DNS 域名系统(Domain Name System缩写DNS,Domain Name被译为域名)是因特网的一项核心服务,它作为可以将域名和IP地址相互映射的一个分布式数据库
概念
DNS 的全称是 Domain Name System 或者 Domain Name Service,它主要的作用就是将人们所熟悉的网址 (域名) “翻译”成电脑可以理解的 IP 地址,这个过程叫做 DNS 域名解析。
打个比方,我们登百度的地址的时候,都是敲www.baidu.com,进行登陆,难道你会去敲IP地址登百度?明显,域名容易记忆。
而且,一个域名往往对应多个DNS地址,如下图所示

流程
接下来,就不得不说一道经典面试题了
浏览器输入URL到返回页面的全过程
其实回答很简单(俗称天龙八步)
-
1.根据域名,进行DNS域名解析;
-
2.拿到解析的IP地址,建立TCP连接;
-
3.向IP地址,发送HTTP请求;
-
4.服务器处理请求;
-
5.返回响应结果;
-
6.关闭TCP连接;
-
7.浏览器解析HTML;
-
8.浏览器布局渲染;
根据这个可以衍生出一个面试题 :收到的 HTML 如果包含几十个图片标签,这些图片是以什么方式、什么顺序、建立了多少连接、使用什么协议被下载下来的呢?(面试官疯了的会这么问)
要搞懂这个问题,我们需要先解决下面五个问题:
-
现代浏览器在与服务器建立了一个 TCP 连接后是否会在一个 HTTP 请求完成后断开?什么情况下会断开?
-
一个 TCP 连接可以对应几个 HTTP 请求?
-
一个 TCP 连接中 HTTP 请求发送可以一起发送么(比如一起发三个请求,再三个响应一起接收)?
-
为什么有的时候刷新页面不需要重新建立 SSL 连接?
-
浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
第一个问题
现代浏览器在与服务器建立了一个 TCP 连接后是否会在一个 HTTP 请求完成后断开?什么情况下会断开?
在 HTTP/1.0 中,一个服务器在发送完一个 HTTP 响应后,会断开 TCP 链接。但是这样每次请求都会重新建立和断开 TCP 连接,代价过大。所以虽然标准中没有设定,某些服务器对 Connection: keep-alive 的 Header 进行了支持。意思是说,完成这个 HTTP 请求之后,不要断开 HTTP 请求使用的 TCP 连接。这样的好处是连接可以被重新使用,之后发送 HTTP 请求的时候不需要重新建立 TCP 连接,以及如果维持连接,那么 SSL 的开销也可以避免,两张图片是我短时间内两次访问 https://www.github.com 的时间统计:

头一次访问,有初始化连接和 SSL 开销
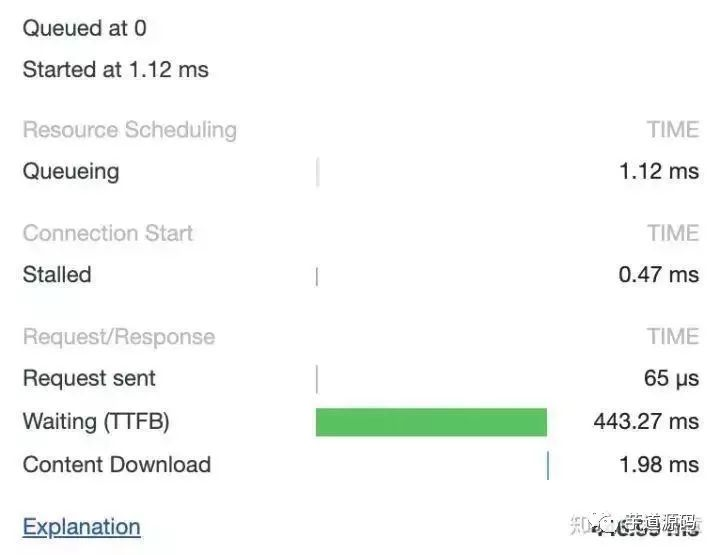
初始化连接和 SSL 开销消失了,说明使用的是同一个 TCP 连接
持久连接:既然维持 TCP 连接好处这么多,HTTP/1.1 就把 Connection 头写进标准,并且默认开启持久连接,除非请求中写明 Connection: close,那么浏览器和服务器之间是会维持一段时间的 TCP 连接,不会一个请求结束就断掉。
所以第一个问题的答案是:默认情况下建立 TCP 连接不会断开,只有在请求报头中声明 Connection: close 才会在请求完成后关闭连接。
第二个问题
一个 TCP 连接可以对应几个 HTTP 请求?
