基于 Flink 构建关联分析引擎的挑战和实践
随着云计算、大数据等新一代IT技术在各行业的深入应用,政企机构IT规模和复杂程度不断提高,网络流量、日志等各类数据规模大幅提升。与此同时,网络攻防日益激烈,网络安全威胁逐渐凸显出来,这对于SOC/SIEM产品的性能提出了一个很大的挑战。因此,奇安信独立研发了国内首款流式分布式关联分析引擎Sabre,搭载于公司旗下态势感知与安全运营平台(下文简称NGSOC),从而大幅提升NGSOC的数据分析能力和网络安全检测能力。
本文将从技术研发的角度,全面阐述Sabre的由来。
1.Sabre是什么?
Sabre是奇安信研发的新一代流式分布式关联分析引擎,是CEP(Complex Event Processing,复杂事件处理)技术在大数据领域的一个具体实现。奇安信研发关联引擎已有数年历史,中间经历了三次主要的技术演进,在2015年之前,奇安信使用的是基于开源CEP软件Esper研发的关联引擎,由于一些架构和设计上的问题,整体性能不是非常理想,也不支持多机扩展;在2016-2017年,用C++开发了一个高性能引擎,代号Dolphin,可以在单机上实现很高的性能;在2018年,从技术上全面转向Flink框架,极大增强了系统的可扩展性,推出了Sabre引擎作为NGSOC的核心检测引擎。
Sabre应用于奇安信的态势感知与安全运营平台(NGSOC)产品中,NGSOC主要服务于中大型政企客户,目前已经成功应用于200+大型政企机构,在国内安全管理平台市场占有率第一,其中搭载的Sabre引擎提供了核心的安全检测能力。和很多互联网公司内部自建数据处理平台不同的是,Sabre更注重的是技术的工程化交付,因此在设计和实现上和一般基于Flink的业务系统相比会有较大差异。
2.为什么要开发Sabre?
随着网络应用规模和复杂度的不断提高,网络中传输的数据量急剧上升,网络攻防对抗日趋激烈,企业内部新的安全问题开始显现,实时关联分析引擎,作为NGSOC检测体系中的核心组件,也遇到了越来越多的挑战:
(1) 性能优化问题。主要针对随着新型攻击的不断出现,关联分析规则规模不断上升导致的性能问题。传统开源关联引擎往往加载几十条规则即达到了性能瓶颈,而NGSOC的应用场景中,关联引擎需要支撑规模上千的关联规则。在有限的硬件资源条件下,如何避免系统整体性能随规则条数上升而发生线性下降,成为关联引擎的一个主要挑战。
(2) 规则的语义扩展问题。在网络安全事件井喷式发生的今天,安全需求迅速扩展。为了能够在有限时间内对特定语义的快速支持,关联引擎的整体架构必须异常灵活,才能适应未来安全分析场景的各种需求,而基于开源关联引擎实现的产品会在激烈的需求变化时遇到很多问题。
(3) 系统扩展性问题。主要指分布式环境下节点的扩展。随着企业网络流量和业务资产的不断扩容,NGSOC的系统处理能力必须能随企业业务规模的不断扩张而动态扩展。未来的分布式关联分析引擎需要支持数百节点的规模,以能够与现有的大数据平台无缝集成。
与Storm、Spark Streaming等流式计算框架相比,Flink具有编程接口丰富、自带多种Window算子、支持Exactly-Once、高性能分布式检查点、批流计算模式统一等优点。且Flink发展较为迅速,开源社区极为活跃,是目前最具发展潜力的流式计算框架,是未来实时计算执牛耳者。由于Flink为事件驱动的实时关联分析引擎在底层框架上提供了有力支持,因此奇安信的下一代关联分析引擎Sabre是基于Flink流式计算框架实现的。
在选择了Flink之后,发现Flink开源方案直接应用于安全检测领域,仍有很大的技术障碍。
和互联网企业内部使用的大型集群相比,NGSOC面向的企业级应用集群规模较小,硬件资源受限,且客户的定制需求较多,导致安全监测的规则要求更严格,引擎发布成本较高。但是,现有的Flink开源解决方案,或者需要根据业务需求进行改造,或者性能较差,均不能较好地解决上述问题。首先,原生Flink只提供了函数式编程模式,即需要直接编写复合特定业务需求的固定程序代码,由此导致开发测试周期较长,不便于动态更新规则,可复用性较弱,且不能从全局语义层面进行优化,性能较差。其次,Flink-CEP仅是一个受限的序列算子,在运行时需要将所有数据传输到CEP算子,然后在CEP算子中串行执行各个条件语句。这种汇集到单点的运行模式,较多的冗余数据需要执行条件匹配,产生了不必要的网络负载,而且降低了CPU利用率。再次,还存在一些非官方开源的轻量级CEP引擎,比如Flink-siddhi,功能简单,不是一个完整的解决方案。
面向企业级的网络安全监测引擎具有一些特定需求,当前解决方案对此支持较差。比如,现实情况,客户对算子实例和Taskmanager概念较为模糊,真正关心的运行状态的基本单位是规则。而Flink监控页面显示的是算子实例及Taskmanager进程整体内存的运行状态,而在网络安全监控的业务场景中,对运行状态和资源的监控均需要细化到规则层面。其次,在算子层面,Flink原生Window算子,没有较好的资源(CPU/内存)保护机制,且存在大量重复告警,不符合网络安全监测领域的业务需求。再次,Flink缺乏一些必要算子,例如不支持“不发生算子”。一个较为常见的应用场景,某条规则指定在较长时间内没收到某台服务器的系统日志,则认为此台服务器发生了异常,需要及时通知用户。
综上所述,现有解决方案应用于网络安全监测领域均会遇到问题,由此奇安信集团基于Flink构建了一种全新的CEP引擎。
3.Sabre如何处理数据?

