某个工厂生产了一批手机屏幕,为了评判手机屏幕的质量是否达到标准,质检员需要收集每个样本的若干项指标,比如大小、质量、光泽度等,根据这些指标进行打分,最后判断是否合格。现在为了提高效率,工厂决定使用智能检测进行第一步筛选,质检员只需要重点检测被系统判定为“不合格”的样本。
智能检测程序需要根据大量样本训练一个函数模型,也许我们的第一个想法是像监督学习那样,为样本打上“正常”和“异常”的标签,然后通过分类算法训练模型。假设xtest是数据样本,predict(xtest)来判断xtest是否是合格样本。某个偷懒的家伙写下了这样的代码:
def predict(xtest): return 1
由于工厂的质量管理过硬,仅有极少数不合格样本,因此这段荒唐的预测居然展现出极高的准确率!这是由于严重的数据偏斜导致的,或许我们可以通过查准率(Precision)和召回率(Recall)两个指标识别出这段不负责任的代码,但是当你再次试图使用某个监督学习算法时,仍然会面对同样的问题——仅有极少数不合格样本,以至于监督学习无法学到足够的知识。能否从极度偏斜的数据中学习出一个有效的检测模型呢?当然能,这就是基于统计的异常检测。这类方法通常会假设给定的数据集服从一个随机分布模型,将与模型不一致的样本视为异常样本。其中最常用的两种分布模型是一元正态分布模型和多元正态分布模型。
算法模型
在正态分布的假设下,如果有一个新样本x,当x的正态分布值小于某个阈值时,就可以认为这个样本是异常的。

在正态分布中,μ-3σ<=x<=μ+3σ的区域包含了绝大部分数据,可以以此为参考,调整ε的值:
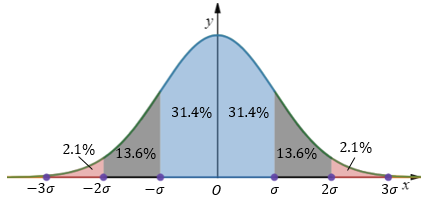
现在有一个包含了m个一维数据的训练集:

可以通过下面的函数判断一个样本是否是异常的:

这里x(i)是已知的,μ和σ才是未知的,我们的目的是设法根据训练集求得μ和σ的值,以得到一个确定的函数模型。具体来说,通过最大似然估计量可以得出下面的结果:
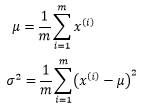
具体推导过程参考 概率笔记11——一维正态分布的最大似然估计
算法实现
我们通过一些模拟数据来一窥异常检测算法的究竟。
1 import numpy as np 2 import matplotlib.pyplot as plt 3 4 def create_data(): 5 ''' 6 创建训练数据和测试数据 7 :return: X_train:训练集, X_test:测试集 8 ''' 9 np.random.seed(42) # 设置seed使每次生成的随机数都相等 10 m, s = 3, 0.1 # 设置均值和方差 11 X_train = np.random.normal(m, s, 100) # 100个一元正态分布数据 12 # 构造10测试数据,从一个均匀分布[low,high)中随机采样 13 X_test = np.random.uniform(low=m - 1, high=m + 1, size=10) 14 return X_train, X_test 15 16 def plot_data(X_train, X_test): 17 ''' 18 数据可视化 19 :param X_train: 训练集 20 :param X_test: 测试集 21 :return: 22 ''' 23 fig = plt.figure(figsize=(10, 4)) 24 plt.subplots_adjust(wspace=0.5) # 调整子图之间的左右边距 25 fig.add_subplot(1, 2, 1) # 绘制训练数据的分布 26 plt.scatter(X_train, [0] * len(X_train), color='blue', marker='x', label='训练数据') 27 plt.title('训练数据的分布情况') 28 plt.xlabel('x') 29 plt.ylabel('y') 30 plt.legend(loc='upper left') 31 32 fig.add_subplot(1, 2, 2) # 绘制整体数据的分布 33 plt.scatter(X_train, [0] * len(X_train), color='blue', marker='x', label='训练数据') 34 plt.scatter(X_test, [0] * len(X_test), color='red', marker='^',label='测试数据') 35 plt.title('整体数据的分布情况') 36 plt.xlabel('x') 37 plt.ylabel('y') 38 plt.legend(loc='upper left') 39 40 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 41 plt.rcParams['axes.unicode_minus'] = False # 解决中文下的坐标轴负号显示问题 42 plt.show() 43 44 def fit(X_train): 