Pandas是python的一个数据分析包,包含以下几种数据结构:
1. Series:类似于一维数组,包含索引和值两个部分
2. DataFrame: 类似于二维数组,用于存放二维表格型数据结构,包含行索引、列索引和值三个部分
Series
1. 创建:
默认索引:S1 = pd.Series(['Sam', 15, 'France', 'male'])
指定索引:S1 = pd.Series(['Sam', 15, 'France', 'male'], index=['name','age','country','gender'])
字典创建:S1 = pd.Series({'name':'Sam', 'age':15, 'country':'France', 'gender':'male'})
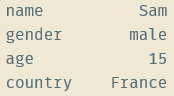
字典+索引:S1 = pd.Series({'name':'Sam', 'age':15, 'country':'France', 'gender':'male'}, index=['name', 'gender', 'age', 'country'])
上一行代码创建的Series如下所示
2. 访问
通过索引名:S1['name']
通过序号:S1[0]
布尔索引:S1[S1.index == 'age'] 或 S1[S1.values == 15]
3. 操作
赋值:通过访问即可赋值
增加元素:S1['height'] = 160
删除元素:S1.drop('gender', inplace = True) 参数inplace表示是否修改原数据
检测缺失值:S1.isnull() 或 S1.notnull()
删除缺失值:S1.dropna()
4. 属性
Series的值:S1.values
Series的索引:S1.index
Series的形状:S1.shape
DataFrame
1. 创建:
字典创建
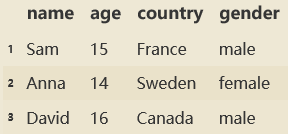
D1 = pd.DataFrame({'name':['Sam','Anna','David'],
'age':[15,14,16],
'country':['France','Sweden','Canada'],
'gender':['male','female','male']},
index=['a','b','c'])
列表创建
D2 = pd.DataFrame([['Sam',15,'France','male'], ['Anna',14,'Sweden','female'], ['David',16,'Canada','male']], index=['a','b','c'], columns=['name','age','country','gender'])
以上两块代码创建的DataFrame均如下所示
创建空列表(指定列名)
pd.DataFrame(columns=('name','age','country','gender'))
2. 访问
通过列索引:D1['name'] 或 D1.name
通过iloc方法:
D1.iloc[[0,0]] 得到第一行第一列
D1.iloc[0] 得到第一行
D1.iloc[:,0] 得到第一列
D1.iloc[[0,1],[0,1]] 得到前两行和前两列的交叉部分
通过loc方法:
loc方法与iloc方法基本相同,区别在于loc方法通过索引名访问数据,iloc通过索引序号访问数据
例如 D1.loc['a','name'] 得到第一行第一列
3. 操作
赋值:通过访问即可赋值
增加列:D1['height'] = [160, 150, 170]
增加行:D1 = D1.append({'name': 'Tommas', 'age': 13, 'country': 'USA', 'gender': 'male'}, ignore_index=True)
删除行或列:D1.drop(['age', 'gender'], inplace = False, axis = 1) 参数axis表示行或列
检测缺失值:D1.isnull() 或 D1.notnull()
删除缺失值:D1.dropna(axis=*)
填充缺失值:D1.fillna(*)
按条件(年龄)筛选行:D1[D1['age'] > 14] 或者 D1[(D1['age'] > 14) & (D1['age'] < 16)]
修改列名: D1.rename(columns = {'name': 'NAME', 'age': 'AGE'}, inplace=True)
合并:pd.concat([D1, D1])
4. 属性
DataFrame的值:D1.values
DataFrame的行索引:D1.index
DataFrame的列索引:D1.columns
DataFrame的形状:D1.shape