了解了第一个问题之后,其实这个问题已经有了答案,如果维持连接,一个 TCP 连接是可以发送多个 HTTP 请求的。
第三个问题
一个 TCP 连接中 HTTP 请求发送可以一起发送么(比如一起发三个请求,再三个响应一起接收)?
HTTP/1.1 存在一个问题,单个 TCP 连接在同一时刻只能处理一个请求,意思是说:两个请求的生命周期不能重叠,任意两个 HTTP 请求从开始到结束的时间在同一个 TCP 连接里不能重叠。
虽然 HTTP/1.1 规范中规定了 Pipelining 来试图解决这个问题,但是这个功能在浏览器中默认是关闭的。
先来看一下 Pipelining 是什么,RFC 2616 中规定了:
至于标准为什么这么设定,我们可以大概推测一个原因:由于 HTTP/1.1 是个文本协议,同时返回的内容也并不能区分对应于哪个发送的请求,所以顺序必须维持一致。比如你向服务器发送了两个请求 GET/query?q=A 和 GET/query?q=B,服务器返回了两个结果,浏览器是没有办法根据响应结果来判断响应对应于哪一个请求的。
Pipelining 这种设想看起来比较美好,但是在实践中会出现许多问题:
-
一些代理服务器不能正确的处理 HTTP Pipelining。
-
正确的流水线实现是复杂的。
-
Head-of-line Blocking 连接头阻塞:在建立起一个 TCP 连接之后,假设客户端在这个连接连续向服务器发送了几个请求。按照标准,服务器应该按照收到请求的顺序返回结果,假设服务器在处理首个请求时花费了大量时间,那么后面所有的请求都需要等着首个请求结束才能响应。
所以现代浏览器默认是不开启 HTTP Pipelining 的。
但是,HTTP2 提供了 Multiplexing 多路传输特性,可以在一个 TCP 连接中同时完成多个 HTTP 请求。至于 Multiplexing 具体怎么实现的就是另一个问题了。我们可以看一下使用 HTTP2 的效果。

绿色是发起请求到请求返回的等待时间,蓝色是响应的下载时间,可以看到都是在同一个 Connection,并行完成的
所以这个问题也有了答案:在 HTTP/1.1 存在 Pipelining 技术可以完成这个多个请求同时发送,但是由于浏览器默认关闭,所以可以认为这是不可行的。在 HTTP2 中由于 Multiplexing 特点的存在,多个 HTTP 请求可以在同一个 TCP 连接中并行进行。
那么在 HTTP/1.1 时代,浏览器是如何提高页面加载效率的呢?主要有下面两点:
-
维持和服务器已经建立的 TCP 连接,在同一连接上顺序处理多个请求。
-
和服务器建立多个 TCP 连接。
第四个问题
为什么有的时候刷新页面不需要重新建立 SSL 连接?
在第一个问题的讨论中已经有答案了,TCP 连接有的时候会被浏览器和服务端维持一段时间。TCP 不需要重新建立,SSL 自然也会用之前的。
第五个问题
浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
假设我们还处在 HTTP/1.1 时代,那个时候没有多路传输,当浏览器拿到一个有几十张图片的网页该怎么办呢?肯定不能只开一个 TCP 连接顺序下载,那样用户肯定等的很难受,但是如果每个图片都开一个 TCP 连接发 HTTP 请求,那电脑或者服务器都可能受不了,要是有 1000 张图片的话总不能开 1000 个TCP 连接吧,你的电脑同意 NAT 也不一定会同意。
所以答案是:有。Chrome 最多允许对同一个 Host 建立六个 TCP 连接。不同的浏览器有一些区别。
https://developers.google.com/web/tools/chrome-devtools/network/issues#queued-or-stalled-requestsdevelopers.google.com
那么回到最开始的问题,收到的 HTML 如果包含几十个图片标签,这些图片是以什么方式、什么顺序、建立了多少连接、使用什么协议被下载下来的呢?