上图为NGSOC的数据处理架构图,展示了整个系统的数据流。自下而上,NGSOC的数据处理过程由四部分组成,其核心是由“流式分布式关联分析引擎Sabre”构成的数据处理层PROCESS,且Sabre运行的硬件环境是由多个节点组成的分布式集群。右侧的规则配置管理模块供专业的安全人员使用,可通过类Visio图的界面较为友好便捷地配置规则;规则管理模块具有添加、删除、编辑和查找规则的功能,并可批量启动/停用多个规则,规则管理模块会将处于启动状态的有效规则统一发送给Sabre引擎。 最上方的绿色部分为结果处理层RESULT,Sabre会将处理结果“告警”或“关联事件”发送给下级响应模块,实现响应联动、分析调查及追踪溯源等功能。最下方的蓝色部分为日志采集层COLLECT,主要有“网络流量日志采集器”、“设备及系统日志采集器”和“其他类型的日志采集器(比如:防火墙、入侵检测系统IDS、入侵防护系统IPS、高级威胁监测系统APT等等)”三大类。中间部分为日志解析层PARSE,网络流量日志和系统安全日志格式多种多样,须将上述两类原始日志数据格式化,而其他类型的日志(比如:威胁情报、漏洞、资产)本身即为格式化数据,最终所有格式化数据均需统一存储到高性能消息队列Kafka。
4.Sabre的关键技术
(1) 系统架构

上图为Sabre系统整体架构图。Sabre整体架构包含三大核心模块,中间是Sabre-server,左侧是配置端,右侧是Sabre运行端。核心数据流存在两条主线,红线表示规则的提交、编译、发布和运行流程。绿线表示状态监控的生成、收集、统计和展示流程。如图所示,此架构与Hive极为相似,是一种通用的大数据OLAP系统架构。下面详细介绍三大核心模块和两大核心数据流。
首先,通过规则配置端创建规则,采用性能保护配置端修改性能保护策略,然后将任务所属的规则文件和性能保护策略文件一并推送到Sabre-server提供的REST接口,该接口会调用文件解析及优化方法构建规则有向无环图。接着执行词法语法分析方法,将规则有向无环图中各个节点的EPL转换为与其对应的AST(Abstract Syntax Tree,抽象语法树),再将AST翻译为任务java代码。最后调用maven命令打包java代码为任务jar包,并将任务jar包及基础运行库一并提交到Flink-on-YARN集群。
Flink有多种运行模式(例如 standalone Flink cluster、Flink cluster on YARN、Flink job on YARN等),Sabre采用了“Flink job on YARN”模式,在奇安信NGSOC应用的特定场景下,采用YARN可统一维护硬件资源,并且使用 Flink job on YARN 可与Hadoop平台进行无缝对接,以此实现了很好的任务间资源隔离。
在Sabre任务执行过程中,Kafka数据源向引擎提供原始事件。引擎处理结果分为回注事件和告警事件两类。告警事件会直接输出到目的Kafka,供下级应用消费。回注事件表示一条规则的处理结果可直接回注到下级规则,作为下级规则的数据源事件,由此可实现规则的相互引用。
绿线流程表示任务执行过程中会定时输出节点的运行监控消息到Sabre-server的监控消息缓存器,然后监控消息统计器再汇总各个规则实例的运行监控消息,统计为整条规则的运行监控状态,最后通过Sabre-server提供的REST接口推送给规则监控端。
(2) 功能设计
算子的设计和实现是构建CEP的重要组成部分。

上图展示了Flink和Sabre算子的比较关系。包含三列:Flink原生算子、Sabre算子、两者之间的比较结果(相同、实现、优化、新增)。Sabre共有13种完全自研的核心算子,其中Datasource、CustomKafkaSink和CustomDatabase按照 Flink接口要求做了具体实现,Filter、Key、Join和Aggregation按照Flink原有算子的语义做了重新实现,CustomWindow和Sequence在Flink原有算子语义的基础上做了优化实现。
由于Flink原有FilterFunction算子只能简单返回布尔值,以致输出结果的控制能力较差,而重新实现的Filter算子可同时执行多种业务逻辑,将一个“原始事件”输出一个或多个“处理事件”。Sabre还实现了一种针对窗口的全局触发器Trigger,Trigger能够将多个子计算性算子组合为复杂表达式,并实现了具有GroupBy/Distinct功能的Key算子以适配此Trigger算子。众所周知,Join和Aggregation的时间范围由Window限定,而Flink原有Window算子不适合网络安全监测需求,为此Sabre设计了一种“自定义Window算子”,且重新实现了与“自定义Window算子”相匹配的Join和Aggregation算子。

上图展示了Sabre算子间的关联关系。序列Sequence、聚合Aggregation、不发生NotOccur、流式机器学习StreamML和连接Join均属于Window执行时间包含的计算性算子。蓝色虚线表示引用动态数据,紫色虚线表示Filter无须经过Window可直连输出组件。

