前言
最近在做一些Hadoop运维的相关工作,发现了一个有趣的问题,我们公司的Hadoop集群磁盘占比数值参差不齐,高的接近80%,低的接近40%,并没有充分利用好上面的资源,但是balance的操作跑的也是正常的啊,所以打算看一下Hadoop的balance的源代码,更深层次的去了解Hadoop Balance的机制。
Balancer和Distpatch
上面2个类的设计就是与Hadoop Balance操作最紧密联系的类,Balancer类负载找出<source, target>这样的起始,目标结果对,然后存入到Distpatch中,然后通过Distpatch进行分发,不过在分发之前,会进行block的验证,判断此block是否能被移动,这里会涉及到一些条件的判断,具体的可以通过后面的代码中的注释去发现。
在Balancer的最后阶段,会将source和Target加入到dispatcher中,详见下面的代码:
/**
* 根据源节点和目标节点,构造任务对
*/
private void matchSourceWithTargetToMove(Source source, StorageGroup target) {
long size = Math.min(source.availableSizeToMove(), target.availableSizeToMove());
final Task task = new Task(target, size);
source.addTask(task);
target.incScheduledSize(task.getSize());
//加入分发器中
dispatcher.add(source, target);
LOG.info("Decided to move "+StringUtils.byteDesc(size)+" bytes from "
+ source.getDisplayName() + " to " + target.getDisplayName());
}/**
* For each datanode, choose matching nodes from the candidates. Either the
* datanodes or the candidates are source nodes with (utilization > Avg), and
* the others are target nodes with (utilization < Avg).
*/
private <G extends StorageGroup, C extends StorageGroup>
void chooseStorageGroups(Collection<G> groups, Collection<C> candidates,
Matcher matcher) {
for(final Iterator<G> i = groups.iterator(); i.hasNext();) {
final G g = i.next();
for(; choose4One(g, candidates, matcher); );
if (!g.hasSpaceForScheduling()) {
//如果候选节点没有空间调度,则直接移除掉
i.remove();
}
}
} /**
* Decide all <source, target> pairs and
* the number of bytes to move from a source to a target
* Maximum bytes to be moved per storage group is
* min(1 Band worth of bytes, MAX_SIZE_TO_MOVE).
* 从源节点列表和目标节点列表中各自选择节点组成一个个对,选择顺序优先为同节点组,同机架,然后是针对所有
* @return total number of bytes to move in this iteration
*/
private long chooseStorageGroups() {
// First, match nodes on the same node group if cluster is node group aware
if (dispatcher.getCluster().isNodeGroupAware()) {
//首先匹配的条件是同节点组
chooseStorageGroups(Matcher.SAME_NODE_GROUP);
}
// Then, match nodes on the same rack
//然后是同机架
chooseStorageGroups(Matcher.SAME_RACK);
// At last, match all remaining nodes
//最后是匹配所有的节点
chooseStorageGroups(Matcher.ANY_OTHER);
return dispatcher.bytesToMove();
}
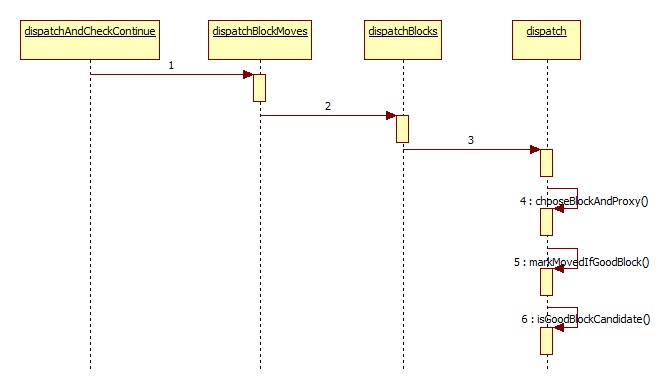
最后核心的检验block块是否合适的代码为下面这个:
/**
* Decide if the block is a good candidate to be moved from source to target.
* A block is a good candidate if
* 1. the block is not in the process of being moved/has not been moved;
* 移动的块不是正在被移动的块
* 2. the block does not have a replica on the target;
* 在目标节点上没有移动的block块
* 3. doing the move does not reduce the number of racks that the block has
* 移动之后,不同机架上的block块的数量应该是不变的.
