Scraoy入门实例一---Scrapy介绍与安装&PyCharm的安装&项目实战
一、Scrapy的安装
1.Scrapy介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说,网络抓取)所设计的,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
2.Scrapy安装
推荐使用Anaconda安装Scrapy
Anaconda是一个开源的包、环境管理神器,Anaconda包含了conda、Python在内的超过180个科学包及其依赖项。从官网下载安装Anaconda(Individual Edition),根据自己的系统选择下载,进行安装,选择next继续安装,Install for选项选Just for me,选择安装位置后,静待完成安装。
装好之后打开命令行,输入conda install scrapy,然后根据提示按Y,就会将Scrapy及其依赖的包全部下载下来,这样就完成了安装。
注意:在使用命令行安装scrapy包时,会出现下载超时的问题,即下载失败,我们可以通过修改其的镜像文件,以此来提高下载scrapy包的速度。可参考博客:https://blog.csdn.net/zhoulizhu/article/details/78809459
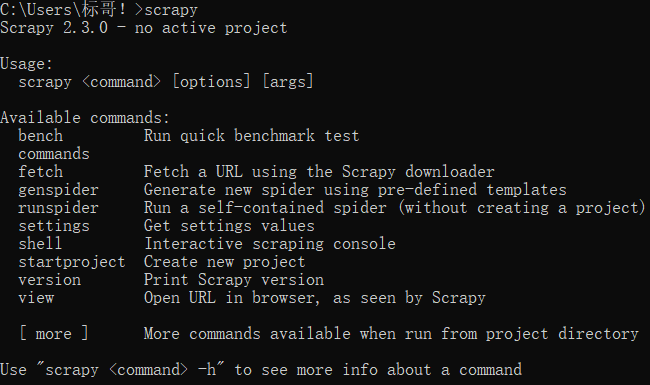
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy回车,如果显示如下界面就证明安装成功:
二、PyCharm的安装
1.PyCharm介绍
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
2.PyCharm安装
进入PyCharm的官网,直接点击DownLoad进行下载,左边是专业版,右边是社区版,社区版免费,专业版免费试用。
