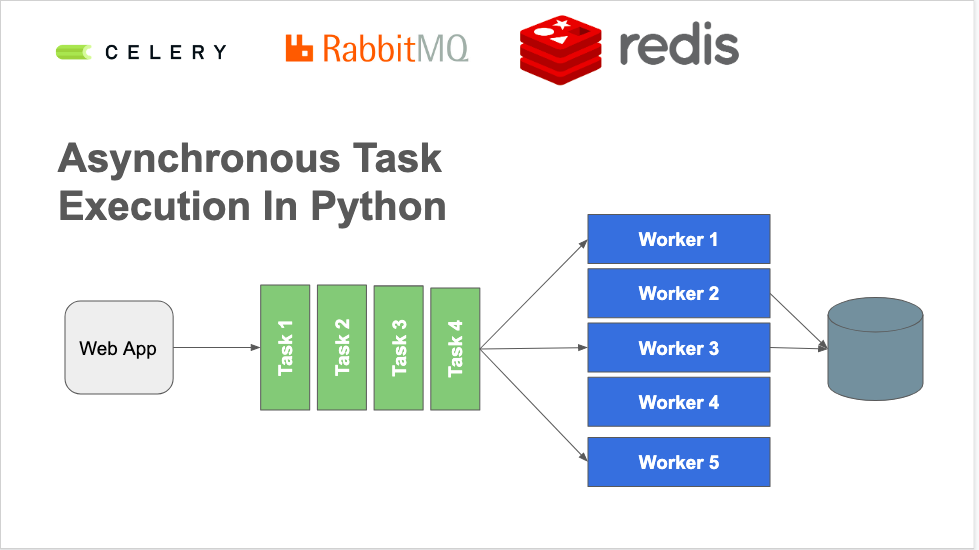
1.1 什么是任务队列?
任务队列用于管理后台工作,通常这些后台工作必须在 HTTP请求-响应循环 之外执行。
1.2 为什么需要任务队列?
对于那些不是由客户端HTTP请求产生的任务,或是需要长时间运行的作业,会大大降低HTTP响应的性能,所以这些请求需要异步处理。
示例一:一个Web应用程序可以每10分钟轮询一次GitHub API,以收集前100个加星标存储库的名称。任务队列将处理调用代码以调用GitHub API、处理结果、并将其存储在持久数据库中以供以后使用。
示例二:在HTTP请求-响应周期内数据库查询花费的时间太长时。查询可以在后台以固定间隔执行,结果存储在数据库中。当收到一个需要这些结果的HTTP请求时,查询将简单地获取预先计算的结果,而不是重新执行较长的查询。这种预计算方案是任务队列启用的一种缓存形式。
任务队列的其他类型的作业包括
-
随着时间的流逝散布大量独立的数据库插入,而不是一次插入所有内容
-
以固定的时间间隔(例如每15分钟)聚合收集的数据值
-
安排诸如批处理之类的定期作业
1.2 常用的任务队列
事实上的标准Python任务队列是Celery。其他任务队列项目的出现,主要是因为对于简单的使用场景而言Clelery还是有点繁琐。所以重点还是在Celery。
此外还可以使用第三方的任务队列服务,用于解决在大规模部署分布式任务队列时出现的复杂问题。

二、Celery架构及其工作原理概述
运行异步任务的问题可以轻松地映射到经典的生产者/消费者问题问题。生产者将作业排在队列中。消费者然后检查队列中的头以等待作业,选择第一个并执行。
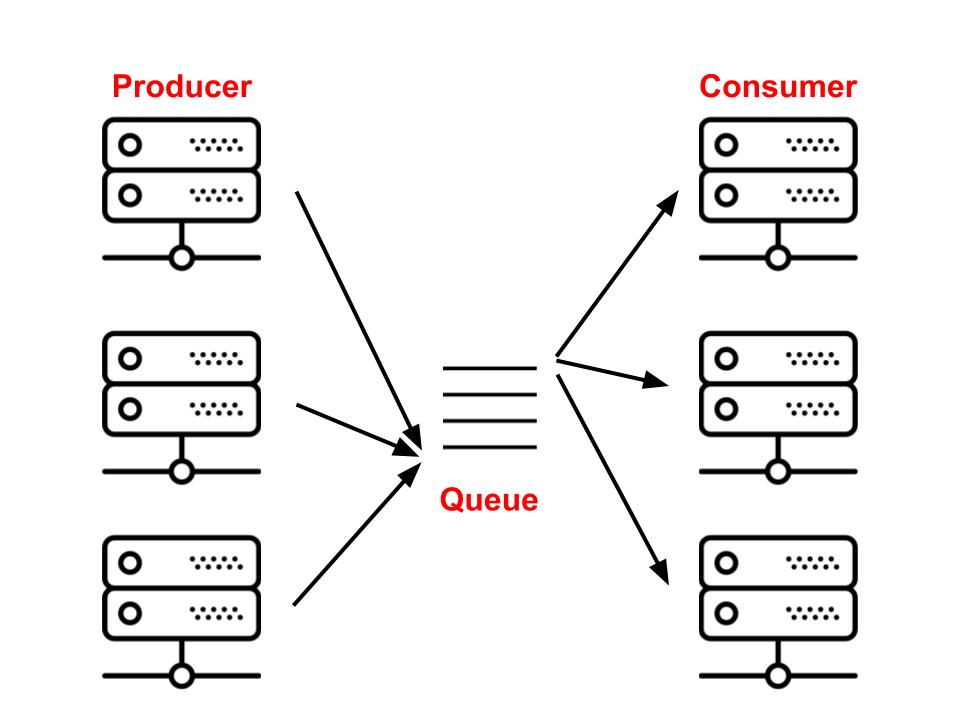
在上面的异步任务队列中,生产者通常是web节点或其他发放任务的系统,队列称为broker,消费者称为workers。而workers也可以发布任务到队列中,这时候它就成了“生产者”。现在我们已经对任务队列有一个概览了,接下来再挖深一点。
2.1 Broker
broker也常译为中间人,其实就是一个队列。但是在计算机系统中实现一个队列的方法有很多。最简单的方式就是使用文本文件。文本文件可以包含要执行的一系列工作描述,因此,我们可以将它们用作系统的代理。文本文件的问题在于它们不能处理实际的应用程序问题,例如网络和并发访问。因此,我们需要更强大的功能。