如上图所示,为满足复杂场景需求,一种规则的输出可直接作为另一种规则的输入。通过这种规则拆分的方式,能分层构造较为复杂的“多级规则”。如:上面的“暴力探测”规则结果可以直接回注到下面的“登陆成功 ”规则,而无须额外的通信组件。
(3) 性能优化
因为采用了Flink作为底层运行组件,所以Sabre具有与Flink等同的执行性能。并且,针对网络安全监测领域的特定需求,还做了如下的性能优化工作:
1)全局组件(数据源、动态表)引用优化。由于Kafka类型的数据源topic有限,而规则数量可动态扩展,导致多个规则会有极大概率共用同一个数据源,根据EPL语义等价原则合并相同的数据源,进而可以减少数据输入总量及线程总数。
2)全新的匹配引擎。序列Sequence算子采用了新颖的流式状态机引擎,复用了状态机缓存的状态,提升了匹配速度。类似优化还包含大规模IP匹配引擎和大规模串匹配引擎。
3)表计算表达式优化。对于规则中引用的动态表,会根据表达式的具体特性构建其对应的最优计算数据结构,以避免扫描全表数据,进而确保了执行的时间复杂度为常量值。
4)自定义流式Window算子。采用“时间槽”技术实现了乱序纠正功能,并具有可以实时输出无重复、无遗漏告警的特性。
5)字段自动推导,优化事件结构。根据规则前后逻辑关系,推导出规则中标注使用的原始日志相关字段,无须输出所有字段,以此优化输出事件结构,减少输出事件大小。
6)数据分区自动推导,优化流拓扑。由于功能需要,Window往往会缓存大量数据,以致消耗较多内存。通过对全局窗口Hash优化,避免所有全局窗口都分配到同一个Taskmanager进程,由此提高了引擎整体内存的利用率。
(4) 机器学习
机器学习在网络异常检测上已经越来越重要,为适应实时检测的需求,Sabre没有使用Flink MachineLearning,而是引入了自研的流式机器学习算子StreamML。Flink MachineLearning是一种基于批模式DataSetApi实现的机器学习函数库,而StreamML是一种流式的机器学习算子,其目的是为了满足网络安全监测的特定需求。与阿里巴巴开源的Alink相比,StreamML允许机器学习算法工程师通过配置规则的方式即可快速验证算法模型,无需编写任何程序代码。并且,流式机器学习算子StreamML实现了“模型训练/更新”与“模型使用”统一的理念。其核心功能是通过算法、技术及模型实现数据训练及对新数据检测。该流式机器学习算子StreamML引入的输入有三类,分别是:事件流、检测对象和对象属性;输出也包含三类,分别是:事件、告警和预警。

流式机器学习算子StreamML的组件栈包含三部分,从下往上依次为:机器学习方法、应用场景和产品业务。通过基本的机器学习算法(比如:统计学习算法、序列分析算法、聚类分析算法),流式机器学习算子StreamML可满足具体特定的安全监测应用场景(比如:行为特征异常检测、时间序列异常检测、群组聚类分析),进而为用户提供可理解的产品业务(比如:基线、用户及实体行为分析UEBA)。
行为特征异常检测:根据采集的样本数据(长时间)对统计分析对象建立行为基线,并以此基线为准,检测发现偏离正常行为模式的行为。例如:该用户通常从哪里发起连接?哪个运营商?哪个国家?哪个地区?这个用户行为异常在组织内是否为常见异常?
时间序列异常检测:根据某一个或多个统计属性,判断按时间顺序排列的数值序列是否异常,由此通过监测指标变化来发现安全事件。例如:监测某网站每小时的访问量以防止DDOS攻击;建模每个账号传输文件大小的平均值,检测出传输文件大小的平均值离群的账号。
群组聚类分析:对数据的特征属性间潜在相关性进行挖掘,将具有类似特征值的数据进行分组聚类。例如:该用户是否拥有任何特殊特征?可执行权限/特权用户?基于执行的操作命令和可访问的实体,来识别IT管理员、DBA和其它高权限用户。
5.Sabre如何快速适配复杂的客户环境?
由于客户规模较大,项目种类较多,部署环境较为复杂,或者存在多种Yarn集群版本,或者Sabre需作为单一Flink应用发布到客户已部署的Flink集群。如何节省成本及提高实施效率,快速适配上述复杂的部署环境是个亟需解决的问题,为此Sabre的设计原则是仅采用Flink的分布式计算能力,业务代码尽可能减少对API层的依赖,以便于兼容多种Flink版本。如图所示,Deploy、Core、APIs、Libraries四层是大家熟知的Flink基本的组件栈。Sabre对API层的依赖降到了最低,只引用了DataStream、KeyedStream和SplitStream三种数据流API。函数依赖则包括DataStream的assignTimestamps、flatMap、union、keyBy、split、process、addSink等函数,KeyedStream最基础的process函数,以及SplitStream的select函数。由于依赖的Flink API较少,Sabre可以很容易适配到各个Flink版本,从而具有良好的Flink版本兼容性。

6.如何保障Sabre稳定运行?