如果我们之前没有下载有Python解释器的话,在等待安装的时间我们可以去下载python解释器,进入Python官网,根据系统、版本下载对应的压缩包即可,在安装完后,在环境变量Path中配置Python解释器的安装路径。可参考博客:https://www.jb51.net/article/161175.htm
三、Scrapy抓取豆瓣项目实战
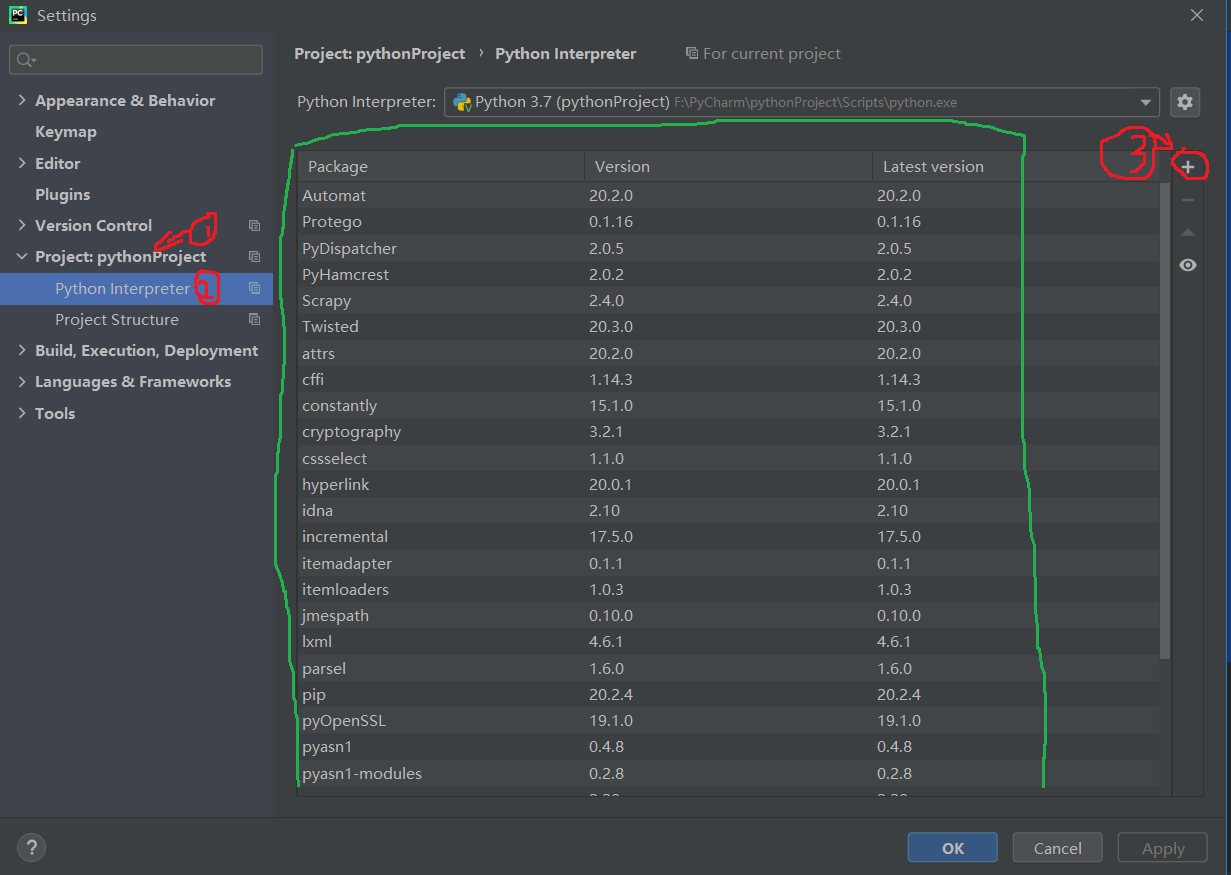
前提:在PyCharm中要使用Scrapy的话,必须先在PyCharm中安装所支持的Scrapy包,过程如下,点击文件(File)>> 设置(Settings...),步骤如下图,我安装Scrapy之前绿色框内只有两个Package,如果当你点击后看到有Scrapy包的话,那就不用安装了,直接进行接下来的操作即可
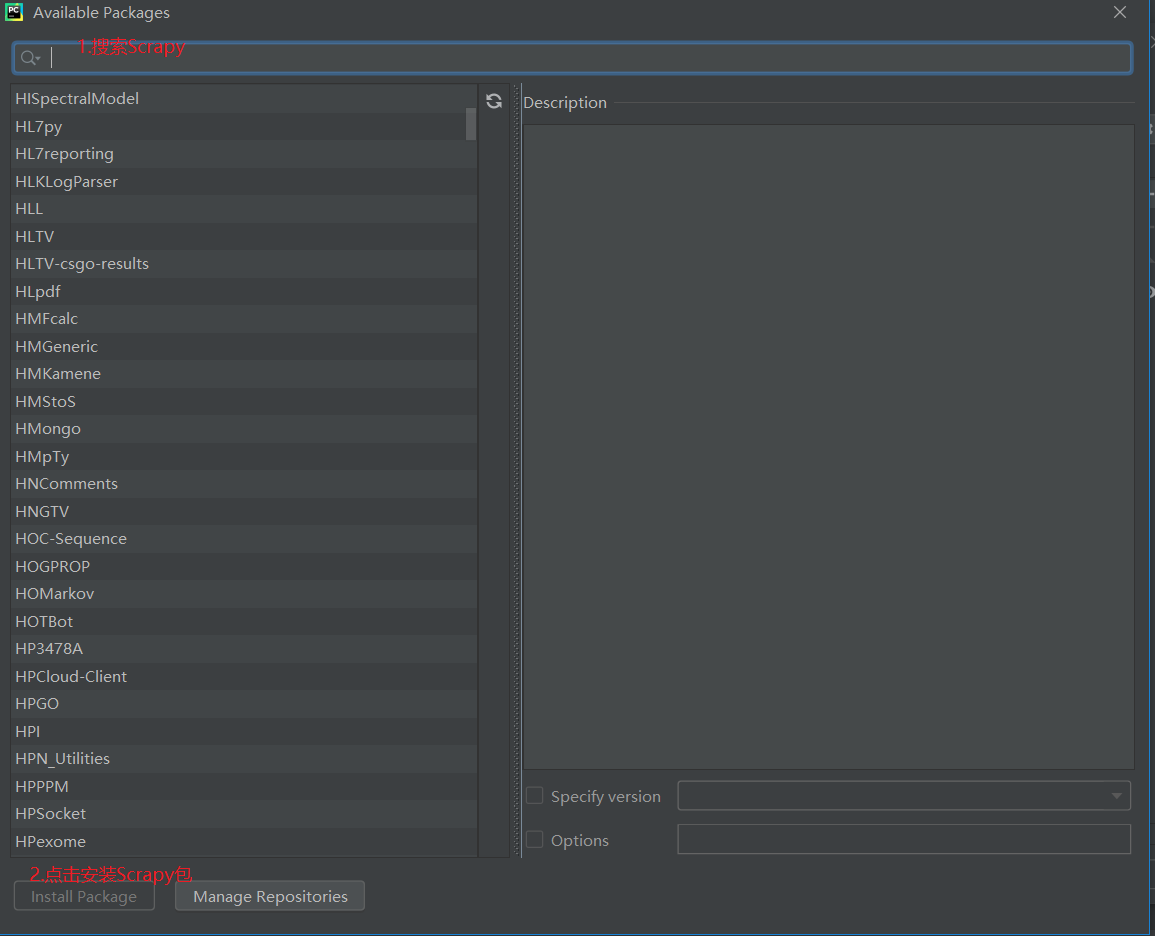
如果没有Scrapy包的话,点击“+” ,搜索Scrapy包,点击Install Package 进行安装
等待安装完成即可。
1.新建项目
打开刚安装好的PyCharm,使用pycharm工具在软件的终端,如果找不到PyCharm终端在哪,在左下角的底部的Terminal就是了

输入命令:scrapy startproject douban 这是使用命令行来新建一个爬虫项目,如下图所示,图片展示的项目名为pythonProject
接着在命令行输入命令:cd douban 进入已生成的项目根目录
接着继续在终端键入命令:scrapy genspider douban_spider movie.douban.com 生成douban_spider爬虫文件。
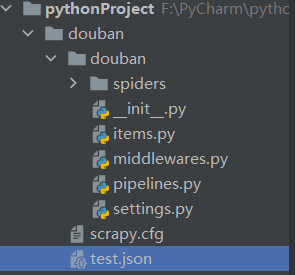
此时的项目结构如下图所示:
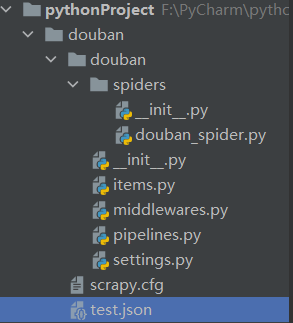
2.明确目标
我们要练习的网站为:https://movie.douban.com/top250
假设,我们抓取top250电影的序列号,电影名,介绍,星级,评价数,电影描述选项
此时,我们在items.py文件中定义抓取的数据项,代码如下:
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class DoubanItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 序列号 serial_number = scrapy.Field(); # 电影名 movie_name = scrapy.Field(); # 介绍 introduce = scrapy.Field(); # 星级 star = scrapy.Field(); # 评价数 evaluate = scrapy.Field(); # 描述 describe = scrapy.Field(); pass
3.接着,我们需要制作爬虫以及存储爬取内容
在douban_spider.py爬虫文件编写具体的逻辑代码,如下:
# -*- coding: utf-8 -*- import scrapy from ..items import DoubanItem class DoubanSpiderSpider(scrapy.Spider): name = 'douban_spider' # 允许的域名 allowed_domains = ['movie.douban.com'] # 入口URL start_urls = ['https://movie.douban.com/top250'] def parse(self, response): movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li") #循环电影的条目 