*/
private boolean isGoodBlockCandidate(Source source, StorageGroup target,
DBlock block) {
if (source.storageType != target.storageType) {
return false;
}
// check if the block is moved or not
//如果所要移动的块是存在于正在被移动的块列表,则返回false
if (movedBlocks.contains(block.getBlock())) {
return false;
}
//如果移动的块已经存在于目标节点上,则返回false,将不会予以移动
if (block.isLocatedOn(target)) {
return false;
}
//如果开启了机架感知的配置,则目标节点不应该有相同的block
if (cluster.isNodeGroupAware()
&& isOnSameNodeGroupWithReplicas(target, block, source)) {
return false;
}
//需要维持机架上的block块数量不变
if (reduceNumOfRacks(source, target, block)) {
return false;
}
return true;
}下面是Balancer.java和Dispatch.java类的完整代码解析:
Balancer.java:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.hdfs.server.balancer;
import static com.google.common.base.Preconditions.checkArgument;
import java.io.IOException;
import java.io.PrintStream;
import java.net.URI;
import java.text.DateFormat;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.Collections;
import java.util.Date;
import java.util.Formatter;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
import java.util.Set;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hdfs.DFSConfigKeys;
import org.apache.hadoop.hdfs.DFSUtil;
import org.apache.hadoop.hdfs.HdfsConfiguration;
import org.apache.hadoop.hdfs.StorageType;
import org.apache.hadoop.hdfs.server.balancer.Dispatcher.DDatanode;
import org.apache.hadoop.hdfs.server.balancer.Dispatcher.DDatanode.StorageGroup;
import org.apache.hadoop.hdfs.server.balancer.Dispatcher.Source;
import org.apache.hadoop.hdfs.server.balancer.Dispatcher.Task;
import org.apache.hadoop.hdfs.server.balancer.Dispatcher.Util;
import org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy;
import org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault;
import org.apache.hadoop.hdfs.server.namenode.UnsupportedActionException;
import org.apache.hadoop.hdfs.server.protocol.DatanodeStorageReport;
import org.apache.hadoop.hdfs.server.protocol.StorageReport;
import org.apache.hadoop.util.StringUtils;
import org.apache.hadoop.util.Time;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import com.google.common.base.Preconditions;
/** <p>The balancer is a tool that balances disk space usage on an HDFS cluster
* when some datanodes become full or when new empty nodes join the cluster.
* The tool is deployed as an application program that can be run by the
* cluster administrator on a live HDFS cluster while applications
* adding and deleting files.
*
* <p>SYNOPSIS
* <pre>
* To start:
* bin/start-balancer.sh [-threshold <threshold>]
* Example: bin/ start-balancer.sh
* start the balancer with a default threshold of 10%
* bin/ start-balancer.sh -threshold 5
* start the balancer with a threshold of 5%
* To stop:
* bin/ stop-balancer.sh
* </pre>
*
* <p>DESCRIPTION
* <p>The threshold parameter is a fraction in the range of (1%, 100%) with a
* default value of 10%. The threshold sets a target for whether the cluster
* is balanced. A cluster is balanced if for each datanode, the utilization
* of the node (ratio of used space at the node to total capacity of the node)
* differs from the utilization of the (ratio of used space in the cluster
* to total capacity of the cluster) by no more than the threshold value.
* The smaller the threshold, the more balanced a cluster will become.
* It takes more time to run the balancer for small threshold values.
* Also for a very small threshold the cluster may not be able to reach the
* balanced state when applications write and delete files concurrently.
*
* <p>The tool moves blocks from highly utilized datanodes to poorly
* utilized datanodes iteratively. In each iteration a datanode moves or
* receives no more than the lesser of 10G bytes or the threshold fraction
* of its capacity. Each iteration runs no more than 20 minutes.
* 每次移动不超过10G大小,每次移动不超过20分钟。
* At the end of each iteration, the balancer obtains updated datanodes
* information from the namenode.
*
* <p>A system property that limits the balancer's use of bandwidth is
* defined in the default configuration file:
* <pre>
* <property>
* <name>dfs.balance.bandwidthPerSec</name>
* <value>1048576</value>
* <description> Specifies the maximum bandwidth that each datanode
* can utilize for the balancing purpose in term of the number of bytes
* per second. </description>
* </property>
* </pre>
*
* <p>This property determines the maximum speed at which a block will be
* moved from one datanode to another. The default value is 1MB/s. The higher
* the bandwidth, the faster a cluster can reach the balanced state,
* but with greater competition with application processes. If an
* administrator changes the value of this property in the configuration
* file, the change is observed when HDFS is next restarted.
*
* <p>MONITERING BALANCER PROGRESS
* <p>After the balancer is started, an output file name where the balancer
* progress will be recorded is printed on the screen. The administrator
* can monitor the running of the balancer by reading the output file.
* The output shows the balancer's status iteration by iteration. In each
* iteration it prints the starting time, the iteration number, the total
* number of bytes that have been moved in the previous iterations,
* the total number of bytes that are left to move in order for the cluster
* to be balanced, and the number of bytes that are being moved in this
* iteration. Normally "Bytes Already Moved" is increasing while "Bytes Left
* To Move" is decreasing.
