窗口计算
我们经常需要在一个时间窗口维度上对数据进行聚合,窗口是流处理应用中经常需要解决的问题。Flink的窗口算子为我们提供了方便易用的API,我们可以将数据流切分成一个个窗口,对窗口内的数据进行处理
按照有没有进行keyby分成了两种 不同的处理方式:
-
首先,我们要决定是否对一个DataStream按照Key进行分组,这一步必须在窗口计算之前进行。
-
windowAll不对数据流进行分组,所有数据将发送到后续执行的算子单个实例上。
-
经过windowAll的算子是不分组的窗口(Non-Keyed Window),它们的原理和操作与Keyed Window类似,唯一的区别在于所有数据将发送给下游的单个实例,或者说下游算子的并行度为1。
// Keyed Window
stream
.keyBy(...) <- 按照一个Key进行分组
.window(...) <- 将数据流中的元素分配到相应的窗口中
[.trigger(...)] <- 指定触发器Trigger(可选)
[.evictor(...)] <- 指定清除器Evictor(可选)
.reduce/aggregate/process() <- 窗口处理函数Window Function
// Non-Keyed Window
stream
.windowAll(...) <- 不分组,将数据流中的所有元素分配到相应的窗口中
[.trigger(...)] <- 指定触发器Trigger(可选)
[.evictor(...)] <- 指定清除器Evictor(可选)
.reduce/aggregate/process() <- 窗口处理函数Window Function
窗口生命周期
- 一个窗口在第一个属于它的元素到达时就会被创建,然后在时间(event 或 processing time) 超过窗口的“结束时间戳 + 用户定义的 allowed lateness (详见 Allowed Lateness)”时 被完全删除.
对于一个基于 event time 且范围互不重合(滚动)的窗口策略, 如果窗口设置的时长为五分钟、可容忍的迟到时间(allowed lateness)为 1 分钟, 那么第一个元素落入 12:00 至 12:05 这个区间时,Flink 就会为这个区间创建一个新的窗口。 当 watermark 越过 12:06 时,这个窗口将被摧毁。
-
每个窗口会设置自己的 Trigger 和 function (ProcessWindowFunction、ReduceFunction、或 AggregateFunction, )。该 function 决定如何计算窗口中的内容, 而 Trigger 决定何时窗口中的数据可以被 function 计算
-
也可以指定一个 Evictor ),在 trigger 触发之后,Evictor 可以在窗口函数的前后删除数据。
Window Assigners
-
Window assigner 定义了 stream 中的元素如何被分发到各个窗口
-
Flink 为最常用的情况提供了一些定义好的 window assigner,也就是 tumbling windows、 sliding windows、 session windows 和 global windows。
-
可以继承 WindowAssigner 类来实现自定义的 window assigner。 所有内置的 window assigner(除了 global window)都是基于时间分发数据的,processing time 或 event time 均可
-
基于时间的窗口用 start timestamp(包含)和 end timestamp(不包含)描述窗口的大小。 在代码中,Flink 处理基于时间的窗口使用的是 TimeWindow, 它有查询开始和结束 timestamp 以及返回窗口所能储存的最大 timestamp 的方法 maxTimestamp()
滚动窗口(Tumbling Windows)
滚动窗口的大小是固定的,且各自范围之间不重叠
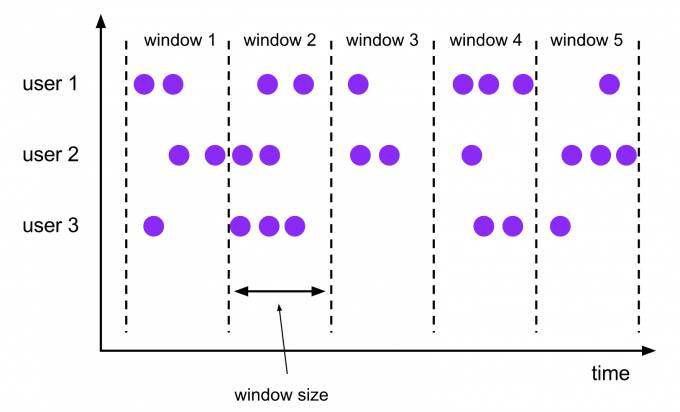
val input: DataStream[T] = ...