for i_item in movie_list: #导入item,进行数据解析 douban_item = DoubanItem() douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first() douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first() #如果文件有多行进行解析 content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract() for i_content in content: content_s ="".join( i_content.split()) douban_item['introduce'] = content_s douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first() douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first() douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first() print(douban_item) yield douban_item #解析下一页,取后一页的XPATH next_link = response.xpath("//span[@class='next']/link/@href").extract() if next_link: next_link = next_link[0] yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
此时不需要运行这个python文件,因为我们不是单独使用它的,所以不用运行,允许会报错,有关import引入的问题,关于主目录的绝对路径与相对路径的问题,原因是我们使用了相对路径“..items”,相关的内容感兴趣的同学可以去网上查找有关这类问题的解释。
4.存储内容
将所爬取的内容存储成json或csv格式的文件
在命令行输入:scrapy crawl douban_spider -o test.json 或者 scrapy crawl douban_spider -o test.csv
将爬取到的数据存储到json文件或者csv文件里。
在执行完爬取命令后,将鼠标的焦点给到项目面板时,即会显示出生成的json文件或csv文件。打开json或csv文件后,如果里面什么内容都没有,那么我们还需要进行一步的修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
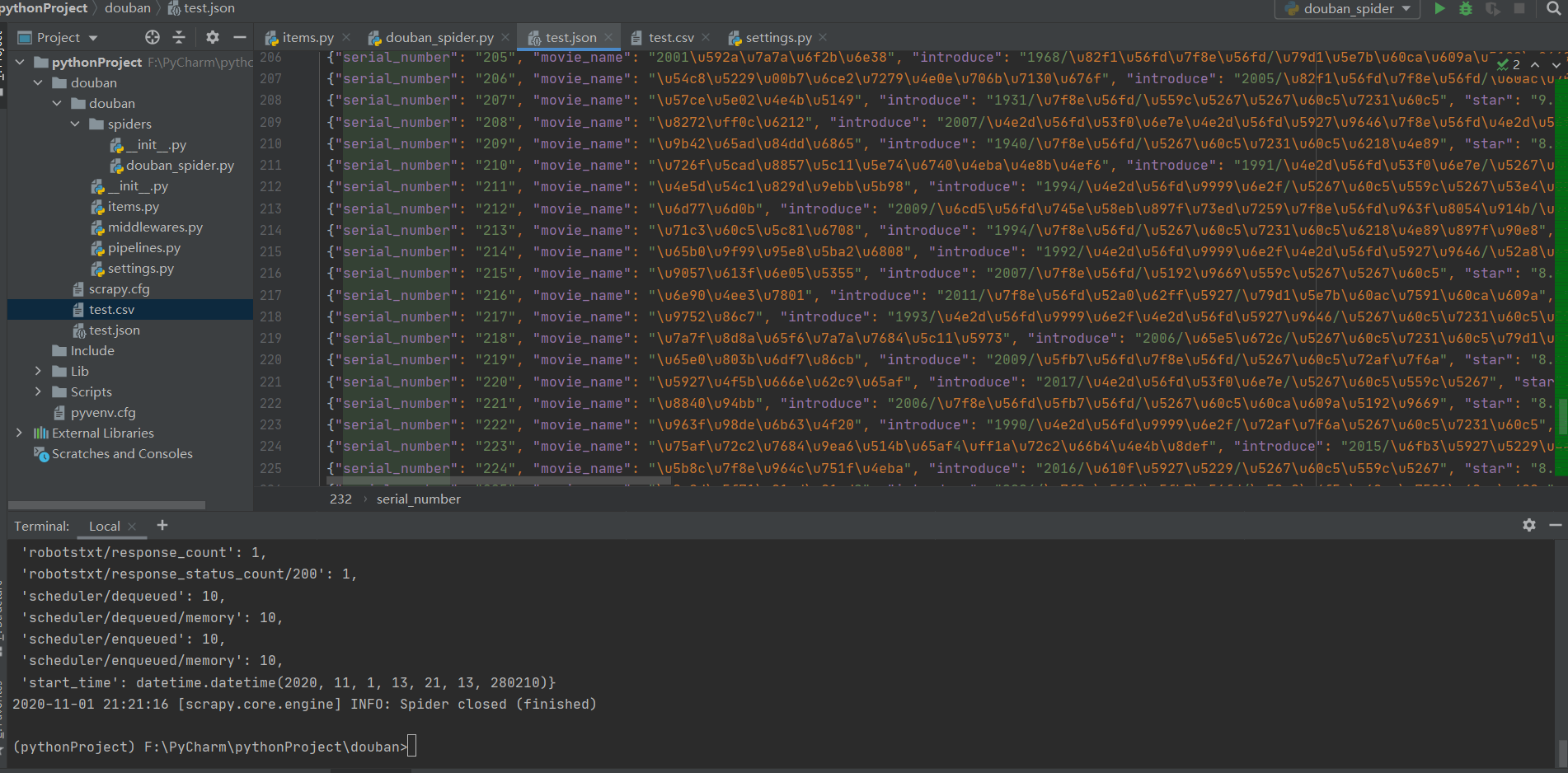
存储到json文件里的话,所有的内容都会以十六进制的形式显示出来,可以通过相应的方法进行转码,这里不过多的说明,如下图:
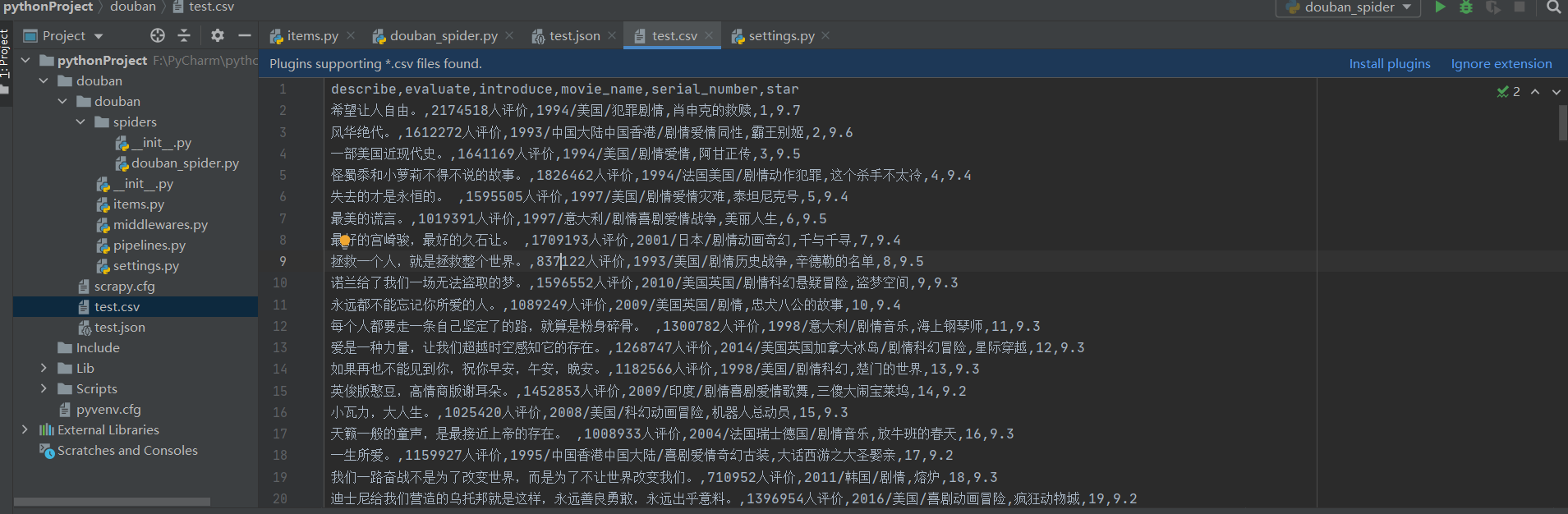
而存储在csv文件中,会直接将我们所要爬取的内容全部显示出来,如下图:
到此为止,我们已完成对网站特定内容的爬取,接下来,就需要对这些爬取的数据进行处理。
分割线----------------------------------------------------------------------------------------------------------------------分割线
Scraoy入门实例二---使用Pipeline实现
此次的实战需要重新创建一个项目,还是需要安装scrapy包,参考上面的内容,创建新项目的方法也参考上面的内容,这里不再重复赘述。
