# 直接上代码,抓取关键词搜索结果的json数据
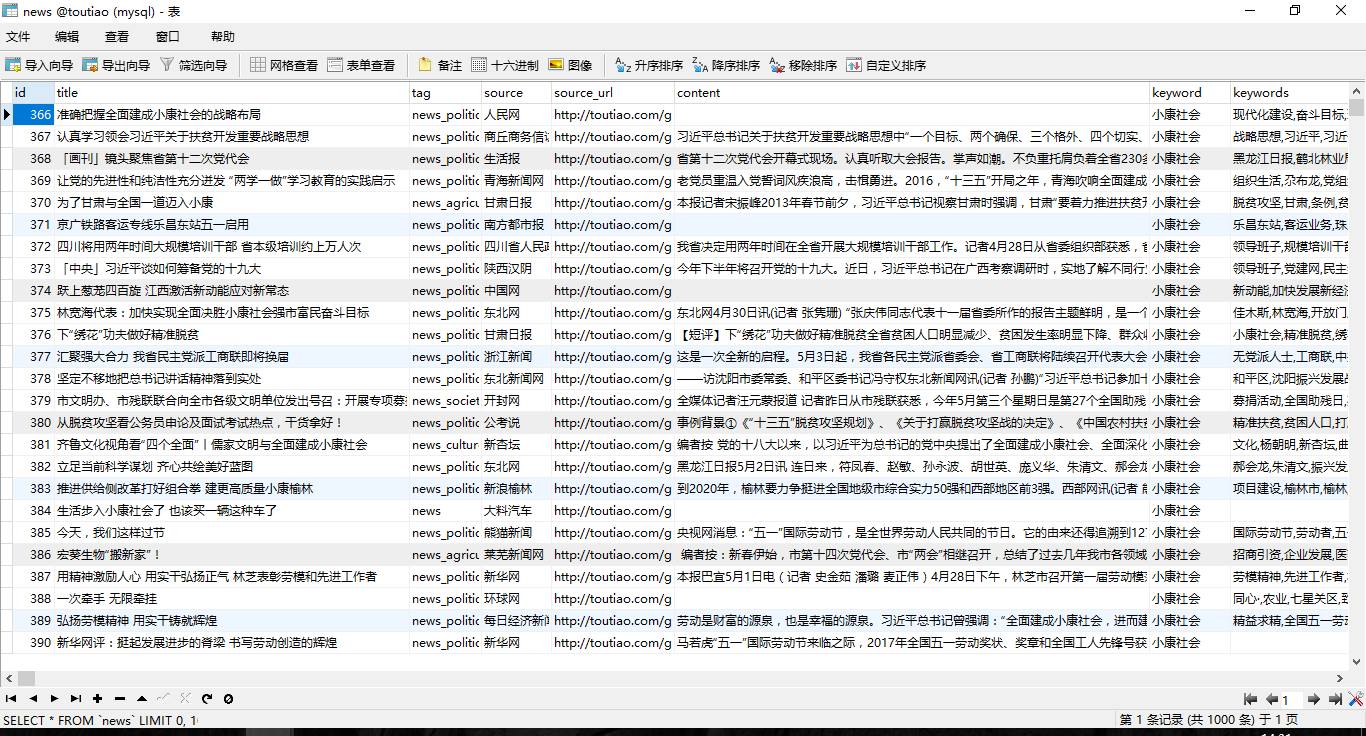
# coding:utf-8 import requests import json url = 'http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E5%B0%8F%E5%BA%B7%E7%A4%BE%E4%BC%9A&autoload=true&count=20&cur_tab=1' wbdata = requests.get(url).text data = json.loads(wbdata) news = data['data'] for n in news: if 'title' in n: title = n['title'] source = n['source'] url = n['article_url'] keyword = n['keywords'] print(title,url,keyword,source)
github: https://github.com/haibincoder/ToutiaoCrawler
1.浏览器中找到内容的接口,Network --> XHR是动态加载的,如果没有内容的话刷新当前页面,我们这里可以看到data节点下面有需要的数据。
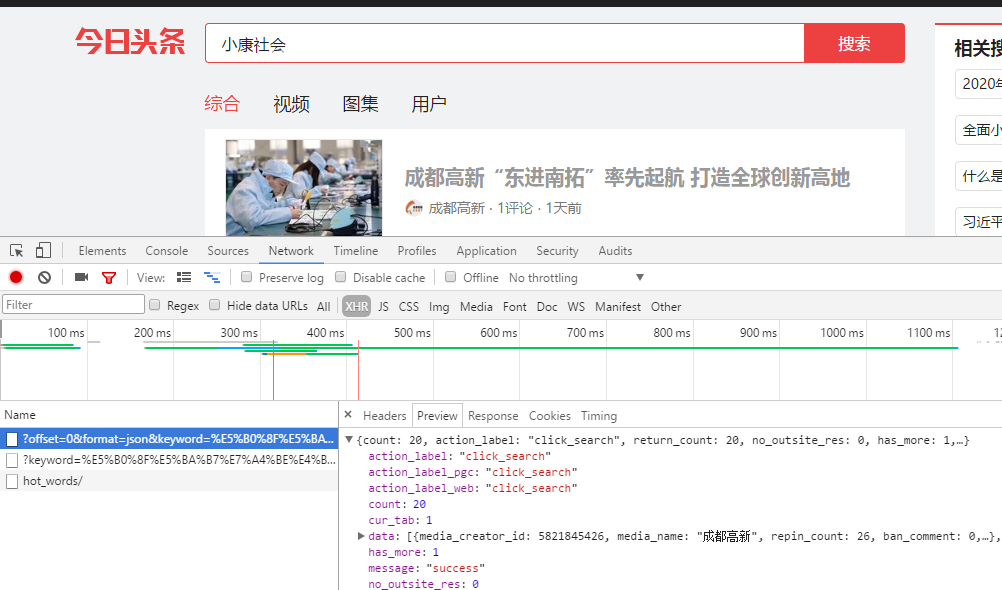
2.找到需要的内容和url

3.返回结果

另外可以爬取关键词搜索结果,keyword就是一个数组,可以自己定义。
def keyword_search(keyword): url = 'http://www.toutiao.com/search_content/?offset=0&format=json&keyword= ' + keyword + '&autoload=true&count=200&cur_tab=1' toutiao_data = requests.get(url).text data = json.loads(toutiao_data) items = data['data'] news_list = [] link_head = 'http://toutiao.com' for n in items: if 'title' in n: news = News() news.title = n['title'] news.tag = n['tag'] news.source = n['source'] news.source_url = link_head + n['source_url'] # 两会关键词 news.keyword = keyword # 今日头条自带关键词 news.keywords = n['keywords'] news_list.append(news) #print(news.title, news.source_url, news.source, news.keyword, news.keywords) return news_list
爬取结果,其中Content另外写了一个爬虫,第二个爬虫就是读取source_url,然后抓取正文