// 滚动 event-time 窗口
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// 滚动 processing-time 窗口
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// 长度为一天的滚动 event-time 窗口,偏移量为 -8 小时。
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
滑动窗口(Sliding Windows)
窗口大小是固定的,窗口有可能有重叠。窗口会有一个滑动步长
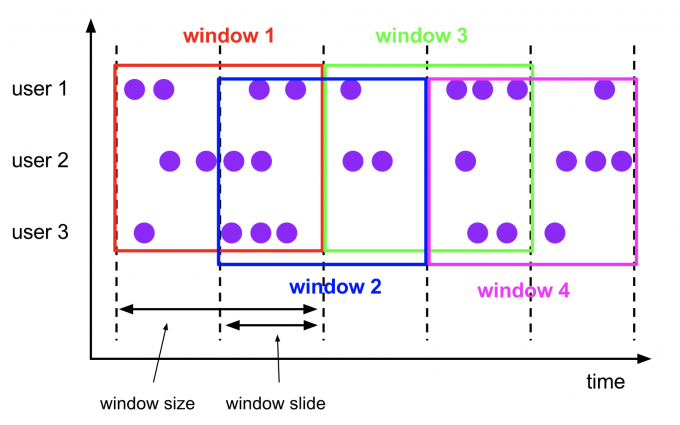
al input: DataStream[T] = ...
// 滑动 event-time 窗口
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// 滑动 processing-time 窗口
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// 滑动 processing-time 窗口,偏移量为 -8 小时
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
会话窗口(Session Windows)
窗口大小不固定,窗口之间会有一个间隙(gap).会话窗口根据Session gap切分不同的窗口,当一个窗口在大于Session gap的时间内没有接收到新数据时,窗口将关闭。在这种模式下,窗口的长度是可变的,每个窗口的开始和结束时间并不是确定的
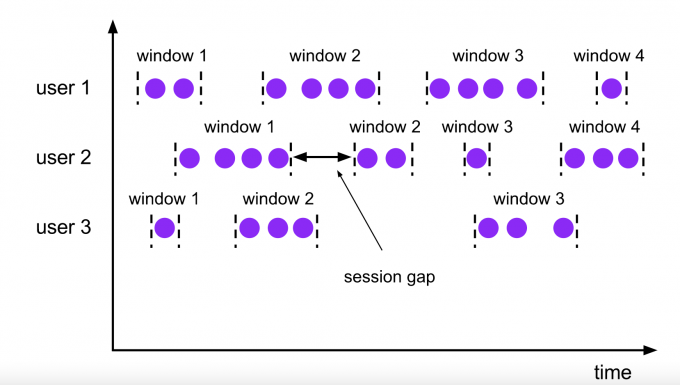
val input: DataStream[T] = ...
// 设置了固定间隔的 event-time 会话窗口
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>)
// 设置了动态间隔的 event-time 会话窗口
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// 决定并返回会话间隔
}
}))
.<windowed transformation>(<window function>)
// 设置了固定间隔的 processing-time 会话窗口
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>)
// 设置了动态间隔的 processing-time 会话窗口
input
.keyBy(<key selector>)
.window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// 决定并返回会话间隔
}
}))
.<windowed transformation>(<window function>)
全局窗口(Global Windows)
整个数据流是一个窗口,因为数据流是无界的,所以全局窗口默认情况下,永远不会触发计算数据, 要定义trigger

val input: DataStream[T] = ...
input
.keyBy(<key selector>)
.window(GlobalWindows.create())
.<windowed transformation>(<window function>)
窗口函数
窗口函数主要分为两种,一种是增量计算,如reduce和aggregate,一种是全量计算,如process。
- 增量计算指的是窗口保存一份中间数据,每流入一个新元素,新元素与中间数据两两合一,生成新的中间数据,再保存到窗口中
2.全量计算指的是窗口先缓存该窗口所有元素,等到触发条件后对窗口内的全量元素执行计算
ReduceFunction
ReduceFunction 指定两条输入数据如何合并起来产生一条输出数据,输入和输出数据的类型必须相同。 Flink 使用 ReduceFunction 对窗口中的数据进行增量聚合。
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce { (v1, v2) => (v1._1, v1._2 + v2._2) }
AggregateFunction
ReduceFunction 是 AggregateFunction 的特殊情况。 AggregateFunction 接收三个类型:输入数据的类型(IN)、累加器的类型(ACC)和输出数据的类型(OUT)。 输入数据的类型是输入流的元素类型,AggregateFunction 接口有如下几个方法: 把每一条元素加进累加器、创建初始累加器、合并两个累加器、从累加器中提取输出(OUT 类型
class AverageAggregate extends AggregateFunction[(String, Long), (Long, Long), Double] {
override def createAccumulator() = (0L, 0L)
override def add(value: (String, Long), accumulator: (Long, Long)) =
(accumulator._1 + value._2, accumulator._2 + 1L)
override def getResult(accumulator: (Long, Long)) = accumulator._1 / accumulator._2
override def merge(a: (Long, Long), b: (Long, Long)) =
(a._1 + b._1, a._2 + b._2)
}
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate)
ProcessWindowFunction
ProcessWindowFunction 有能获取包含窗口内所有元素的 Iterable, 以及用来获取时间和状态信息的 Context 对象,比其他窗口函数更加灵活。 ProcessWindowFunction 的灵活性是以性能和资源消耗为代价的, 因为窗口中的数据无法被增量聚合,而需要在窗口触发前缓存所有数据。
val input: DataStream[(String, Long)] = ...