45 ''' 46 拟合数据,训练模型 47 :param X_train: 训练集 48 :return: mu:均值, sigma:方差 49 ''' 50 global mu, sigma 51 mu = np.mean(X_train) # 计算均值μ 52 sigma = np.var(X_train) # 计算方差 σ^2 53 54 def gaussian(X): 55 ''' 56 计算正态分布 57 :param X: 数据集 58 :return: 数据集的密度值 59 ''' 60 return np.exp(-((X - mu) ** 2) / (2 * sigma)) / (np.sqrt(2 * np.pi) * np.sqrt(sigma)) 61 62 def get_epsilon(n=3): 63 ''' 调整ε的值,默认ε=3σ ''' 64 return np.sqrt(sigma) * n 65 66 def predict(X): 67 ''' 68 检测训练集中的数据是否是正常数据 69 :param X: 待预测的数据 70 :return: P1:数据的密度值, P2:数据的异常检测结果,True正常,False异常 71 ''' 72 P1 = gaussian(X) # 数据的密度值 73 epsilon = get_epsilon() 74 P2 = [p > epsilon for p in P1] # 数据的异常检测结果,True正常,False异常 75 return P1, P2 76 77 def plot_predict(X): 78 '''可视化异常检测结果 ''' 79 epsilon = get_epsilon() 80 xs = np.linspace(mu - epsilon, mu + epsilon, 50) 81 ys = gaussian(xs) 82 plt.plot(xs, ys, c='g', label='拟合曲线') # 绘制正态分布曲线 83 84 P1, P2 = predict(X) 85 normals_idx = [i for i, t in enumerate(P2) if t == True] # 正常数据的索引 86 plt.scatter([X[i] for i in normals_idx], [P1[i] for i in normals_idx], 87 color='blue', marker='x', label='正常数据') 88 outliers_idx = [i for i, t in enumerate(P2) if t == False] # 异常数据的索引 89 plt.scatter([X[i] for i in outliers_idx], [P1[i] for i in outliers_idx], 90 color='red', marker='^', label='异常数据') 91 plt.title('检测结果,共有{}个异常数据'.format(len(outliers_idx))) 92 plt.xlabel('x') 93 plt.ylabel('y') 94 plt.legend(loc='upper left') 95 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 96 plt.rcParams['axes.unicode_minus'] = False # 解决中文下的坐标轴负号显示问题 97 plt.show() 98 99 if __name__ == '__main__': 100 mu, sigma = 0, 0 # 模型的均值μ和方差σ^2 101 X_train, X_test = create_data() 102 plot_data(X_train, X_test) 103 fit(X_train) 104 print('μ = {}, σ^2 = {}'.format(mu, sigma)) 105 plot_predict(np.r_[X_train, X_test])
create_data()创建了100个满足X~N(μ,σ2)的数据作为训练集;10个在 之间均匀分布的数据作为测试数据,它们极有可能是异常数据。plot_data()可视化了训练集,再把测试数据加进去一并展示:
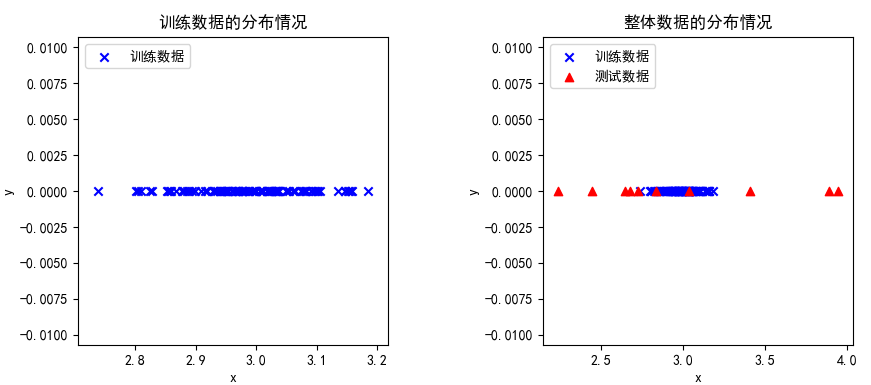
可以看出,大部分训练数据都集中在正态分布的均值区域,而异常数据偏向于“倒钟”的两端。
接下来使用fit()方法对异常检测模型进行训练,得到的结果是μ = 2.98961534826059, σ^2 = 0.008165221946938589。
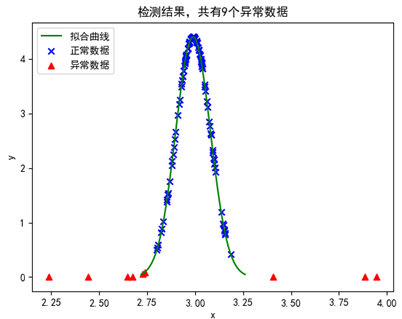
得到了模型参数后就可以使用目标函数对数据进行预测。gussian(X)实现了正态分布的密度函数;predict(X)将对X中的所有样本进行检测,并返回X对应的检测结果列表。其可视化结果是:
一元模型的问题