为减少引擎的维护成本,需要保障引擎在超限数据量的条件下亦然能够稳定运行,Sabre主要做了两个优化:流量控制和自我保护。
为了增强Sabre引擎的健壮性,避免因规则配置错误,导致生成大量无效告警,在输出端做了流量控制,以更好地保护下级应用。当下级抗压能力较弱时(例如数据库),整个系统会做输出降级。
另一个问题是,跑在JVM上的程序,经常会遇到由于长时间 Full GC导致OOM的错误,并且此时CPU占用率往往非常高,Flink同样存在上述问题。自我保护功能采用了同时兼顾“Window隶属规则的优先级”及“Window引用规则数量”两个条件的加权算法,以此根据全局规则语义实现自动推导Window优先级,并根据此优先级确定各个Window的自我保护顺序。实时监控CPU及内存占用,当超过一定阈值时,智能优化事件分布,以防出现CPU长期过高或内存使用率过大而导致的OOM问题。
目前,基于Flink构建的Sabre引擎还在继续开发新的功能,并会持续优化引擎性能。未来将总结凝练项目中的优秀实践,并及时回馈给Apache Flink社区。
结合Flink,国内自研,大规模实时动态认知图谱平台——AbutionGraph |博文精选
作者 | Raini
出品 | 北京图特摩斯科技(www.thutmose.cn)
Flink:目前最受关注的大数据技术,最活跃 Apache 项目之一。
AbutionGraph:北京图特摩斯科技自研的国内首个准实时多维图形数据库,首个将实时/离线/指标聚合/图挖掘/AI框架等热门技术线深度整合在一起的认知图谱平台,本文仅对实时性的相关优势做分析。
AbutionGraph 具有以下主要特征:
- 为分析而设计——AbutionGraph 是为准实时的OLAP工作流的探索性分析而构建,它支持各种过滤、聚合和查询等类;
- 快速的交互式查询——AbutionGraph 的低延迟数据摄取架构允许事件在它们创建后毫秒内可被查询到;
- 高可用性——AbutionGraph 的数据在系统更新时依然可用,规模的扩大和缩小都不会造成数据丢失;
- 可扩展——AbutionGraph 已实现每天能够处理数十亿事件和TB级数据。
AbutionGraph 典型应用场景包括深度关系探索、关联分析、路径搜索、特征抽取、数据聚类、社区检测、 知识图谱、用户画像等,适用业务领域有如网络安全、电信诈骗、金融风控、广告推荐、社交网络和智能机器人等。
引言
大数据时代的到来,为收集数据带来了新的契机。传统基于Hadoop生态的离线数据存储计算方案已在业界形成统一的默契,当能够收集到的数据越来越多时,受制于离线计算的时效性制约,越来越多的数据应用场景已从离线转为实时。
随着物联网时代的逼近,“万物互联”的概念以及人工智能技术的发展一定程度的促进了知识图谱技术的发展,从2017年到2020年,知识图谱技术的使用率增长了400%,但目前市场上多以Neo4j和JanusGraph两款图形数据库为主进行业务拓展,它们难以做到稍大吞吐的准实时应用。MIT的一个性能测试报告显示,在一个8节点的集群上,Cassandra后端的单点摄入量为3.6w/s,Hbase的单点摄入量为6w/s,而今我们需要应对数倍于此摄入量的行业应用,比如一批物联网设备,一家银行、一个省级电信运营商、一款手机APP的实时交互事件等 的数据量可轻松过亿,将这些交互数据抽象成图形数据存储与计算需要我们的数据存储后端具有强大的吞吐量与稳定性,同时要求计算框架能够快速的依据历史记录得出业务指标结果。
AbutionGraph实时数据分析平台以此为背景进行设计与构建。其实现结合了实时数据流、实时指标计算、数据仓库的大吞吐等优势为一体,其端到端的架构可以直接从输入到输出进行映射,相当于一个纯经验的事物,流经数据库时,AbutionGraph内部自动做了关联计算、指标汇总等,即查即用,从而绕开数据直接解决问题,充分发挥了用大数据解决问题的作用。
既往平台的问题
AbutionGraph之所以要实现大规模准实时图形数据分析平台,是因为以往的图形数据存储平台大多数都为离线式系统,少量的实时系统也存在一些问题。比如:
- 较高的延迟,导入数据无法满足准实时查询的要求;
- 流式数据导入性能不足,无法支撑大规模的在线数据实时摄入,IO出现瓶颈;
- 批量导入数据前需要将原始数据依据Schema规整为gson/gxml等指定文件格式,数据ETL大多是高延迟且多日多步的;
- 此外,以往平台支持的数据源较为单一,无法多源数据同时入库。
实时技术选型
Apache Flink相比于Apache Spark,目前Spark的生态总体更为完善一些,且在机器学习的集成和应用性暂时领先。但作为下一代大数据引擎的有力竞争者-Flink在流式计算上有明显优势,Flink在流式计算里属于真正意义上的单条处理,每一条数据都触发计算,而不是像Spark一样的Mini Batch作为流式处理的妥协。Flink的容错机制较为轻量,对吞吐量影响较小,而且拥有图和调度上的一些优化,使得Flink可以达到很高的吞吐量。而Strom的容错机制需要对每条数据进行ack,因此其吞吐量瓶颈也是备受诟病。
鉴于如上3个通用的实时计算技术的比较,AbutionGraph选用了具有竞争力的下一代大数据技术Flink作为实时数据接入源,同时也是国内首个使用Flink作为数据源的图数据库,且为此实现了一些常用的消息组件接口:Kafka-2.0、Kafka-0.10、RocketMQ、ActiveMQ、Socket等,使用Flink作为与AbutionGraph的实时数据接入时,您可以不关注数据源有多少种,它支持任意多的不同消息组件同时对已有图形增量更新。
Ps:(AbutionGraph与Flink的结合使用可以很轻量,在单机环境下,您甚至都不需要安装部署它就可以使用这些功能,不必担心新的技术体系使系统变得臃肿)
鉴于Spark在离线批量计算、分布式机器学习的“王者”地位,技术生态也非常的完善。AbutionGraph顺其自然的将Spark作为离线计算(OLAP)平台,可将图形数据轻易的转变为Spark DataFrame/GraphFrame,反之,也可以将Spark DataFrame直接转换到AbutionGraph的图形中,这种数据源有别于Flink-即如上所说这是大批量的数据入库。此外,AbutionGraph还基于Spark构建了一个世界最丰富的分布式图挖掘算法库-AbutionGCS,它目前包含13大类60余种图算法。