*
* <p>Running multiple instances of the balancer in an HDFS cluster is
* prohibited by the tool.
*
* <p>The balancer automatically exits when any of the following five
* conditions is satisfied:
* <ol>
* <li>The cluster is balanced;
* <li>No block can be moved;
* <li>No block has been moved for five consecutive(连续) iterations;
* <li>An IOException occurs while communicating with the namenode;
* <li>Another balancer is running.
* </ol>
* 下面5种情况会导致Balance操作的失败
* 1、整个集群已经达到平衡状态
* 2、经过计算发现没有可以被移动的block块
* 3、在连续5次的迭代中,没有block块被移动
* 4、当datanode节点与namenode节点通信的时候,发生IO异常
* 5、已经存在一个Balance操作
*
* <p>Upon exit, a balancer returns an exit code and prints one of the
* following messages to the output file in corresponding to the above exit
* reasons:
* <ol>
* <li>The cluster is balanced. Exiting
* <li>No block can be moved. Exiting...
* <li>No block has been moved for 5 iterations. Exiting...
* <li>Received an IO exception: failure reason. Exiting...
* <li>Another balancer is running. Exiting...
* </ol>
* 在下面的5种情况下,balancer操作会自动退出
* 1、整个集群已经达到平衡的状态
* 2、经过计算发现没有可以被移动block块
* 3、在5论的迭代没有block被移动
* 4、接收端发生了I异常
* 5、已经存在一个balanr进程在工作
*
* <p>The administrator can interrupt the execution of the balancer at any
* time by running the command "stop-balancer.sh" on the machine where the
* balancer is running.
*/
@InterfaceAudience.Private
public class Balancer {
static final Log LOG = LogFactory.getLog(Balancer.class);
private static final Path BALANCER_ID_PATH = new Path("/system/balancer.id");
private static final long GB = 1L << 30; //1GB
private static final long MAX_SIZE_TO_MOVE = 10*GB;
private static final String USAGE = "Usage: java "
+ Balancer.class.getSimpleName()
+ "
[-policy <policy>] the balancing policy: "
+ BalancingPolicy.Node.INSTANCE.getName() + " or "
+ BalancingPolicy.Pool.INSTANCE.getName()
+ "
[-threshold <threshold>] Percentage of disk capacity"
+ "
[-exclude [-f <hosts-file> | comma-sperated list of hosts]]"
+ " Excludes the specified datanodes."
+ "
[-include [-f <hosts-file> | comma-sperated list of hosts]]"
+ " Includes only the specified datanodes.";
private final Dispatcher dispatcher;
private final BalancingPolicy policy;
private final double threshold;
// all data node lists
//四种datanode节点类型
private final Collection<Source> overUtilized = new LinkedList<Source>();
private final Collection<Source> aboveAvgUtilized = new LinkedList<Source>();
private final Collection<StorageGroup> belowAvgUtilized
= new LinkedList<StorageGroup>();
private final Collection<StorageGroup> underUtilized
= new LinkedList<StorageGroup>();
/* Check that this Balancer is compatible(兼容) with the Block Placement Policy
* used by the Namenode.
* 检测此balancer均衡工具是否于与目前的namenode节点所用的block存放策略相兼容
*/
private static void checkReplicationPolicyCompatibility(Configuration conf
) throws UnsupportedActionException {
if (!(BlockPlacementPolicy.getInstance(conf, null, null, null) instanceof
BlockPlacementPolicyDefault)) {
throw new UnsupportedActionException(
//如果不兼容则抛异常
"Balancer without BlockPlacementPolicyDefault");
}
}
/**
* Construct a balancer.
* Initialize balancer. It sets the value of the threshold, and
* builds the communication proxies to
* namenode as a client and a secondary namenode and retry proxies
* when connection fails.