项目目录结构如下图所示:
一、Pipeline介绍
当我们通过Spider爬取数据,通过Item收集数据后,就要对数据进行一些处理了,因为我们爬取到的数据并不一定是我们想要的最终数据,可能还需要进行数据的清洗以及验证数据的有效性。Scripy中的Pipeline组件就用于数据的处理,一个Pipeline组件就是一个包含特定接口的类,通常只负责一种功能的数据处理,在一个项目中可以同时启用多个Pipeline。
二、在items.py中定义自己要抓取的数据
首先打开一个新的pycharm项目,通过终端建立新项目tutorial,在item中定义想要抓取的数据,例如电影名字,代码如下:
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class TutorialItem(scrapy.Item): # define the fields for your item here like: name = scrapy.Field() pass class DoubanmovieItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item pipe组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。定义的pipelines.py代码如下所示:
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter class TutorialPipeline(object): def process_item(self, item, spider): return item import time class DoubanmoviePipeline(object): def process_item(self, item, spider): now = time.strftime('%Y-%m-%d', time.localtime()) fileName = 'douban' + now + '.txt' with open(fileName, 'a', encoding='utf-8') as fp: fp.write(item['moiveName'][0]+" ") return item
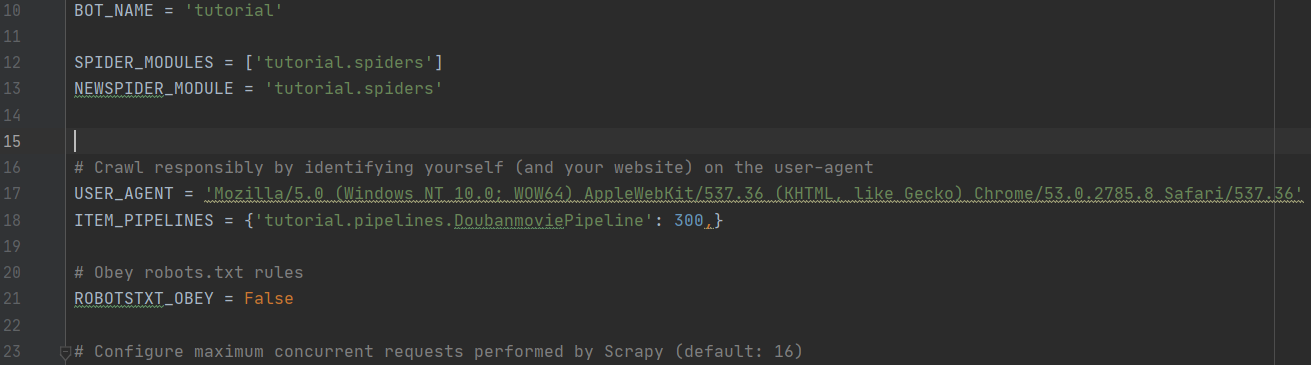
四、配置setting.py
由于这次使用了pipeline,所以需要我们在settings.py中打开pipelines通道注释,在里面新增一条,pipelines中添加的记录 ,如下图所示:
五、写爬虫文件
在tutoral/spiders目录下创建quotes_spider.py文件,目录结构如下,并写入初步的代码:
quotes_spider.py代码如下:
import scrapy from items import DoubanmovieItem class QuotesSpider(scrapy.Spider): name = "doubanSpider" allowed_domains = ['douban.com'] start_urls = ['http://movie.douban.com/cinema/nowplaying', 'http://movie.douban.com/cinema/nowplaying/beijing/'] def parse(self, response): print("--" * 20 ) #print(response.body) print("==" * 20 ) subSelector = response.xpath('//li[@class="stitle"]') items = [] for