如果图片都是 HTTPS 连接并且在同一个域名下,那么浏览器在 SSL 握手之后会和服务器商量能不能用 HTTP2,如果能的话就使用 Multiplexing 功能在这个连接上进行多路传输。不过也未必会所有挂在这个域名的资源都会使用一个 TCP 连接去获取,但是可以确定的是 Multiplexing 很可能会被用到。
如果发现用不了 HTTP2 呢?或者用不了 HTTPS(现实中的 HTTP2 都是在 HTTPS 上实现的,所以也就是只能使用 HTTP/1.1)。那浏览器就会在一个 HOST 上建立多个 TCP 连接,连接数量的最大限制取决于浏览器设置,这些连接会在空闲的时候被浏览器用来发送新的请求,如果所有的连接都正在发送请求呢?那其他的请求就只能等等了。
下面我们着重来说DNS解析这块
解析
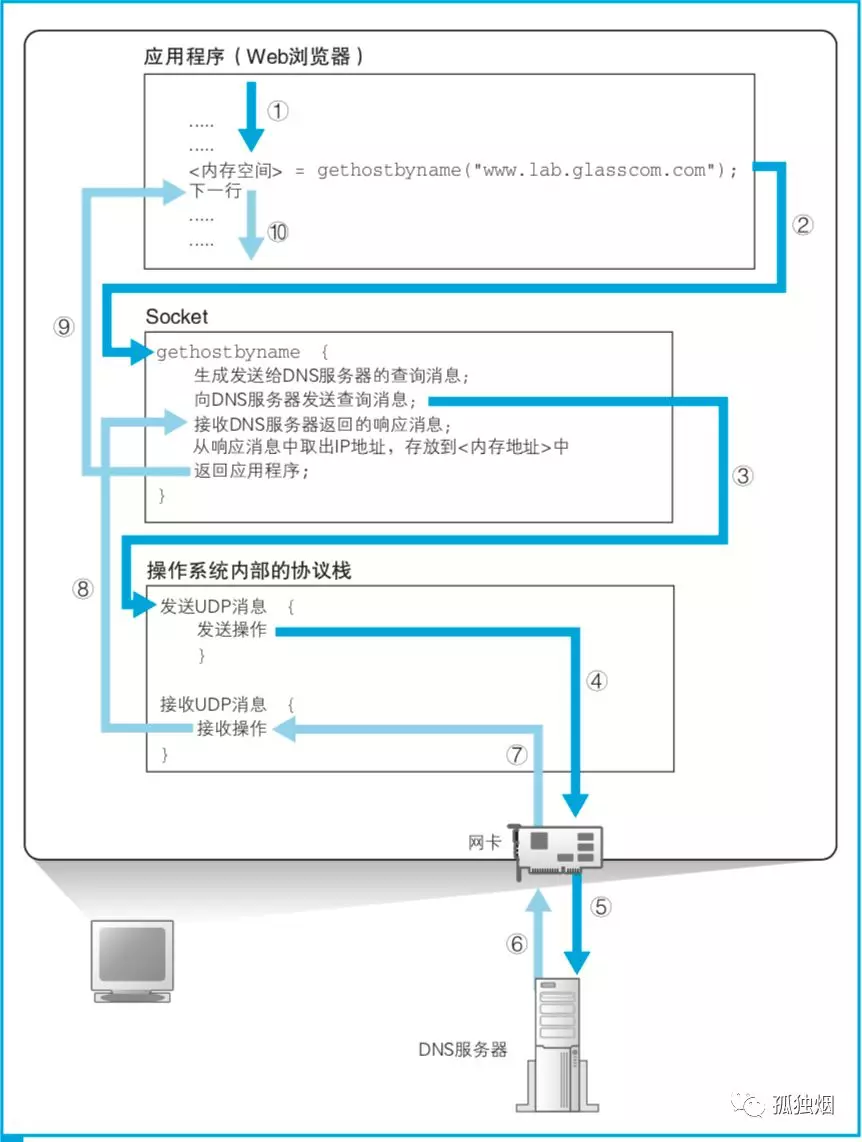
如图所示,大致就是:浏览器输入地址,然后浏览器这个进程去调操作系统某个库里的gethostbyname函数(例如,Linux GNU glibc标准库的gethostbyname函数),然后呢这个函数通过网卡给DNS服务器发UDP请求,接收结果,然后将结果给返回给浏览器。
这张图其实已经讲明白大致的流程,但是细节上可能有些差异。
例如
-
(1)我们在用chrome浏览器的时候,其实会先去浏览器的dns缓存里头查询,dns缓存中没有,再去调用gethostbyname函数
-
(2)gethostbyname函数在试图进行DNS解析之前首先检查域名是否在本地 Hosts 里,如果没找到再去DNS服务器上查
不过,看到这里!请回忆下这两道面试题?