input
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction())
/* ... */
class MyProcessWindowFunction extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
def process(key: String, context: Context, input: Iterable[(String, Long)], out: Collector[String]) = {
var count = 0L
for (in <- input) {
count = count + 1
}
out.collect(s"Window ${context.window} count: $count")
}
}
增量聚合的 ProcessWindowFunction
ProcessWindowFunction 可以与 ReduceFunction 或 AggregateFunction 搭配使用,它就可以增量聚合窗口的元素并且从 ProcessWindowFunction` 中获得窗口的元数据。
val input: DataStream[SensorReading] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(
(r1: SensorReading, r2: SensorReading) => { if (r1.value > r2.value) r2 else r1 },
( key: String,
context: ProcessWindowFunction[_, _, _, TimeWindow]#Context,
minReadings: Iterable[SensorReading],
out: Collector[(Long, SensorReading)] ) =>
{
val min = minReadings.iterator.next()
out.collect((context.window.getStart, min))
}
)
Triggers
Trigger 决定了一个窗口(由 window assigner 定义)何时可以被 window function 处理
Trigger 接口提供了五个方法来响应不同的事件:
- onElement() 方法在每个元素被加入窗口时调用。
- onEventTime() 方法在注册的 event-time timer 触发时调用。
- onProcessingTime() 方法在注册的 processing-time timer 触发时调用。
- onMerge() 方法与有状态的 trigger 相关。该方法会在两个窗口合并时, 将窗口对应 trigger 的状态进行合并,比如使用会话窗口时。
- clear() 方法处理在对应窗口被移除时所需的逻辑。
Evictors
Flink 的窗口模型允许在 WindowAssigner 和 Trigger 之外指定可选的 Evictor。 如本文开篇的代码中所示,通过 evictor(...) 方法传入 Evictor。 Evictor 可以在 trigger 触发后、调用窗口函数之前或之后从窗口中删除元素
Flink 内置有三个 evictor:
-
CountEvictor: 仅记录用户指定数量的元素,一旦窗口中的元素超过这个数量,多余的元素会从窗口缓存的开头移除
-
DeltaEvictor: 接收 DeltaFunction 和 threshold 参数,计算最后一个元素与窗口缓存中所有元素的差值, 并移除差值大于或等于 threshold 的元素。
-
TimeEvictor: 接收 interval 参数,以毫秒表示。 它会找到窗口中元素的最大 timestamp max_ts 并移除比 max_ts - interval 小的所有元素。
默认情况下,所有内置的 evictor 逻辑都在调用窗口函数前执行。
Allowed Lateness
默认情况下,watermark 一旦越过窗口结束的 timestamp,迟到的数据就会被直接丢弃。 但是 Flink 允许指定窗口算子最大的 allowed lateness。 Allowed lateness 定义了一个元素可以在迟到多长时间的情况下不被丢弃,这个参数默认是 0。 在 watermark 超过窗口末端、到达窗口末端加上 allowed lateness 之前的这段时间内到达的元素, 依旧会被加入窗口。取决于窗口的 trigger,一个迟到但没有被丢弃的元素可能会再次触发窗口,比如 EventTimeTrigger
val input: DataStream[T] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(<time>)
.<windowed transformation>(<window function>)
关于状态大小的考量
-
Flink 会为一个元素在它所属的每一个窗口中都创建一个副本
,设置一个大小为一天、滑动距离为一秒的滑动窗口可能不是个好想法 -
educeFunction 和 AggregateFunction 可以极大地减少储存需求,因为他们会就地聚合到达的元素, 且每个窗口仅储存一个值。而使用 ProcessWindowFunction 需要累积窗口中所有的元素
-
使用 Evictor 可以避免预聚合, 因为窗口中的所有数据必须先经过 evictor 才能进行计算