sub in subSelector: #print(sub.xpath('normalize-space(./a/text())').extract()) print(sub) item = DoubanmovieItem() item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract() items.append(item) print(items) return items
六、通过启动文件运行
在douban文件目录下新建启动文件 douban_spider_run.py (文件名称可以另取),并运行该文件,查看结果,编写代码如下:
from scrapy import cmdline cmdline.execute("scrapy crawl doubanSpider".split())
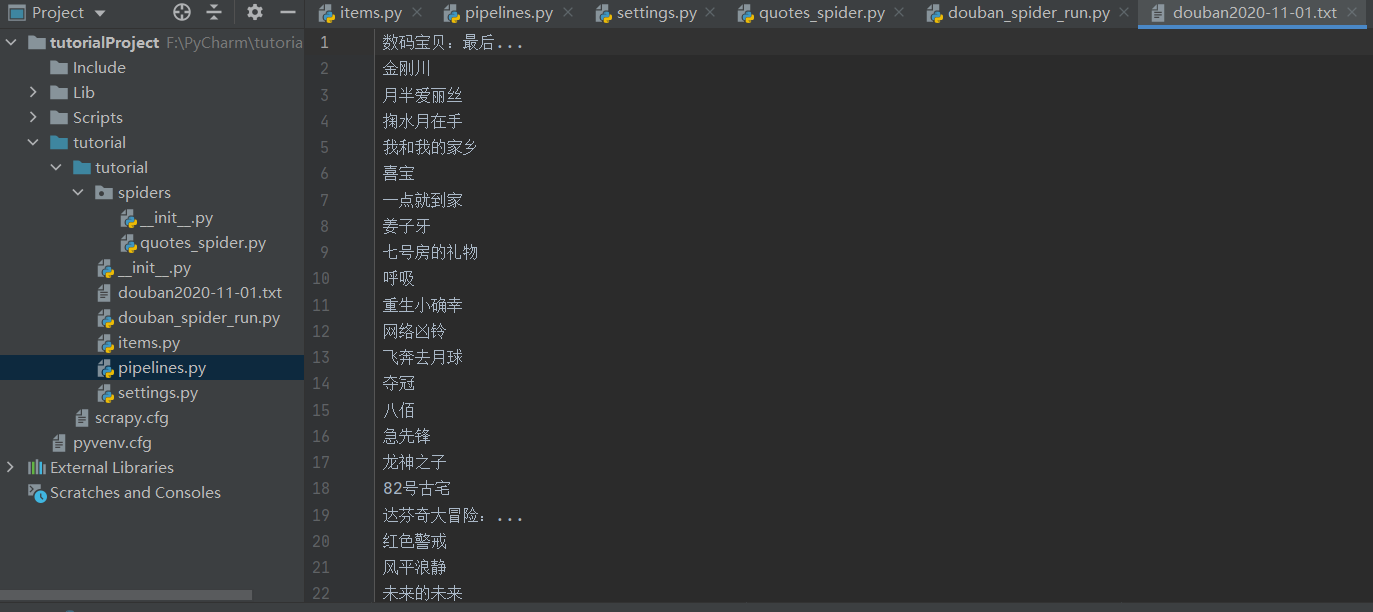
最后,经过处理后的爬取数据如下图所示(部分):
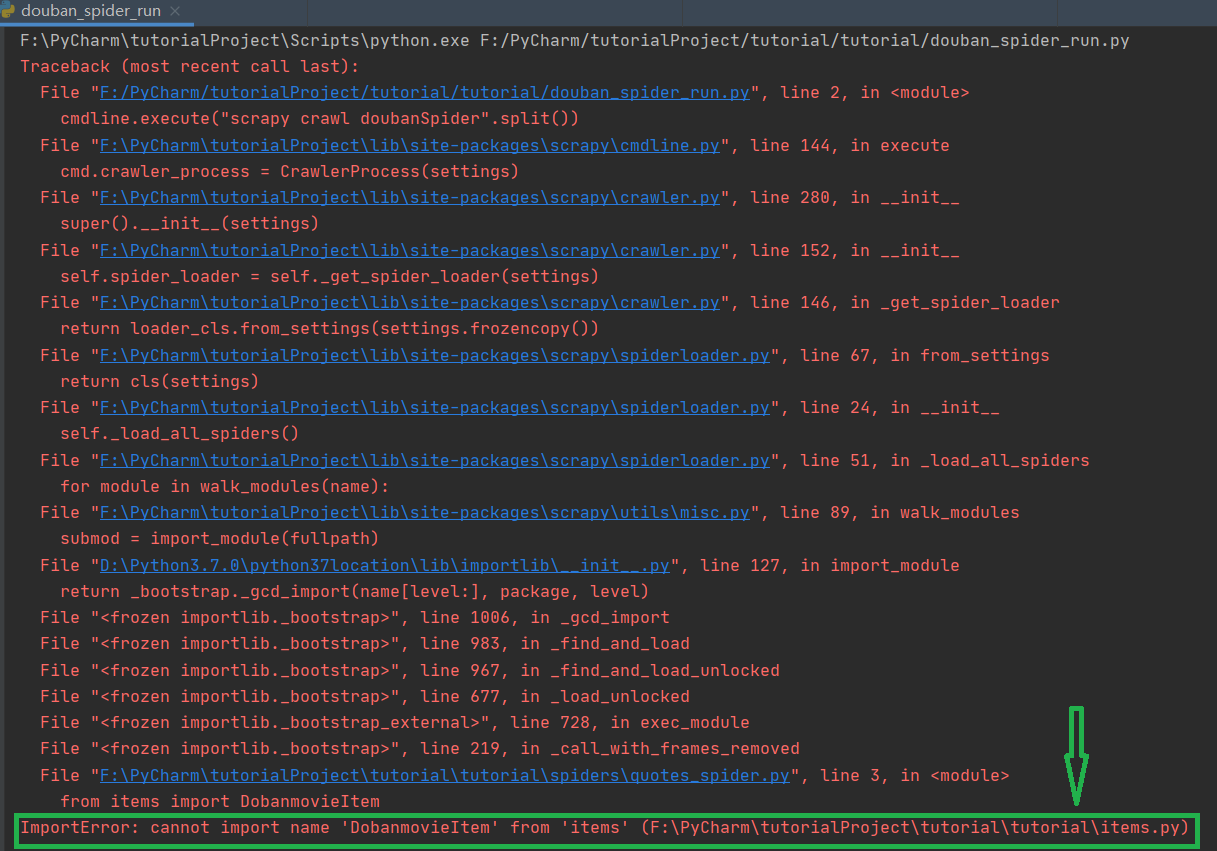
最后,希望大家在编写代码的时候能够细心点,不能马虎,我在实验的过程当中,就是因为将要引入的方法DoubanmovieItem写成了DobanmovieItem,从而导致了整个程序的运行失败,而且PyCharm还不告诉我哪里错了,我到处搜问题解决方法也没找到,最终核对了好多遍,生成方法时才发现,所以一定要细心。这个错误如下图所示,它提示说找不到DobanmovieItem这个模块,可能已经告诉我错误的地方了,因为我太菜了没发现,所以才耗费较长时间,希望大家引以为戒!
到此为止,使用Scrapy进行抓取网页内容,与对所抓取的内容进行清洗和处理的实验已经完成,要求对这个过程当中的代码与操作熟悉与运用,不会的去查找网上内容,消化吸收,记在脑子里,这才是真正学到知识,而不是照葫芦画瓢。