背景
平台任务主要分3种: flink实时任务, spark任务,还有java任务,spark、flink 我们是运行在yarn 上, 日常排错我们通过查看yarn logs来定位, 但是会对日志存储设置一定的保留时间, 为了后续更好排查问题,希望能够将spark、flink、java任务都收集起来存储到ES中,提供统一查询服务给用户. 这是设计的动机.
针对这个想法,主要要解决几个问题?
-
Flink、Spark、java 日志如何进行采集
-
如何在保证耦合度尽量低的情况下,同时保证不影响任务
-
部署方便, 用户端尽量少操作
调研
通过调研相关资料,选择基于Log4自定义Appender实现,实现方式比较优雅,轻量级, 好维护.
log4介绍
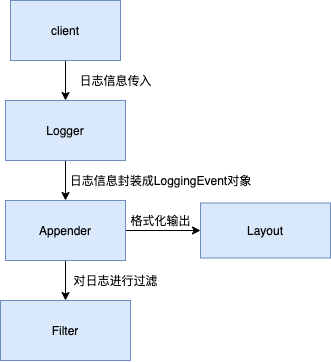
log4j主要有三个组件:
- Logger:负责供客户端代码调用,执行debug(Object msg)、info(Object msg)、warn(Object msg)、error(Object msg)等方法。
- Appender:负责日志的输出,Log4j已经实现了多种不同目标的输出方式,可以向文件输出日志、向控制台输出日志、向Socket输出日志等。
- Layout:负责日志信息的格式化。
调用log4j各组件执行顺序:
实现自定义log4j Appender:
- 继承log4j公共的基类:AppenderSkeleton
- 打印日志核心方法:abstract protected void append(LoggingEvent event);
- 初始化加载资源:public void activateOptions(),默认实现为空
- 释放资源:public void close()
- 是否需要按格式输出文本:public boolean requiresLayout()
正常情况下只需覆盖append方法即可。然后就可以在log4j中使用了
java任务采集
java任务, 只需要引入我们自己实现自定义的log4j Appender, 我们获取到相关的日志信息就可以进行后续操作.
Flink任务采集
Flink任务因为其提交在yarn上执行,我们需要采集除了日志信息之外,还要想办法获取任务对应的application id, 这样更方便用户查询对应日志,同时设计要满足可以进行查询taskManger,nodemanager各个节点日志
System.getProperty("sun.java.command") 获取当前正在执行的类, 根据其返回的字符串处理后,就可以获取需要的相关信息, 这个返回结果,我们在yarn log 是可以看到的,灵感也来与此
如何判断不同节点呢?
根据包含类 org.apache.flink.yarn.entrypoint.YarnJobClusterEntrypoint 判断是否是jobManager 日志
根据返回值包含org.apache.flink.yarn.YarnTaskExecutorRunner判断是否是taskManager节点日志
Spark任务采集
跟flink 处理类似
根据
org.apache.spark.executor.CoarseGrainedExecutorBackend 可以判断出是executor日志
org.apache.spark.deploy.yarn.ApplicationMaster 是driver日志
部署
1.log4j.properties 配置:
log4j.rootCategory=INFO, customlog, console
log4j.appender.customlog=com.aa.log.CustomlogAppender
29 log4j.appender.customlog.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
30 log4j.appender.customlog.layout=org.apache.log4j.PatternLayout
customlog 是我们自己定义的logAppender 实现
-
将自定义Appender程序打包
-
将其放到我们的Flink、Spark包下即可
-
java 程序采集要引入我们的jar,排除其它日志框架引入
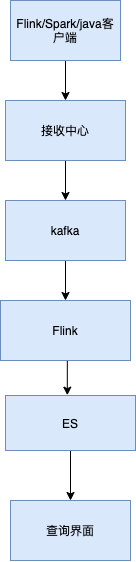
采集架构设计
-
通过log4j appender 将采集的日志发送到接收中心,这里注意搞个buffer,通过http批量发送到接收中心,日志太小过滤掉. 这里可以根据实际情况设置相应的策略,比如一分钟写入非常多的消息有可能用户乱打日志,我们就停止发送,避免将磁盘写满,影响其它用户使用
-
接收中心主要是负责接收到消息然后将其写入到kafka中.
-
Flink 消费kafka的日志,进行简单的清洗转换后将数据sink到es中
-
用户通过界面根据各种条件如applicationId、时间、不同角色节点筛选,搜索到对应日志
总结
本文主要介绍了下基于log4j 自定义appender,实现了大数据平台相关任务日志的采集,针对不同类型任务的处理,获取最终我们平台搜索需要的功能. 日志采集注意采集量过猛可能会将磁盘打满,需要有相应的降级或者预防措施,用户不会考虑太多关于平台相关的东西. 大数据平台技术目前各大公司很多技术架构都差不多,就看细节的处理了.