MapReduce
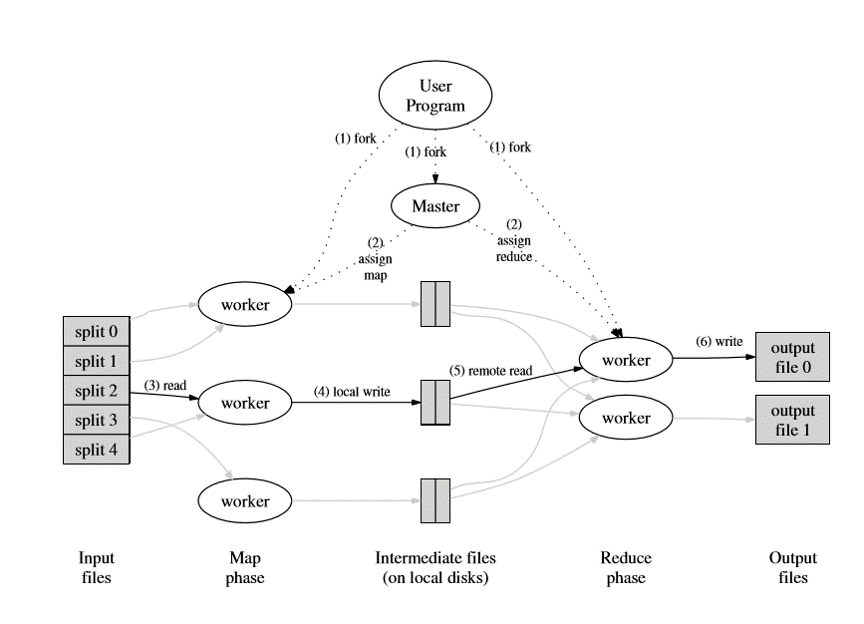
MapReduce的出现,用户只需要编写map和reduce的处理流程,就能完成完成一个分布式计算,简化了分布式任务编写的难度。MapReduce封装了数据切分,任务调度,错误处理,负载均衡。
Spark
和hadoop MapReduce对比,spark主要做了两个方面的优化:
- 减少了MapReduce任务不必要的map。
- 在shuffle阶段,MapReduce都要将临时数据写盘,spark会尽可能地将临时数据保留在内存中。


Spark架构
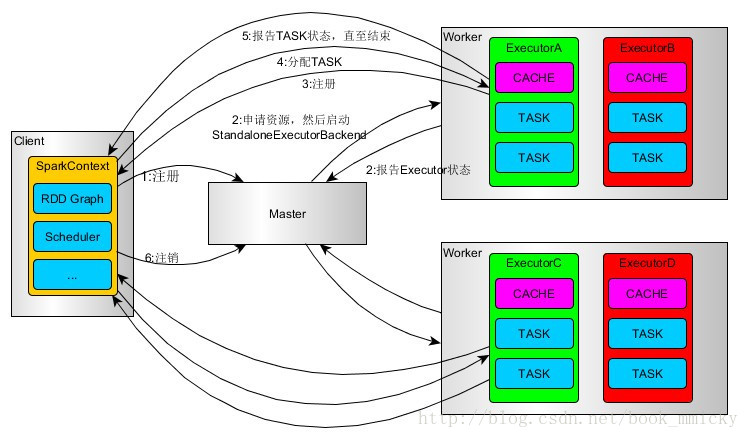
- SparkContext连接到Master,向Master注册并申请资源(CPU Core 和Memory)
- Master根据SparkContext的资源申请要求和worker心跳周期内报告的信息决定在哪些worker(每台slave上一个或多个)上分配资源,然后在该worker上获取资源,然后启动ExecutorBackend(一个application只能有一个)。
- ExecutorBackend向SparkContext注册
- SparkContext将task发送给ExecutorBackend,ExecutorBackend启动executor(每组task一个executor)执行task,并向SparkContext报告,直至Task完成。
- 所有Task完成后,SparkContext向Master注销,释放资源。
基本概念
集群概念
- Application:用户在 spark 上构建的程序,包含了 driver 程序以及在集群上运行的程序代码,物理机器上涉及了 driver,master,worker 三个节点.