*
* 构造一个balancer均衡器,设置threshold值,读取配置中的分发线程数的值
*/
Balancer(NameNodeConnector theblockpool, Parameters p, Configuration conf) {
final long movedWinWidth = conf.getLong(
DFSConfigKeys.DFS_BALANCER_MOVEDWINWIDTH_KEY,
DFSConfigKeys.DFS_BALANCER_MOVEDWINWIDTH_DEFAULT);
//移动线程数
final int moverThreads = conf.getInt(
DFSConfigKeys.DFS_BALANCER_MOVERTHREADS_KEY,
DFSConfigKeys.DFS_BALANCER_MOVERTHREADS_DEFAULT);
//分发线程数
final int dispatcherThreads = conf.getInt(
DFSConfigKeys.DFS_BALANCER_DISPATCHERTHREADS_KEY,
DFSConfigKeys.DFS_BALANCER_DISPATCHERTHREADS_DEFAULT);
final int maxConcurrentMovesPerNode = conf.getInt(
DFSConfigKeys.DFS_DATANODE_BALANCE_MAX_NUM_CONCURRENT_MOVES_KEY,
DFSConfigKeys.DFS_DATANODE_BALANCE_MAX_NUM_CONCURRENT_MOVES_DEFAULT);
this.dispatcher = new Dispatcher(theblockpool, p.nodesToBeIncluded,
p.nodesToBeExcluded, movedWinWidth, moverThreads, dispatcherThreads,
maxConcurrentMovesPerNode, conf);
this.threshold = p.threshold;
this.policy = p.policy;
}
/**
* 获取节点总容量大小
*/
private static long getCapacity(DatanodeStorageReport report, StorageType t) {
long capacity = 0L;
for(StorageReport r : report.getStorageReports()) {
if (r.getStorage().getStorageType() == t) {
capacity += r.getCapacity();
}
}
return capacity;
}
/**
* 获取节点剩余可用容量大小
*/
private static long getRemaining(DatanodeStorageReport report, StorageType t) {
long remaining = 0L;
for(StorageReport r : report.getStorageReports()) {
if (r.getStorage().getStorageType() == t) {
remaining += r.getRemaining();
}
}
return remaining;
}
/**
* Given a datanode storage set, build a network topology and decide
* over-utilized storages, above average utilized storages,
* below average utilized storages, and underutilized storages.
* The input datanode storage set is shuffled in order to randomize
* to the storage matching later on.
* 给定一个datanode集合,创建一个网络拓扑逻辑并划分出过度使用,使用率超出平均值,
* 低于平均值的,以及未能充分利用资源的4种类型
*
* @return the number of bytes needed to move in order to balance the cluster.
*/
private long init(List<DatanodeStorageReport> reports) {
// 计算平均使用率
for (DatanodeStorageReport r : reports) {
//累加每个节点上的使用空间
policy.accumulateSpaces(r);
}
//计算出平均值
policy.initAvgUtilization();
long overLoadedBytes = 0L, underLoadedBytes = 0L;
//进行使用率等级的划分,总共4种,over-utilized, above-average, below-average and under-utilized
for(DatanodeStorageReport r : reports) {
final DDatanode dn = dispatcher.newDatanode(r);
for(StorageType t : StorageType.asList()) {
final Double utilization = policy.getUtilization(r, t);
if (utilization == null) { // datanode does not have such storage type
continue;
}
final long capacity = getCapacity(r, t);
final double utilizationDiff = utilization - policy.getAvgUtilization(t);
final double thresholdDiff = Math.abs(utilizationDiff) - threshold;
//计算理论上最大移动空间
final long maxSize2Move = computeMaxSize2Move(capacity,
getRemaining(r, t), utilizationDiff, threshold);
final StorageGroup g;
if (utilizationDiff > 0) {
//使用率超出平均值,加入发送节点列表中
final Source s = dn.addSource(t, maxSize2Move, dispatcher);
if (thresholdDiff <= 0) { // within threshold
//如果在threshold范围之内,则加入aboveAvgUtilized
aboveAvgUtilized.add(s);
} else {
//否则加入overUtilized,并计算超出空间
overLoadedBytes += precentage2bytes(thresholdDiff, capacity);
overUtilized.add(s);
}
g = s;
} else {
//与上面的相反
g = dn.addStorageGroup(t, maxSize2Move);
if (thresholdDiff <= 0) { // within threshold
belowAvgUtilized.add(g);
} else {
underLoadedBytes += precentage2bytes(thresholdDiff, capacity);
underUtilized.add(g);
}
}
dispatcher.getStorageGroupMap().put(g);
}
}
logUtilizationCollections();
Preconditions.checkState(dispatcher.getStorageGroupMap().size()
== overUtilized.size() + underUtilized.size() + aboveAvgUtilized.size()
+ belowAvgUtilized.size(),
"Mismatched number of storage groups");
// return number of bytes to be moved in order to make the cluster balanced
return Math.max(overLoadedBytes, underLoadedBytes);
}
private static long computeMaxSize2Move(final long capacity, final long remaining,
final double utilizationDiff, final double threshold) {
final double diff = Math.min(threshold, Math.abs(utilizationDiff));
long maxSizeToMove = precentage2bytes(diff, capacity);
if (utilizationDiff < 0) {
maxSizeToMove = Math.min(remaining, maxSizeToMove);
}
return Math.min(MAX_SIZE_TO_MOVE, maxSizeToMove);
}
private static long precentage2bytes(double precentage, long capacity) {
Preconditions.checkArgument(precentage >= 0,
"precentage = " + precentage + " < 0");
return (long)(precentage * capacity / 100.0);
}
/* log the over utilized & under utilized nodes */
private void logUtilizationCollections() {
logUtilizationCollection("over-utilized", overUtilized);
if (LOG.isTraceEnabled()) {
logUtilizationCollection("above-average", aboveAvgUtilized);
logUtilizationCollection("below-average", belowAvgUtilized);
}
logUtilizationCollection("underutilized", underUtilized);
}
private static <T extends StorageGroup>
void logUtilizationCollection(String name, Collection<T> items) {
LOG.info(items.size() + " " + name + ": " + items);
}
/**
* Decide all <source, target> pairs and
* the number of bytes to move from a source to a target
* Maximum bytes to be moved per storage group is
* min(1 Band worth of bytes, MAX_SIZE_TO_MOVE).