实时存储结构
有了实时计算框架Flink作为多源数据的接入口,我们可能更关心数据在AbutionGraph中存储的优势在哪。
主流存储结构分析
市面上的图数据库一般采用B+树、LSM树、链表、哈希表等存储结构。No-SQL数据库一般采用LSM树,即日志结构合并树(Log-Structured Merge-Tree)作为数据结构,HBase也不例外,尽管这么做会使得读取效率在所难免地有一定下降,但换来的是高效得多的写入性能。众所周知,RDBMS一般采用B+树作为索引的数据结构,B+树对于数据读操作能很好地提高性能,但对于数据写,效率不高。这也是No-SQL数据库性能优越于传统MySQL类数据库的原因之一。
图形数据存储
我们暂且将企业应用程序中产生的每一条数据成为一个发生的事件,譬如张三与李四之间的一次通话计为一个事件,推荐系统使用到的数据本身也天然是事件关系图,比如在人和人之间做用户推荐,或者在人与物之间做物品推荐等等,都围绕着发生的事件去做业务拓展。在将每一条事件数据描述成某些实体之间的关系时,我们可以使用刚才所说的树形结构或是链表,因为那是传统且经过反复验证了的方案。
基于使用的存储结构,传统图数据库还需要在此之上构建完善的并发控制机制来管理对图中顶点/边的并发访问。这使得他们不得不在每次操作中存储一部分额外的信息(例如乐观并发控制需要的读写集、多版本并发控制产生的多份数据)或是触及一些需要竞争的资源(例如悲观并发控制中的锁),而这些都会或多或少地在访问图数据库中的数据对象时引入一定开销。
做算法的同学相信都知道有一种结构它也可以存储图形,就是邻接矩阵,我们一般在推荐系统中会遇到比较多,它面向的是一整个的大图做大量的机器学习算法迭代,得到满意的结果同时也消耗了大量的计算资源,所以邻接矩阵不适合作为永久的数据存储结构,我们只关注它在内存中的临时性能,以及它灵活可变的阵列值,且可以依据横纵坐标快速定位到行列值(即实体/关系的属性值)。
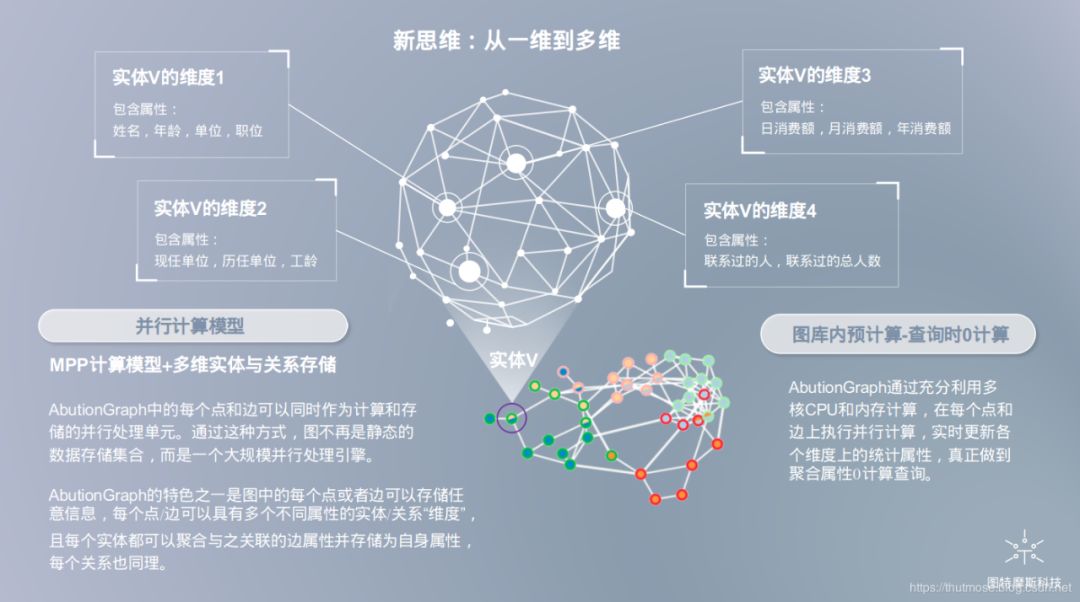
鉴于树型存储与矩阵存储的优劣势,AbutionGraph的存储设计充分的借鉴了两者的优势,采用一种新颖的架构-“动态分布式维度数据模型”,基于关联数组进行图形数据的存储,提供了的统一存储框架,该框架包含传统数据库(即SQL)和非传统数据库(即NoSQL)。
对于传统数据库的特性
存储形式举例:
普通维度的事件数据存储:
张三 -(于2020.1.1 09:00:00, 通话1分钟)-> 李四
张三 -(于2020.1.1 09:09:00, 通话2分钟)-> 李四
张三 -(于2020.1.1 11:00:00, 通话3分钟)-> 李四
张三 -(于2020.1.1 12:00:00, 通话5分钟)-> 李四
以小时为维度的统计事件存储:
张三 -(于2020.1.1 09:00:00到2020.1.1 09:59:59, 通话2次,共3分钟)-> 李四
张三 -(于2020.1.1 11:00:00到2020.1.1 11:59:59, 通话1次,共3分钟)-> 李四
张三 -(于2020.1.1 12:00:00到2020.1.1 12:59:59, 通话2次,共5分钟)-> 李四
以天为维度的统计事件存储:
张三 -(于2020.1.1 00:00:00到2020.1.1 24:59:59, 通话4次,共11分钟)-> 李四
如上所示,AbutionGraph将每一个事件以类似于传统表的形式按行存储,每一个事件又可依据该行数据的时间属性扩展出多个维度的时间序列聚合属性,即将一维(一行)数据--(深度挖掘为)-->多维(多行)数据,举例:张三今天给李四打了4次电话,这是4个事件(4行数据)。假如我们深度分析这些事件,我们还可以得到另一个维度-今天张三给李四打了4次电话,这个4次在今天这个维度里实时汇总,我们可即查即用,而不像以前需要将4个时间都提取出来后再汇总计算,即“多维度”数据模型。
AbutionGraph将存储与计算相结合,AbutionGraph中的每个点和边可以同时作为计算和存储的并行处理单元,就像我们实时汇总张三与李四的通话事件,我们不仅可以在原有维度上拓展出一个以天为汇总单位的维度,亦可以拓展出以小时、年、月为单位的维度,只要张三与李四发生通话,将立刻将汇总值更新到对应时间序列区间的维度值中。通过这种方式,图不再是静态的数据存储集合,而是一个大规模并行处理引擎。把存储后计算所耗费的大资源转变为实时计算所耗费的小资源,把离线型图数据库做成一个实时的业务型平台。即“动态”数据模型。
虽然这是种传统的行存储形式,但是您以图形三元组(实体,边属性,实体)的存储形式思考一下,仔细观察示例事件,有没有发现它们其实并不传统,张三/李四是实体,通话的次数/通话时长不就是边的属性嘛!如果您再用矩阵的思维取思考这些示例事件,张三/李四可不就是矩阵中横纵实体坐标轴中的一员嘛,而边属性就是两个实体交互所产生的具体值了。
对于非传统数据库的特性
AbutionGraph会自然的产生一个通用Schema,该Schema可用于完全索引并快速查询数据集中的每个唯一字符串,而无需像JanusGraph那样再显式的去构建数据属性索引来提高查询效率,AbutionGraph可以很友好的规避这些繁琐且不灵活的开发步骤。
AbutionGraph通过使用NoSQL的架构优势,您还可以直接像使用Hbase(实时读写的大数据OLTP引擎)那样直接将其作为一个Key-Value大数据库使用,且支持所有的Hbase功能,该特性把AbutionGraph定位为一个实时的交互图数据库平台。但Hbase的一个不足之处是无法满足超大规模的事件同时IO,可能单台服务器6w次/s即到瓶颈。
AbutionGraph的多维数据存储模式中,我们采用RoaringBitmap(一种高效的搜索技术)来快速检索基于时间序列的维度事件,加上AbutionGraph的实时属性汇总特性,对于了解Druid(准实时的多维数据仓库技术-OLAP引擎)的用户,您完全可以将AbutionGraph定位为一款相似技术,且支持所有的Druid功能,即数据仓库+知识存储平台。相较于Hbase,Druid加入的计算模型,实时性略有降低,但解决了超大规模的事件同时IO的瓶颈,更适合于大规模实时且永不停止的应用。