1 说说upd协议在哪里使用?tcp协议在哪里使用?
2 DNS在域名解析上用到了TCP协议还是udp协议?
不过呢,需要补充说明一下,DNS中也有一个地方用到了TCP协议。那就是区域传送!
DNS的规范规定了2种类型的DNS服务器,一个叫主DNS服务器,一个叫辅助DNS服务器。在一个区中主DNS服务器从自己本机的数据文件中读取该区的DNS数据信息,而辅助DNS服务器则从区的主DNS服务器中读取该区的DNS数据信息。当一个辅助DNS服务器启动时,它需要与主DNS服务器通信,并加载数据信息,这就叫做区传送(zone transfer)。这种情况下,使用TCP协议。
讲到这里。其实面试官是可以深入追问的,如下所示
1 域名解析为什么用到了UDP
2 区域赋值为什么用TCP?
针对第一问,为什么域名解析用UDP协议?
因为UDP快啊!UDP的DNS协议只要一个请求、一个应答就好了。而使用基于TCP的DNS协议要三次握手、发送数据以及应答、四次挥手。但是UDP协议传输内容不能超过512字节。不过客户端向DNS服务器查询域名,一般返回的内容都不超过512字节,用UDP传输即可。
针对第二问,为什么区域传送用TCP协议?
因为TCP协议可靠性好啊!你要从主DNS上复制内容啊,你用不可靠的UDP?
因为TCP协议传输的内容大啊,你用最大只能传512字节的UDP协议?万一同步的数据大于512字节,你怎么办?
原理
现在,讲最后一块DNS解析域名的原理!这块是重中之重!
先介绍linux下一个dig命令,以显示解析域名的过程。
为了便于说明,我们来dig一下天猫的过程
dig www.tmall.com
结果如下图所示
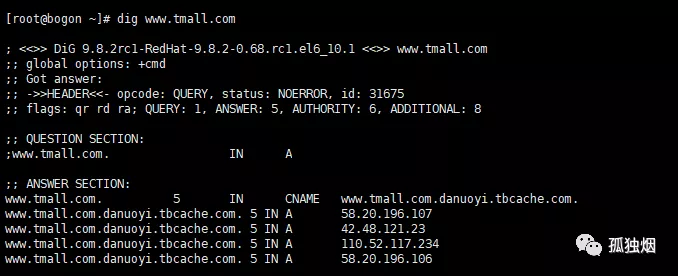
现在我们来读重点的两段。第一段代表请求参数如下图所示

这段为查询内容。
DNS的查询参数一般有三个
-
(1)域名:服务器、邮件服务器(邮件地址中 @ 后面的部分)的名称
-
(2)Class:在设置DNS方案时,互联网之外的网络也考虑到了,而Class就是用来识别网络的,不过现在只有互联网,所以它的值永远都是代表互联网的IN
-
(3)记录类型:标识域名对应何种类型的记录。类型为A,表示域名对应的IP地址。类型为MX时,表示域名对应的是邮件服务器。类型为PTR,表示根据IP地址反查域名。类型为CNAME,表示查询域名相关别名。
当然,你这个时候要问我一个问题啦(注意上图红框)
我输入的明明是www.tmall.com可是命令里解析的地址是www.tmall.com.啊,多了一个.的符号啊?这个.符号是什么意思呢?
于是乎,又扯了一道经典面试题
说说DNS是如何做域名解析的?
OK,好,要讲明白这个问题。我们要先把域名的结构讲清楚!
www.tmall.com对应的真正的域名为www.tmall.com.。末尾的.称为根域名,因为每个域名都有根域名,因此我们通常省略。
根域名的下一级,叫做"顶级域名"(top-level domain,缩写为TLD),比如.com、.net;
再下一级叫做"次级域名"(second-level domain,缩写为SLD),比如www.tmall.com里面的.tmall,这一级域名是用户可以注册的;
再下一级是主机名(host),比如www.tmall.com里面的www,又称为"三级域名",这是用户在自己的域里面为服务器分配的名称,是用户可以任意分配的。
那么解析流程就是分级查询!