* 从源节点列表和目标节点列表中各自选择节点组成一个个对,选择顺序优先为同节点组,同机架,然后是针对所有
* @return total number of bytes to move in this iteration
*/
private long chooseStorageGroups() {
// First, match nodes on the same node group if cluster is node group aware
if (dispatcher.getCluster().isNodeGroupAware()) {
//首先匹配的条件是同节点组
chooseStorageGroups(Matcher.SAME_NODE_GROUP);
}
// Then, match nodes on the same rack
//然后是同机架
chooseStorageGroups(Matcher.SAME_RACK);
// At last, match all remaining nodes
//最后是匹配所有的节点
chooseStorageGroups(Matcher.ANY_OTHER);
return dispatcher.bytesToMove();
}
/** Decide all <source, target> pairs according to the matcher. */
private void chooseStorageGroups(final Matcher matcher) {
/* first step: match each overUtilized datanode (source) to
* one or more underUtilized datanodes (targets).
*
* 把over组的数据移动under组中
*/
chooseStorageGroups(overUtilized, underUtilized, matcher);
/* match each remaining overutilized datanode (source) to
* below average utilized datanodes (targets).
* Note only overutilized datanodes that haven't had that max bytes to move
* satisfied in step 1 are selected
* 把over组的数据移动到below
*/
chooseStorageGroups(overUtilized, belowAvgUtilized, matcher);
/* match each remaining underutilized datanode (target) to
* above average utilized datanodes (source).
* Note only underutilized datanodes that have not had that max bytes to
* move satisfied in step 1 are selected.
*
* 然后,再把under组的数据移动一部分到above组中
*/
chooseStorageGroups(underUtilized, aboveAvgUtilized, matcher);
}
/**
* For each datanode, choose matching nodes from the candidates. Either the
* datanodes or the candidates are source nodes with (utilization > Avg), and
* the others are target nodes with (utilization < Avg).
*/
private <G extends StorageGroup, C extends StorageGroup>
void chooseStorageGroups(Collection<G> groups, Collection<C> candidates,
Matcher matcher) {
for(final Iterator<G> i = groups.iterator(); i.hasNext();) {
final G g = i.next();
for(; choose4One(g, candidates, matcher); );
if (!g.hasSpaceForScheduling()) {
//如果候选节点没有空间调度,则直接移除掉
i.remove();
}
}
}
/**
* For the given datanode, choose a candidate and then schedule it.
* @return true if a candidate is chosen; false if no candidates is chosen.
*/
private <C extends StorageGroup> boolean choose4One(StorageGroup g,
Collection<C> candidates, Matcher matcher) {
final Iterator<C> i = candidates.iterator();
final C chosen = chooseCandidate(g, i, matcher);
if (chosen == null) {
return false;
}
if (g instanceof Source) {
matchSourceWithTargetToMove((Source)g, chosen);
} else {
matchSourceWithTargetToMove((Source)chosen, g);
}
if (!chosen.hasSpaceForScheduling()) {
i.remove();
}
return true;
}
/**
* 根据源节点和目标节点,构造任务对
*/
private void matchSourceWithTargetToMove(Source source, StorageGroup target) {
long size = Math.min(source.availableSizeToMove(), target.availableSizeToMove());
final Task task = new Task(target, size);
source.addTask(task);
target.incScheduledSize(task.getSize());
//加入分发器中
dispatcher.add(source, target);
LOG.info("Decided to move "+StringUtils.byteDesc(size)+" bytes from "
+ source.getDisplayName() + " to " + target.getDisplayName());
}
/** Choose a candidate for the given datanode. */
private <G extends StorageGroup, C extends StorageGroup>
C chooseCandidate(G g, Iterator<C> candidates, Matcher matcher) {
if (g.hasSpaceForScheduling()) {
for(; candidates.hasNext(); ) {
final C c = candidates.next();
if (!c.hasSpaceForScheduling()) {
candidates.remove();
} else if (matcher.match(dispatcher.getCluster(),
g.getDatanodeInfo(), c.getDatanodeInfo())) {
//如果满足匹配的条件,则返回值
return c;
}
}
}
return null;
}
/* reset all fields in a balancer preparing for the next iteration */
private void resetData(Configuration conf) {
this.overUtilized.clear();
this.aboveAvgUtilized.clear();
this.belowAvgUtilized.clear();
this.underUtilized.clear();
this.policy.reset();
dispatcher.reset(conf);;
}
/** Run an iteration for all datanodes. */
private ExitStatus run(int iteration, Formatter formatter,
Configuration conf) {
try {
final List<DatanodeStorageReport> reports = dispatcher.init();
final long bytesLeftToMove = init(reports);
if (bytesLeftToMove == 0) {
System.out.println("The cluster is balanced. Exiting...");
return ExitStatus.SUCCESS;
} else {
LOG.info( "Need to move "+ StringUtils.byteDesc(bytesLeftToMove)
+ " to make the cluster balanced." );
}
/* Decide all the nodes that will participate in the block move and
* the number of bytes that need to be moved from one node to another
* in this iteration. Maximum bytes to be moved per node is
* Min(1 Band worth of bytes, MAX_SIZE_TO_MOVE).