另一方面,SQL数据库能够在网络中运行并处理并发访问。它们的问题在于它们太慢。相比之下,NoSQL数据库的速度相当快,但是很多时候它们缺乏可靠性。
因此,在构建队列时,我们应该使用快速,可靠,并发启用的工具,例如RabbitMQ,Redis和SQS。
Celery完全支持RabbitMQ和Redis。尽管也可以使用SQS和Zookeeper,但它们提供的功能有限。
2.2 Web节点 和 Workers
web节点和workers都是普通的服务,他们的不同仅仅是:web节点接收客户端请求,然后发布需要异步处理的任务;而workers服务接收这些任务,执行并提供反馈。
尽管他们的执行逻辑不同,但一般这两者的代码都放在同一个项目仓库中,这样做两个应用程序都可以受益于共享模型和服务之类的东西,还可以防止这些模型和服务不一致。
2.3 执行一个异步任务
# worker node:
from celery import Celery
app = Celery(...)
@app.task
def add(a, b):
return a + b
# web node:
from tasks import add
r = add.delay(4, 5).get()
print(r) # 9
上面分别是 异步任务需要运行的代码 和 将作业放置在要运行的队列中的代码。在此示例中,Web节点放置一个作业,并等待直到结果可用。响应的结果到来后,将打印结果。
2.4 Results Backend
在前面的示例中,我们将一起调用delay和get函数。实际上,它们是两个独立的事物。delay将任务放在队列中并返回一个promise,该promise可用于监视状态并在准备就绪时获取结果。调用get该promise将阻塞执行(block the execution),直到结果可用为止。
这个add任务必须将结果存储在某个位置,以便随后触发它的进程可以对其进行访问。这意味着我们错过了一部分架构。除了web,broker和worker组件,还有一个results backend。
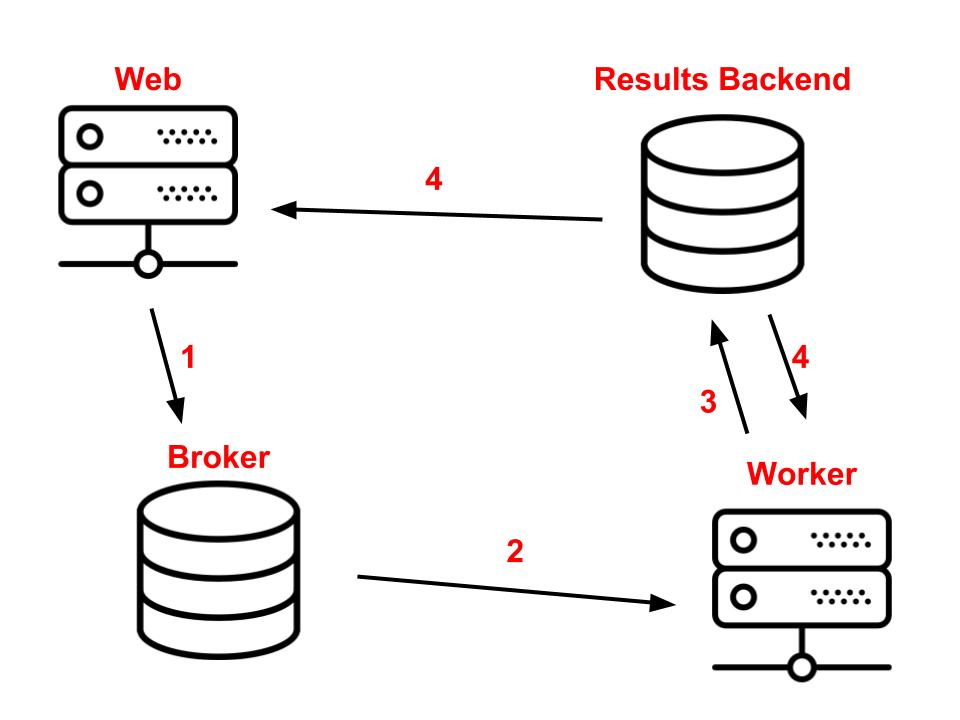
Results Backend 用于存储任务结果。其实也可以使用另一个broker来存储结果。除了受支持的代理选项以外,还有其他技术可以用作Celery中的Results Backend,但是根据使用的内容,会有一些差异。例如,在Postgres中,该get方法将进行轮询以检查结果是否准备就绪。对于其他工具,例如Redis,则是通过pub / sub协议完成的。