- Driver Program:用户编写的spark程序,应用程序所需要的三大步骤的逻辑:加载数据集,处理数据,结果展示
- Cluster Manager:集群的资源管理器,在集群上获取资源的外部服务。
- Worker Node:集群中任何一个可以运行spark应用代码的节点。Worker Node就是物理节点,可以在上面启动Executor进程。
- Executor:Worker Node上执行任务的容器。
有向无环图
- DAG Direct Acyclic Graph
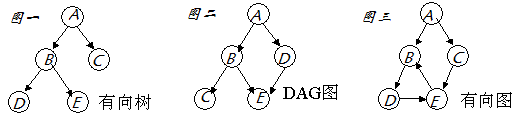
任何一个分布式任务,都可以用DAG图抽象
RDD
RDD基本概念
- 一组分片(partition),即数据集的基本组成单位
- 一个计算每个分片的函数
- 对parent RDD的依赖,这个依赖描述了RDD之间的lineage
- Partitioner方式,例如hash_based,sort_based(可选)
- 存储每个分片的preferred位置(可选)
RDD中的宽依赖和窄依赖
- 窄依赖:Each partition of the parent RDD is used by at most one partition of the child RDD
- 宽依赖:Multiple child partitions depend on parent RDD
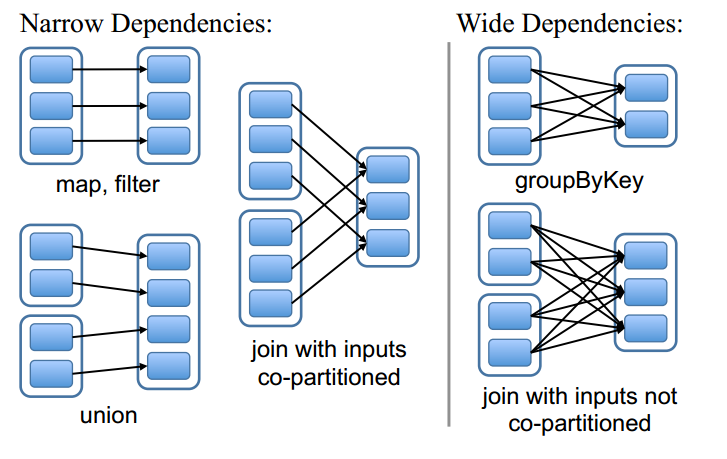
- 计算方面:
- 窄依赖:可以在某一个计算节点上直接通过父RDD的某几块数据(通常是一块)计算得到子RDD某一块的数据
- 宽依赖:子RDD某一块数据的计算必须等到它的父RDD所有数据都计算完成之后才可以进行,而且需要对父RDD的计算结果进行hash并传递到对应的节点之上;
- 容错恢复方面:
- 窄依赖:当RDD的某分片丢失时,只有丢失的那一块数据需要被重新计算
- 宽依赖:当RDD的某分片丢失时,需要利用父RDD的所有分区数据重新计算一次,计算量明显比窄依赖情况下大很多
RDD操作
- RDD上定义了四种类型的操作
- transform:foreach, glom, map
- action:count, take, sample, first, collect
- method : cache, checkpoint, id, isCheckpointed, isEmpty, keys, lookup, max, mean, name, setName
- property : context
其中,最常用的是transform和action。
job,stage和task
wordcount例子
一般来说,构建一个spark应用主要有3步
- 加载数据集
- 处理数据
- 结果展示
import scala.Tuple2;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
public final class JavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
if (args.length < 1) {
System.err.println("Usage: JavaWordCount <file>");
System.exit(1);
}
SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
JavaRDD<String> lines = ctx.textFile(args[0], 1);
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) {
return Arrays.asList(SPACE.split(s));
}
});
JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?,?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
ctx.stop();
}
}
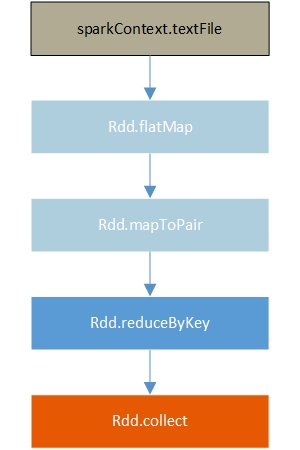