*/
final long bytesToMove = chooseStorageGroups();
if (bytesToMove == 0) {
System.out.println("No block can be moved. Exiting...");
return ExitStatus.NO_MOVE_BLOCK;
} else {
LOG.info( "Will move " + StringUtils.byteDesc(bytesToMove) +
" in this iteration");
}
formatter.format("%-24s %10d %19s %18s %17s%n",
DateFormat.getDateTimeInstance().format(new Date()),
iteration,
StringUtils.byteDesc(dispatcher.getBytesMoved()),
StringUtils.byteDesc(bytesLeftToMove),
StringUtils.byteDesc(bytesToMove)
);
/* For each pair of <source, target>, start a thread that repeatedly
* decide a block to be moved and its proxy source,
* then initiates the move until all bytes are moved or no more block
* available to move.
* Exit no byte has been moved for 5 consecutive iterations.
*
* 如果发现在5次连续的迭代中还是没有字节被移动,则退出
*/
if (!dispatcher.dispatchAndCheckContinue()) {
return ExitStatus.NO_MOVE_PROGRESS;
}
return ExitStatus.IN_PROGRESS;
} catch (IllegalArgumentException e) {
System.out.println(e + ". Exiting ...");
return ExitStatus.ILLEGAL_ARGUMENTS;
} catch (IOException e) {
System.out.println(e + ". Exiting ...");
return ExitStatus.IO_EXCEPTION;
} catch (InterruptedException e) {
System.out.println(e + ". Exiting ...");
return ExitStatus.INTERRUPTED;
} finally {
dispatcher.shutdownNow();
}
}
/**
* Balance all namenodes.
* For each iteration,
* for each namenode,
* execute a {@link Balancer} to work through all datanodes once.
*
* 开放给外部调用的run方法
*/
static int run(Collection<URI> namenodes, final Parameters p,
Configuration conf) throws IOException, InterruptedException {
final long sleeptime = 2000*conf.getLong(
DFSConfigKeys.DFS_HEARTBEAT_INTERVAL_KEY,
DFSConfigKeys.DFS_HEARTBEAT_INTERVAL_DEFAULT);
LOG.info("namenodes = " + namenodes);
LOG.info("parameters = " + p);
final Formatter formatter = new Formatter(System.out);
System.out.println("Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved");
final List<NameNodeConnector> connectors
= new ArrayList<NameNodeConnector>(namenodes.size());
try {
for (URI uri : namenodes) {
final NameNodeConnector nnc = new NameNodeConnector(
Balancer.class.getSimpleName(), uri, BALANCER_ID_PATH, conf);
nnc.getKeyManager().startBlockKeyUpdater();
connectors.add(nnc);
}
boolean done = false;
for(int iteration = 0; !done; iteration++) {
done = true;
Collections.shuffle(connectors);
for(NameNodeConnector nnc : connectors) {
//初始化均衡器具
final Balancer b = new Balancer(nnc, p, conf);
//均衡器执行balance操作
final ExitStatus r = b.run(iteration, formatter, conf);
// clean all lists
b.resetData(conf);
if (r == ExitStatus.IN_PROGRESS) {
done = false;
} else if (r != ExitStatus.SUCCESS) {
//must be an error statue, return.