AbutionGraph的数据存储结构如下图所示:
鉴于AbutionGraph动态分布式维度数据存储模型的种种特性,使它可以像Druid一样对大规模的在线数据实时存储与汇总计算,又可以像Hbase一样快速的对事件保存与查询,又同时兼具传统数据库的表模式到多维三元组矩阵的映射,在面向小量事件数据的时候,AbutionGraph可以与Hbase特性相当,在面向大量事件数据的时候,AbutionGraph可以与Druid特性相当。AbutionGraph尝试结合这些独特的处理技术(稀疏线性代数,关联数组,分布式数组和三重存储/ NoSQL数据库)的优势,以提供可解决数据库和计算系统的统一问题,即大数据相关的问题。它可以直接表示复杂的关系(稀疏矩阵或图结构)。因此,使用AbutionGraph来开发复杂数据场景比于其他图数据库具有更大的效率优势。
不管场景如何,AbutionGraph都具备了一款准实时的知识图谱平台的条件,意味着可对任意数据量的事件进行存储与快速查询。这使得AbutionGraph顺理成章的成为国内第一个使用Apache Flink作为超大大规模实时事件流接入的端到端知识图谱平台,AbutionGraph在毫秒-秒之内完成图形生成后就立即可查询。
Apache Flink 在中国的应用
随着 Flink 社区的快速发展,其技术也逐渐走向成熟。Apache Flink 能够以高吞吐低延时的优异实时计算能力帮助企业和开发者实现数据算力升级,支持海量数据的亚秒级快速响应。在 2019 年末,国内已经有大量的本土互联网公司开始采用 Apache Flink 作为主流的实时计算解决方案。同时,在全球范围内,优步、网飞、微软和亚马逊等国际互联网公司也逐渐开始使用 Apache Flink。
AbutionGraph+Flink:物联网时代的应用利器
1)数据据时代的知识图谱
大数据时代的到来,催生了以知识图谱为代表的大规模知识表示,同时也为其发展奠定了必要的基础。今天这个时代谈知识工程跟 20 世纪谈专家系统有什么不同?最大的不同点是我们有前所未有的大数据、前所未有的机器学习能力以及前所未有的计算能力。这三个技术的合力作用使我们可以摆脱对专家的依赖,使实现大规模自动化知识获取成为可能,这也是大数据知识工程的根本。这一种知识获取,本质上可以称为自下而上的获取。
显然,这种数据驱动的知识获取方式与人工构建的知识获取方式完全不同。前者可以实现大规模自动化知识获取,无须高昂的人力成本。相对于人工构建的知识获取方式,数据驱动的知识获取方式是一种典型的自下而上的做法,是相对务实、实用的做法。大数据时代所发展出来的众包技术使得知识的规模化验证成为可能。知识获取的众多环节均可以受益于众包技术。比如,训练知识抽取模型时可以通过众包获取标注样本,从而构建有效的有监督抽取模型。
在知识图谱技术的引领下,各种各样的知识表示将在不损失质量的前提下逐步提升规模,从小规模的知识表示变成大规模的知识表示,最终应对大规模开放性给知识工程带来的巨大挑战。
2)物联网时代的知识图谱
随着5G和垂直行业的成熟商用,网络需要接入更多设备、处理海量数据、满足低时延业务需求。通信技术的升级换代一直是推动社会创新发展的重要力量,5G技术的到来,通信产业开启了全新的时代,也代表着人们真正迈进物联网时代,“万物互联”已是大势所趋,一大批的智能设备正在倍速的加入到互联网中,在云管端均发生了深刻变化,从移动互联到万物智联,从消费互联网到产业互联网,从单一领域创新到跨产业融合创新。然而,物联网要实现智能化,仍面临众多挑战:网络中互联的传感器产生数据量大,数据变化迅速,这对数据库的摄入量、可靠性和实时性要求很高,而且数据之间往往相互关联、查询频繁。
AbutionGraph的出现,就是为了解决传统离线式图形数据库所不能满足的的这些新业务要求。不管是在物联网领域或是金融风控、欺诈检测中,AbutionGraph在结合图处理引擎后还可以提供其所需的关联数据的高效复杂查询与计算能力。

看看flink如何做的?
Introducing Complex Event Processing (CEP) with Apache Flink
06 Apr 2016 by Till Rohrmann (@stsffap)
With the ubiquity of sensor networks and smart devices continuously collecting more and more data, we face the challenge to analyze an ever growing stream of data in near real-time. Being able to react quickly to changing trends or to deliver up to date business intelligence can be a decisive factor for a company’s success or failure. A key problem in real time processing is the detection of event patterns in data streams.
Complex event processing (CEP) addresses exactly this problem of matching continuously incoming events against a pattern. The result of a matching are usually complex events which are derived from the input events. In contrast to traditional DBMSs where a query is executed on stored data, CEP executes data on a stored query. All data which is not relevant for the query can be immediately discarded. The advantages of this approach are obvious, given that CEP queries are applied on a potentially infinite stream of data. Furthermore, inputs are processed immediately. Once the system has seen all events for a matching sequence, results are emitted straight away. This aspect effectively leads to CEP’s real time analytics capability.
