上一篇已经统计出了起薪最高的top 10:

接着玩,把top 10 中所有职位的详细信息爬取下来。某一职位的详情是这样:
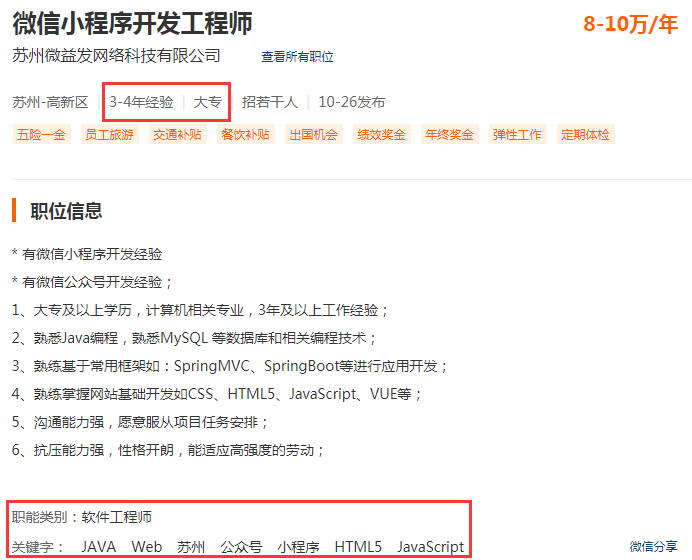
我们需要把工作经验、学历、职能、关键字爬取下来。
1 from urllib.request import urlopen 2 from urllib.error import HTTPError 3 from bs4 import BeautifulSoup 4 import csv 5 from itertools import chain 6 import threading 7 8 def load_datas(): 9 ''' 10 从joblist.csv中装载数据 11 :return: 数据集 datas 12 ''' 13 datas = [] 14 with open('high10_url.csv', encoding='utf-8') as fp: 15 r = csv.reader(fp) 16 for row in r: 17 datas.append(row[0]) 18 return datas 19 20 def get_desc(url): 21 ''' 爬取职位的详细信息,包括:经验, 学历, 职位, 技能关键字 ''' 22 try: 23 html = urlopen(url) 24 except HTTPError as e: 25 print('Page was not found', e.filename) 26 return [] 27 28 job_desc = [] # 职位详情 29 try: 30 exp, edu, position, keys = '', '', '', [] # 经验, 学历, 职位, 技能关键字 31 bsObj = BeautifulSoup(html.read()) 32 contents = bsObj.find('p', {'class': 'msg ltype'}).contents 33 exp = contents[2].strip() # 经验 34 edu = contents[4].strip() # 学历 35 print(edu) 36 a_list = bsObj.findAll('a', {'class': 'el tdn'}) 37 for i, a in enumerate(a_list): 38 if i == 0: 39 position = a.get_text() # 职位 40 else: 41 keys.append(a.get_text()) # 技能关键字 42 job_desc.append((exp, edu, position, keys)) 43 except AttributeError as e: 44 print(e) 45 job_desc = [] 46 return job_desc 47 48 def crawl(urls): 49 ''' 50 :param urls: 职位详情 51 ''' 52 print('开始爬取数据...') 53 job_desc = [get_desc(url) for url in urls] 54 print('爬取结束') 55 return job_desc 56 57 def save_data(all_jobs, f_name): 58 ''' 59 将信息保存到目标文件 60 :param all_jobs: 二维列表,每个元素是一页的职位信息 61 ''' 62 print('正在保存数据...') 63 with open(f_name, 'w', encoding='utf-8', newline='') as fp: 64 w = csv.writer(fp) 65 # 将二维列表转换成一维 66 t = list(chain(*all_jobs)) 67 w.writerows(t) 68 print('保存结束,共{}条数据'.format(len(t))) 69 70 urls = load_datas() 71 job_desc = crawl(urls) 72 print(job_desc) 73 save_data(job_desc, 'job_desc.csv')
high10_url.csv中已经预先存储了top 10的所有64个url。job_desc.csv中的结果如下:

学历列出现了问题,第5行显示的是“招1人”,实际上这个职位没有学历要求,把所有“招x人”的记录都改成“无要求”。
接下来可以按照经验、学历、职能分别统计:
import csv import pandas as pd import numpy as np def load_datas(): ''' 从joblist.csv中装载数据 :return: 数据集 datas ''' datas = [] with open('job_desc.csv', encoding='utf-8') as fp: r = csv.reader(fp) for row in r: datas.append(row) return datas def analysis(datas): ''' 数据分析 ''' df = pd.DataFrame({'exp': datas[:, 0], 'edu': datas[:, 1], 'position': datas[:, 2], 'keys': datas[:, 3]}) count(df, 'exp', '经验') # 按经验统计 count(df, 'edu', '学历') # 按学历统计 count(df, 'position', '职位') # 按职位统计 def count(df, idx, name): ''' 分组统计 ''' print(('按' + name + '分组').center(60, '-')) c = df[idx].value_counts(sort=True) print(c) if __name__ == '__main__': # 读取并清洗数据 datas = np.array(load_datas()) analysis(datas)
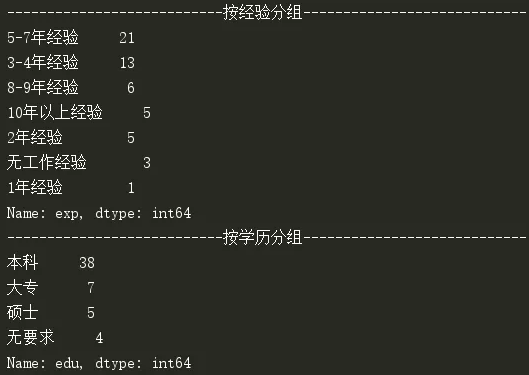
5~7年经验果然是最容易找到高薪职位的,而且用人单位大多要求本科学历。
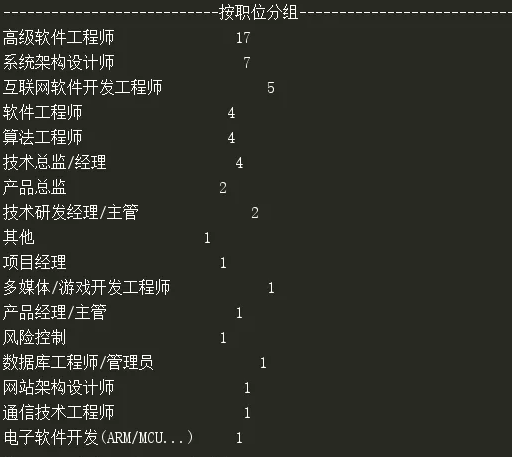
职能的统计比较杂乱,高级软件工程师和架构师的岗位较多,项目经理这类职位的薪水一般低于工程师,这也和预计的相同:
技能关键字看起来并不友好:

第一条记录很好地反应了技能要求,第二条就没什么用了,这是由于关键字信息是HR自行添加的,大多数HR都不太了解技术,因此也就出现了像第二条那样对本次分析没什么作用的关键字。
看来得求助于一些分词技术,从职位信息中抽取一些关键字。
下篇继续,看看哪些技能是抢手的。
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注公作者众号“我是8位的”