在面对多维数据时,基于一元正态分布的异常检测可以单独抽取某一维度进行检测,通常也能工作的很好,但这里有一个假设—所有维度都符合正态分布,并且各维度都是独立的,如果两个维度之间存在相关性,那么基于一元正态分布的异常检测就可能会出现很大程度的误判。
人的身高和鞋码存在着关联关系,一般来说,身高是脚长的7倍左右。假设某地区成年男子的身高符合μ=1.7,σ2=0.036的正态分布,我们用下面的代码模拟身高和脚长的数据。
1 import numpy as np 2 import matplotlib.pyplot as plt 3 4 def create_train(): 5 ''' 6 构造2维训练集 7 :return: X1:第1纬度的列, X2:第2维度的列表 8 ''' 9 np.random.seed(21) # 设置seed使每次生成的随机数都相等 10 mu, sigma = 1.7, 0.036 # 设置均值和方差 11 X1 = np.random.normal(mu, sigma, 200) # 生成200个符合正态分布的身高数据 12 # 设置身高对应的鞋码,鞋码=身高/7±0.02 13 X2 = (X1 / 7) + np.random.uniform(low=-0.01, high=0.01, size=len(X1)) 14 return X1, X2 15 16 def plot_train(X1, X2): 17 ''' 18 可视化训练集 19 :param X1: 训练集的第1维度 20 :param X2: 训练集的第2维度 21 ''' 22 fig = plt.figure(figsize=(10, 4)) 23 plt.subplots_adjust(hspace=0.5) # 调整子图之间的上下边距 24 # 数据的散点图 25 fig.add_subplot(2, 1, 1) 26 plt.scatter(X1, X2, color='k', s=3., label='训练数据') 27 plt.legend(loc='upper left') 28 plt.xlabel('身高') 29 plt.ylabel('脚长') 30 plt.title('数据分布') 31 # x1维度的直方图 32 fig.add_subplot(2, 2, 3) 33 plt.hist(X1, bins=40) 34 plt.xlabel('身高') 35 plt.ylabel('频度') 36 plt.title('身高直方图') 37 # x2维度的直方图 38 fig.add_subplot(2, 2, 4) 39 plt.hist(X2, bins=40) 40 plt.xlabel('脚长') 41 plt.ylabel('频度') 42 plt.title('脚长直方图') 43 44 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 45 plt.rcParams['axes.unicode_minus'] = False # 解决中文下的坐标轴负号显示问题 46 plt.show() 47 48 49 if __name__ == '__main__': 50 X1_train, X2_train = create_train() 51 plot_train(X1_train, X2_train)
create_train()方法先是构造了符合正态分布的身高数据,之后根据身高构造脚长,并为脚长加入了在±0.01之间的噪声,以便使脚长产生一些震荡。plot_train(X1, X2)用散点图和直方图的形式将数据可视化:
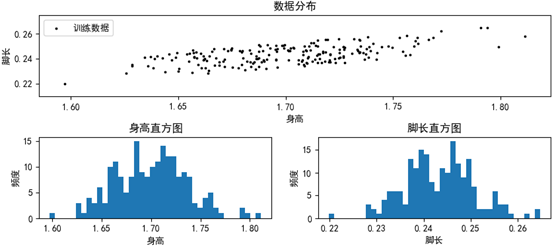
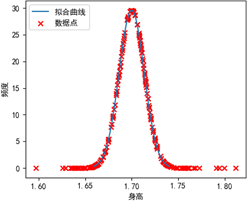
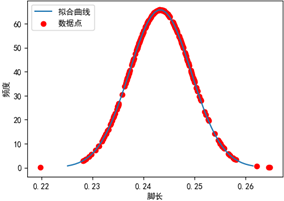
从上面的直方图可以看出,身高和与之存在线性相关性的脚长都符合正态分布。我们可以用前面的代码的计算两个维度的均值和方差,在根据这些参数画出每个维度的拟合曲线。
就训练集而言,低于1.6米或高于1.8米的身高被认为偏向于异常值,与这些身高有关联关系的脚长的数值也被认为偏向于异常值。现在有一个1.73米、脚长是0.23米的人,这个小脚男士远离了大部分样本点,应当被视为异常数据:
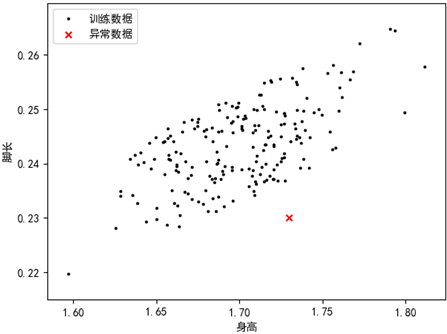
现在的问题是,对于身高的分布来说,1.73米是一个大众化的身高,对于脚长来说,0.23米也不算太差:
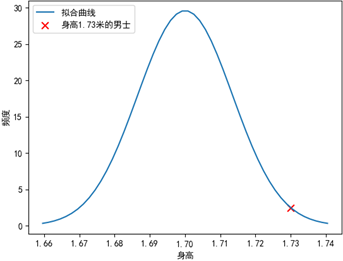
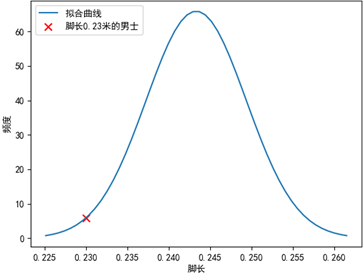
无论从身高维度还是脚长维度,这个小脚男士都被认为是正常数据,这与我们期望的结果不符。其原因是一元正态分布分别从两个独立的维度看待问题,而忽略了这两个维度间的相关性。为了识别相关性,我们需要使用更高维度的正态分布模型。(下篇继续)
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注公作者众号“我是8位的”