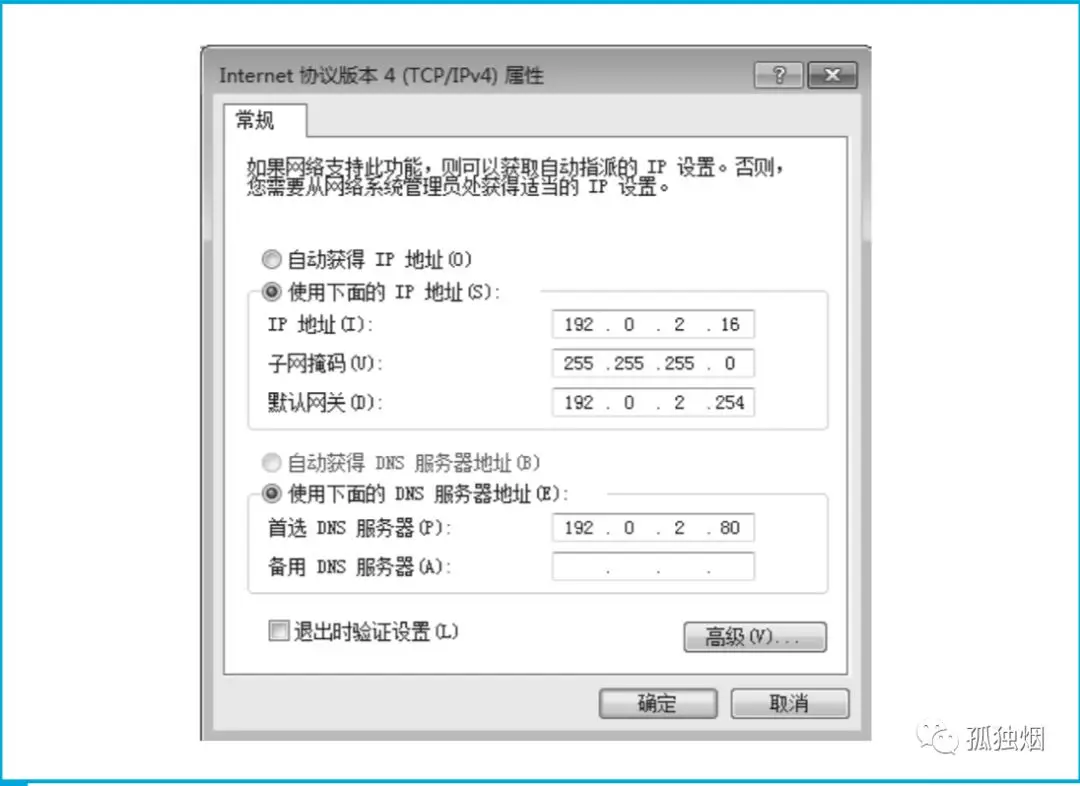
(1)先在本机的DNS里头查,如果存在就直接返回了。本机DNS就是下面这个东东
(2)本机DNS里头发现没有,就去根服务器里查。根服务器发现这个域名是属于com域,因此根域DNS服务器会返回它所管理的com域中的DNS 服务器的IP地址,意思是“虽然我不知道你要查的那个域名的地址,但你可以去com域问问看”
(3)本机的DNS接到又会向com域的DNS服务器发送查询消息。com 域中也没有www.tmall.com这个域名的信息,和刚才一样,com域服务器会返回它下面的tmall.com域的DNS服务器的IP地址。
以此类推,只要重复前面的步骤,就可以顺藤摸瓜找到目标DNS服务器
ps:温馨提醒,dig +trace www.tmall.com 可以看到解析过程。有兴趣的读者,自己实验一下。
扯了那么多东西,我们来看第二段内容,也就是响应体的部分!
如下所示

很明显,第一行就是说www.tmall.com这个域名地址拥有一个别名是www.tmall.com.danuoyi.tbcache.com。那么,很显然,后面几行就是这个www.tmall.com.danuoyi.tbcache.com地址的真实IP。