概念
- job:所谓一个 job,就是由一个 rdd 的 action 触发的动作,可以简单的理解为,当你需要执行一个 rdd 的 action 的时候,会生成一个 job。
- stage:stage 是一个 job 的组成单位,就是说,一个 job 会被切分成 1 个或 1 个以上的 stage,然后各个stage会按照执行顺序依次执行。(依据RDD是否需要shuffle划分stage)
一般来说,如果出现宽依赖,需要划分一个stage。 - task:与RDD partion对应。
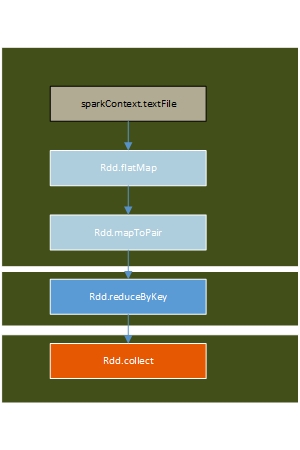
流程
一个spark任务的执行流程
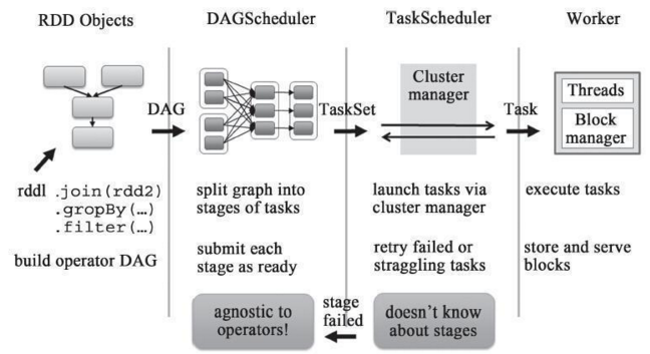
spark中,DAG的调度顺序是以stage by 提交stage的过程是一个递归的过程,它是先要把父stage先提交,然后把自己添加到等待队列中,直到没有父stage之后,就提交该stage中的任务。等待队列在最后的submitWaitingStages方法中提交。
- Driver程序的代码运行到action操作,触发了SparkContext的runJob方法。
- SparkContext调用DAGScheduler的runJob函数。
- DAGScheduler把Job划分stage,然后把stage转化为相应的Tasks,把Tasks交给TaskScheduler。
- 通过TaskScheduler把Tasks添加到任务队列当中,交给SchedulerBackend(不同配置模式调度器不一样,资源调度)进行资源分配,然后TaskSetManager根据本地性进行任务调度。
- 调度器给Task分配执行Executor,ExecutorBackend负责执行Task。
Spark容错机制
一般来说:分布式数据集的容错性有两种方式:数据检查点和记录数据的更新
- 数据检查点:当任务执行到某个状态,将该状态的数据全部复制保存。
- 记录数据的更新:记录数据的操作日志
面向大规模数据分析,数据检查点操作成本很高,需要通过数据中心的网络连接在机器之间复制庞大的数据集,而网络带宽往往比内存带宽低得多,同时还需要消耗更多的存储资源。
采用记录数据更新的方式,开销要小很多。但是记录数据的粒度太细,记录更新的成本也很高。
spark中,容错主要采用基于数据记录的方式进行。称为采用血统(Lineage)容错。
Lineage本质上很类似于数据库中的重做日志(Redo Log),只不过这个重做日志粒度很大,是对全局数据做同样的重做进而恢复数据。
上面我们提到了RDD的两种依赖关系,容错也是基于这两种依赖关系来做的。
- 容错原理
- 窄依赖:当RDD的某分片丢失时,只有丢失的那一块数据需要被重新计算
- 宽依赖:当RDD的某分片丢失时,需要利用父RDD的所有分区数据重新计算一次,计算量明显比窄依赖情况下大很多
- Checkpoint机制
因此,spark中还采取了Checkpoint算子来做检查点,不仅要考虑Lineage是否足够长,也要考虑是否有宽依赖,对宽依赖加Checkpoint是最物有所值的。以下两种情况下,RDD需要加检查点。检查点(本质是通过将RDD写入HDFS做检查点)是给通过lineage做容错的辅助
- DAG中的Lineage过长,如果重算,则开销太大(如在PageRank中)。
- 在宽依赖上做Checkpoint获得的收益更大。
Spark shuffle过程
用一张图来说明
图中一共有M个Map任务,R个Reduce任务,C台节点。每个Map任务产生R个bucket,每台节点上只有R个File,后续Map任务产生的Bucket放在前面产生的File里面。所以一次shuffle产生的文件数量为C*R个
spark partioner
spark默认提供两种partioner,HashPartioner和RangePartioner。另外用户也可以自定义Partioner
总结
spark内部设计十分复杂,这里只是对原理做了大致的介绍。这里对spark的关键技术做个总结。
- spark 架构
- RDD 基本概念
- DAG任务执行
- 容错