Consequently, CEP’s processing paradigm drew significant interest and found application in a wide variety of use cases. Most notably, CEP is used nowadays for financial applications such as stock market trend and credit card fraud detection. Moreover, it is used in RFID-based tracking and monitoring, for example, to detect thefts in a warehouse where items are not properly checked out. CEP can also be used to detect network intrusion by specifying patterns of suspicious user behaviour.
Apache Flink with its true streaming nature and its capabilities for low latency as well as high throughput stream processing is a natural fit for CEP workloads. Consequently, the Flink community has introduced the first version of a new CEP library with Flink 1.0. In the remainder of this blog post, we introduce Flink’s CEP library and we illustrate its ease of use through the example of monitoring a data center.
Monitoring and alert generation for data centers

Assume we have a data center with a number of racks. For each rack the power consumption and the temperature are monitored. Whenever such a measurement takes place, a new power or temperature event is generated, respectively. Based on this monitoring event stream, we want to detect racks that are about to overheat, and dynamically adapt their workload and cooling.
For this scenario we use a two staged approach. First, we monitor the temperature events. Whenever we see two consecutive events whose temperature exceeds a threshold value, we generate a temperature warning with the current average temperature. A temperature warning does not necessarily indicate that a rack is about to overheat. But whenever we see two consecutive warnings with increasing temperatures, then we want to issue an alert for this rack. This alert can then lead to countermeasures to cool the rack.
Implementation with Apache Flink
First, we define the messages of the incoming monitoring event stream. Every monitoring message contains its originating rack ID. The temperature event additionally contains the current temperature and the power consumption event contains the current voltage. We model the events as POJOs:
public abstract class MonitoringEvent {
private int rackID;
...
}
public class TemperatureEvent extends MonitoringEvent {
private double temperature;
...
}
public class PowerEvent extends MonitoringEvent {
private double voltage;
...