return r.getExitCode();
}
}
if (!done) {
Thread.sleep(sleeptime);
}
}
} finally {
for(NameNodeConnector nnc : connectors) {
nnc.close();
}
}
return ExitStatus.SUCCESS.getExitCode();
}
/* Given elaspedTime in ms, return a printable string */
private static String time2Str(long elapsedTime) {
String unit;
double time = elapsedTime;
if (elapsedTime < 1000) {
unit = "milliseconds";
} else if (elapsedTime < 60*1000) {
unit = "seconds";
time = time/1000;
} else if (elapsedTime < 3600*1000) {
unit = "minutes";
time = time/(60*1000);
} else {
unit = "hours";
time = time/(3600*1000);
}
return time+" "+unit;
}
static class Parameters {
static final Parameters DEFAULT = new Parameters(
BalancingPolicy.Node.INSTANCE, 10.0,
Collections.<String> emptySet(), Collections.<String> emptySet());
final BalancingPolicy policy;
final double threshold;
// exclude the nodes in this set from balancing operations
Set<String> nodesToBeExcluded;
//include only these nodes in balancing operations
Set<String> nodesToBeIncluded;
Parameters(BalancingPolicy policy, double threshold,
Set<String> nodesToBeExcluded, Set<String> nodesToBeIncluded) {
this.policy = policy;
this.threshold = threshold;
this.nodesToBeExcluded = nodesToBeExcluded;
this.nodesToBeIncluded = nodesToBeIncluded;
}
@Override
public String toString() {
return Balancer.class.getSimpleName() + "." + getClass().getSimpleName()
+ "[" + policy + ", threshold=" + threshold +
", number of nodes to be excluded = "+ nodesToBeExcluded.size() +
", number of nodes to be included = "+ nodesToBeIncluded.size() +"]";
}
}
static class Cli extends Configured implements Tool {
/**
* Parse arguments and then run Balancer.
*
* @param args command specific arguments.
* @return exit code. 0 indicates success, non-zero indicates failure.
*/
@Override
public int run(String[] args) {
final long startTime = Time.now();
final Configuration conf = getConf();
try {
checkReplicationPolicyCompatibility(conf);
final Collection<URI> namenodes = DFSUtil.getNsServiceRpcUris(conf);
return Balancer.run(namenodes, parse(args), conf);
} catch (IOException e) {
System.out.println(e + ". Exiting ...");
return ExitStatus.IO_EXCEPTION.getExitCode();
} catch (InterruptedException e) {
System.out.println(e + ". Exiting ...");
return ExitStatus.INTERRUPTED.getExitCode();
} finally {
System.out.format("%-24s ", DateFormat.getDateTimeInstance().format(new Date()));
System.out.println("Balancing took " + time2Str(Time.now()-startTime));
}
}
/** parse command line arguments */
static Parameters parse(String[] args) {
BalancingPolicy policy = Parameters.DEFAULT.policy;
double threshold = Parameters.DEFAULT.threshold;
Set<String> nodesTobeExcluded = Parameters.DEFAULT.nodesToBeExcluded;
Set<String> nodesTobeIncluded = Parameters.DEFAULT.nodesToBeIncluded;
if (args != null) {
try {
for(int i = 0; i < args.length; i++) {
if ("-threshold".equalsIgnoreCase(args[i])) {
checkArgument(++i < args.length,
"Threshold value is missing: args = " + Arrays.toString(args));
try {
threshold = Double.parseDouble(args[i]);
if (threshold < 1 || threshold > 100) {
throw new IllegalArgumentException(
"Number out of range: threshold = " + threshold);
}
LOG.info( "Using a threshold of " + threshold );
} catch(IllegalArgumentException e) {
System.err.println(
"Expecting a number in the range of [1.0, 100.0]: "
+ args[i]);
throw e;
}
} else if ("-policy".equalsIgnoreCase(args[i])) {
checkArgument(++i < args.length,
"Policy value is missing: args = " + Arrays.toString(args));
try {
policy = BalancingPolicy.parse(args[i]);
} catch(IllegalArgumentException e) {
System.err.println("Illegal policy name: " + args[i]);
throw e;
}
} else if ("-exclude".equalsIgnoreCase(args[i])) {
checkArgument(++i < args.length,
"List of nodes to exclude | -f <filename> is missing: args = "
+ Arrays.toString(args));
if ("-f".equalsIgnoreCase(args[i])) {
checkArgument(++i < args.length,
"File containing nodes to exclude is not specified: args = "
+ Arrays.toString(args));
nodesTobeExcluded = Util.getHostListFromFile(args[i], "exclude");
} else {
nodesTobeExcluded = Util.parseHostList(args[i]);
}
} else if ("-include".equalsIgnoreCase(args[i])) {
checkArgument(++i < args.length,
"List of nodes to include | -f <filename> is missing: args = "
+ Arrays.toString(args));
if ("-f".equalsIgnoreCase(args[i])) {
checkArgument(++i < args.length,
"File containing nodes to include is not specified: args = "
+ Arrays.toString(args));
nodesTobeIncluded = Util.getHostListFromFile(args[i], "include");
} else {
