本文目的
最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken)。感觉需要记录点什么,才对得起自己。下面的内容主要是关于Spark核心—RDD的相关的使用经验和原理介绍,作为个人备忘,也希望对读者有用。
为什么选择Spark
原因如下
- 代码复用:使用Scala高级语言操作Spark,灵活方便,面向对象,函数编程的语言特性可以全部拿来。Scala基本上可以无缝集成java及其相关库。最重要的是,可以封装组件,沉淀工作,提高工作效率。之前用hive + python的方式处理数据,每个处理单元是python文件,数据处理单元之间的交互是基于数据仓库的表格,十分不灵活,很难沉淀常见的工作。
- 机器学习:Spark可以实现迭代逻辑,可以轻松实现一些常见的机器学习算法,而且spark自带机器学习库mllib和图算法包graphyx,为后面的数据挖掘应用提供了想象空间。
Spark计算性能虽然明显比Hadoop高效,但并不是我们技术选型的主要原因,因为现有基于Hadoop +hive的计算性能已经足够了。
基石哥—RDD
整个spark衍生出来的工具都是基于RDD(Resilient Distributed Datesets),如图:
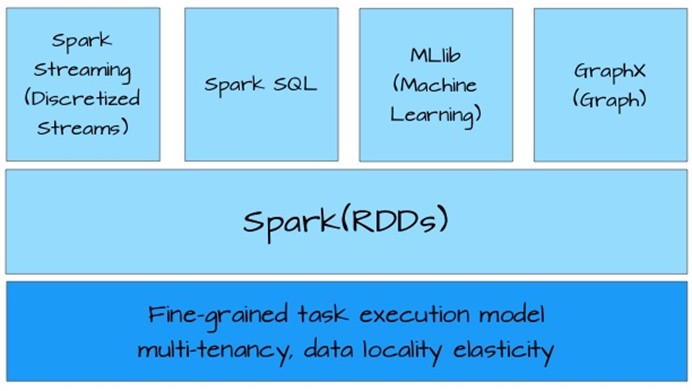
RDD是一个抽象的数据集,提供对数据并行和容错的处理。初次始使用RDD时,其接口有点类似Scala的Array,提供map,filter,reduce等操作。但是,不支持随机访问。刚开始不太习惯,但是逐渐熟悉函数编程和RDD 的原理后,发现随机访问数据的场景并不常见。
为什么RDD效率高
Spark官方提供的数据是RDD在某些场景下,计算效率是Hadoop的20X。这个数据是否有水分,我们先不追究,但是RDD效率高的由一定机制保证的:
- RDD数据只读,不可修改。如果需要修改数据,必须从父RDD转换(transformation)到子RDD。所以,在容错策略中,RDD没有数据冗余,而是通过RDD父子依赖(血缘)关系进行重算实现容错。
- 多个RDD操作之间,数据不用落地到磁盘上,避免不必要的I/O操作。
- RDD中存放的数据可以是java对象,所以避免的不必要的对象序列化和反序列化。
总而言之,RDD高效的主要因素是尽量避免不必要的操作和牺牲数据的操作精度,用来提高计算效率。
闭包外部变量访问原则
RDD相关操作都需要传入自定义闭包函数(closure),如果这个函数需要访问外部变量,那么需要遵循一定的规则,否则可能会出现异常。闭包函数传入到节点时,需要经过下面的步骤:
- 使用反射机制,找到所有需要访问的变量,并封装到对象中,然后序列化
- 将序列化后的对象通过网络传输到其他节点上
- 反序列化闭包对象
- 子指定节点执行闭包函数,外部变量在闭包内的修改不会被反馈到驱动程序。
简而言之,就是通过网络,传递函数,然后执行。所以,被传递的对象必须可以序列化和反序列化,否则传递失败。单机本地执行时,仍然会执行上面四步。
广播机制也可以做到这一点,但是频繁的使用广播会使代码不够简洁,而且广播设计的初衷是将较大数据缓存到节点上,避免多次数据传输,提高计算效率,而不是用于进行外部变量访问。
参考资料