}Now we can ingest the monitoring event stream using one of Flink’s connectors (e.g. Kafka, RabbitMQ, etc.). This will give us a DataStream<MonitoringEvent> inputEventStream which we will use as the input for Flink’s CEP operator. But first, we have to define the event pattern to detect temperature warnings. The CEP library offers an intuitive Pattern API to easily define these complex patterns.
Every pattern consists of a sequence of events which can have optional filter conditions assigned. A pattern always starts with a first event to which we will assign the name “First Event”.
Pattern.<MonitoringEvent>begin("First Event");This pattern will match every monitoring event. Since we are only interested in TemperatureEvents whose temperature is above a threshold value, we have to add an additional subtype constraint and a where clause:
Pattern.<MonitoringEvent>begin("First Event")
.subtype(TemperatureEvent.class)
.where(evt -> evt.getTemperature() >= TEMPERATURE_THRESHOLD);As stated before, we want to generate a TemperatureWarning if and only if we see two consecutive TemperatureEvents for the same rack whose temperatures are too high. The Pattern API offers the next call which allows us to add a new event to our pattern. This event has to follow directly the first matching event in order for the whole pattern to match.
Pattern<MonitoringEvent, ?> warningPattern = Pattern.<MonitoringEvent>begin("First Event")
.subtype(TemperatureEvent.class)
.where(evt -> evt.getTemperature() >= TEMPERATURE_THRESHOLD)
.next("Second Event")
.subtype(TemperatureEvent.class)
.where(evt -> evt.getTemperature() >= TEMPERATURE_THRESHOLD)
.within(Time.seconds(10));The final pattern definition also contains the within API call which defines that two consecutive TemperatureEvents have to occur within a time interval of 10 seconds for the pattern to match. Depending on the time characteristic setting, this can either be processing, ingestion or event time.
Having defined the event pattern, we can now apply it on the inputEventStream.
PatternStream<MonitoringEvent> tempPatternStream = CEP.pattern(
inputEventStream.keyBy("rackID"),
warningPattern);Since we want to generate our warnings for each rack individually, we keyBy the input event stream by the “rackID” POJO field. This enforces that matching events of our pattern will all have the same rack ID.
The PatternStream<MonitoringEvent> gives us access to successfully matched event sequences. They can be accessed using the select API call. The select API call takes a PatternSelectFunction which is called for every matching event sequence. The event sequence is provided as a Map<String, MonitoringEvent> where each MonitoringEvent is identified by its assigned event name. Our pattern select function generates for each matching pattern a TemperatureWarning event.
public class TemperatureWarning {
private int rackID;
private double averageTemperature;
...
}
DataStream<TemperatureWarning> warnings = tempPatternStream.select(
(Map<String, MonitoringEvent> pattern) -> {
TemperatureEvent first = (TemperatureEvent) pattern.get("First Event");
TemperatureEvent second = (TemperatureEvent) pattern.get("Second Event");
return new TemperatureWarning(
first.getRackID(),
(first.getTemperature() + second.getTemperature()) / 2);
}
);Now we have generated a new complex event stream DataStream<TemperatureWarning> warnings from the initial monitoring event stream. This complex event stream can again be used as the input for another round of complex event processing. We use the TemperatureWarnings to generate TemperatureAlerts whenever we see two consecutive TemperatureWarnings for the same rack with increasing temperatures. The TemperatureAlerts have the following definition:
public class TemperatureAlert {
private int rackID;
...
}At first, we have to define our alert event pattern:
Pattern<TemperatureWarning, ?> alertPattern = Pattern.<TemperatureWarning>begin("First Event")
.next("Second Event")
.within(Time.seconds(20));This definition says that we want to see two TemperatureWarnings within 20 seconds. The first event has the name “First Event” and the second consecutive event has the name “Second Event”. The individual events don’t have a where clause assigned, because we need access to both events in order to decide whether the temperature is increasing. Therefore, we apply the filter condition in the select clause. But first, we obtain again a PatternStream.
PatternStream<TemperatureWarning> alertPatternStream = CEP.pattern(
warnings.keyBy("rackID"),
alertPattern);Again, we keyBy the warnings input stream by the "rackID" so that we generate our alerts for each rack individually. Next we apply the flatSelect method which will give us access to matching event sequences and allows us to output an arbitrary number of complex events. Thus, we will only generate a TemperatureAlert if and only if the temperature is increasing.
DataStream<TemperatureAlert> alerts = alertPatternStream.flatSelect(
(Map<String, TemperatureWarning> pattern, Collector<TemperatureAlert> out) -> {
TemperatureWarning first = pattern.get("First Event");
TemperatureWarning second = pattern.get("Second Event");
if (first.getAverageTemperature() < second.getAverageTemperature()) {
out.collect(new TemperatureAlert(first.getRackID()));
}
});The DataStream<TemperatureAlert> alerts is the data stream of temperature alerts for each rack. Based on these alerts we can now adapt the workload or cooling for overheating racks.
The full source code for the presented example as well as an example data source which generates randomly monitoring events can be found in this repository.
Conclusion
In this blog post we have seen how easy it is to reason about event streams using Flink’s CEP library. Using the example of monitoring and alert generation for a data center, we have implemented a short program which notifies us when a rack is about to overheat and potentially to fail.
In the future, the Flink community will further extend the CEP library’s functionality and expressiveness. Next on the road map is support for a regular expression-like pattern specification, including Kleene star, lower and upper bounds, and negation. Furthermore, it is planned to allow the where-clause to access fields of previously matched events. This feature will allow to prune unpromising event sequences early.
Note: The example code requires Flink 1.0.1 or higher.