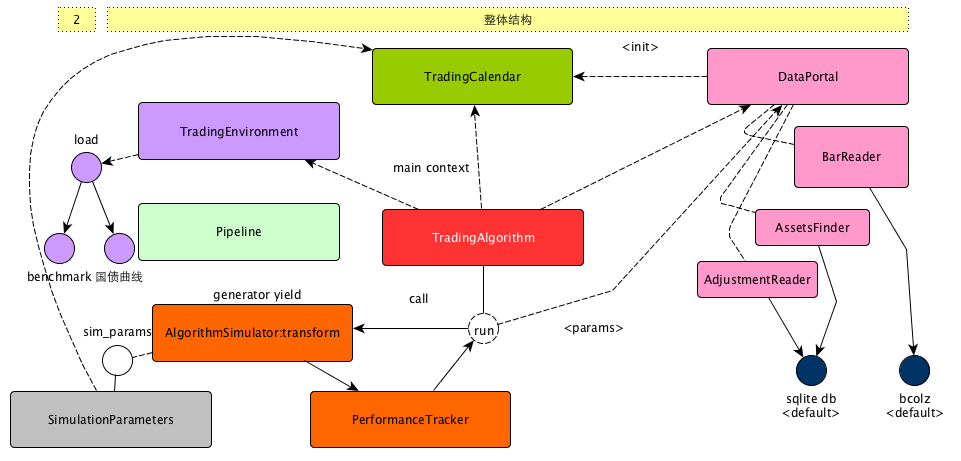
在这里可以看出,zipline由下面几个主要的部分构成
| 名称 | 说明 |
|---|---|
| TradingAlgorithm | 量化策略的抽象,既可以通过初始化传入构造上参数的方式,也可以通过继承的方式构造,其中zipline命令行主要的运行入口逻辑 run 方法也在这个类中 |
| TradingCalendar | 交易日历的抽象,这个类非常重要,无论是在构建数据的过程还是运行的过程,都可以用到 |
| DataPortal | 数据中心的抽象,可以通过这个入口获取很多不同类型的数据 |
| AlgorithmSimulator | 使用generator的方式,表述了策略运行过程的主循环。如果说TradingAlgorithm更像是代表了策略本身,那么AlgorithmSimulator更像是策略的执行器,尤其要关注的是他的transform方法 |
| TradingEnvirioment | 构造运行环境,主要是benchmark和国债利率曲线等信息,对于美国的市场,这个类基本上不太需要关注,但是对于国内的市场,我么需要构建自己的TradingEnvironment |
-
Every zipline algorithm consists of two functions you have to define:
- initialize(context)
- handle_data(context, data)
-
contextis a persistent namespace for you to store variables you need to access from one algorithm iteration to the next. -
Zipline的本地化回测应用主要涉及2大块内容:TradingEnvironment和TradingAlgorithm。
TradingEnvironment主要用于本地化交易环境设置,而TradingAlgorithm则是Zipline回测框架的主对象,可以理解为回测入口。 -
TradingEnvironment本地化最重要的就是设置:
- tradingcalendar
- benchmarke_return
- treasury_return
tradingcalendar用于设置tradingdays,其默认已排除周六周日,因此只需要重写一个py文件将每年对应的holiday(国内假期)从tradingdays除去即可。
而benchmarke_return和treasury_return则作为策略回报的比较基准,将国内沪深300和对应各期限国债收益率通过重载load函数导入,将load函数对象传入至TradingEnvironment即可。
注意benchmarke_return为Pandas的Series对象,treasury_return为DataFrame对象,各期限必须包含1month ~ 10year间所有。
-
TradingAlgorithm的本地化则需要重点设置:simulation_parameters、initialize函数对象,handle_data函数对象。
simulation_parameters包括策略回测的起始日期和回测频率,回测起始日期必须通过Pandas的tz_localize本地化,而回测频率包含daily和minute两种方式。
而initialize函数与handle_data函数则用于策略初始化和模拟Bar周期反复回调所用。 -
数据的准备:理论上Zipline只支持其内置的DataPortal类型,它是其回测模拟所有数据的接口。
考虑到通用性,Zipline目前也支持pandas的DataFrame和Panel,只不过它对DataFrame的支持就是将其很粗暴的转换为Panel来实现的。因此,就目前来说,Zipline只支持内置DataPortal和Pandas的Panel两种类型。所以,用户可以将任何本地可获取的数据首先转换为DataFrame,其index按日递增,columns为小写的open、high、low、close和volume等。然后以DataFrame为value,数据ticker为key来构建相对应的Panel作为回测本地化的标准数据输入。