nodesTobeIncluded = Util.parseHostList(args[i]);
}
} else {
throw new IllegalArgumentException("args = "
+ Arrays.toString(args));
}
}
checkArgument(nodesTobeExcluded.isEmpty() || nodesTobeIncluded.isEmpty(),
"-exclude and -include options cannot be specified together.");
} catch(RuntimeException e) {
printUsage(System.err);
throw e;
}
}
return new Parameters(policy, threshold, nodesTobeExcluded, nodesTobeIncluded);
}
private static void printUsage(PrintStream out) {
out.println(USAGE + "
");
}
}
/**
* Run a balancer
* @param args Command line arguments
*/
public static void main(String[] args) {
if (DFSUtil.parseHelpArgument(args, USAGE, System.out, true)) {
System.exit(0);
}
try {
System.exit(ToolRunner.run(new HdfsConfiguration(), new Cli(), args));
} catch (Throwable e) {
LOG.error("Exiting balancer due an exception", e);
System.exit(-1);
}
}
}
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.hdfs.server.balancer;
import static org.apache.hadoop.hdfs.protocolPB.PBHelper.vintPrefixed;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.EnumMap;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.atomic.AtomicLong;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.CommonConfigurationKeys;
import org.apache.hadoop.hdfs.DFSUtil;
import org.apache.hadoop.hdfs.StorageType;
import org.apache.hadoop.hdfs.protocol.Block;
import org.apache.hadoop.hdfs.protocol.DatanodeInfo;
import org.apache.hadoop.hdfs.protocol.ExtendedBlock;
import org.apache.hadoop.hdfs.protocol.HdfsConstants;
import org.apache.hadoop.hdfs.protocol.datatransfer.IOStreamPair;
import org.apache.hadoop.hdfs.protocol.datatransfer.Sender;
import org.apache.hadoop.hdfs.protocol.datatransfer.TrustedChannelResolver;
import org.apache.hadoop.hdfs.protocol.datatransfer.sasl.DataTransferSaslUtil;
import org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient;
import org.apache.hadoop.hdfs.protocol.proto.DataTransferProtos.BlockOpResponseProto;
import org.apache.hadoop.hdfs.protocol.proto.DataTransferProtos.Status;
import org.apache.hadoop.hdfs.security.token.block.BlockTokenIdentifier;
import org.apache.hadoop.hdfs.server.balancer.Dispatcher.DDatanode.StorageGroup;
import org.apache.hadoop.hdfs.server.common.HdfsServerConstants;
import org.apache.hadoop.hdfs.server.protocol.BlocksWithLocations;
import org.apache.hadoop.hdfs.server.protocol.BlocksWithLocations.BlockWithLocations;
import org.apache.hadoop.hdfs.server.protocol.DatanodeStorageReport;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.net.NetUtils;
import org.apache.hadoop.net.NetworkTopology;
import org.apache.hadoop.security.token.Token;
import org.apache.hadoop.util.HostsFileReader;
import org.apache.hadoop.util.StringUtils;
import org.apache.hadoop.util.Time;
import com.google.common.base.Preconditions;
/** Dispatching block replica moves between datanodes. */
@InterfaceAudience.Private
public class Dispatcher {
static final Log LOG = LogFactory.getLog(Dispatcher.class);
private static final long GB = 1L << 30; // 1GB
private static final long MAX_BLOCKS_SIZE_TO_FETCH = 2 * GB;
private static final int MAX_NO_PENDING_MOVE_ITERATIONS = 5;
private static final long DELAY_AFTER_ERROR = 10 * 1000L; // 10 seconds
private final NameNodeConnector nnc;
private final SaslDataTransferClient saslClient;
/** Set of datanodes to be excluded. */
private final Set<String> excludedNodes;
/** Restrict to the following nodes. */
private final Set<String> includedNodes;
private final Collection<Source> sources = new HashSet<Source>();
private final Collection<StorageGroup> targets = new HashSet<StorageGroup>();
private final GlobalBlockMap globalBlocks = new GlobalBlockMap();
private final MovedBlocks<StorageGroup> movedBlocks;
/** Map (datanodeUuid,storageType -> StorageGroup) */
private final StorageGroupMap storageGroupMap = new StorageGroupMap();
private NetworkTopology cluster;
private final ExecutorService moveExecutor;
private final ExecutorService dispatchExecutor;
/** The maximum number of concurrent blocks moves at a datanode */
private final int maxConcurrentMovesPerNode;
private final AtomicLong bytesMoved = new AtomicLong();
private static class GlobalBlockMap {
private final Map<Block, DBlock> map = new HashMap<Block, DBlock>();
/**
* Get the block from the map;
* if the block is not found, create a new block and put it in the map.
*/
private DBlock get(Block b) {
DBlock block = map.get(b);
if (block == null) {
block = new DBlock(b);
map.put(b, block);
}
return block;
}
/** Remove all blocks except for the moved blocks. */
private void removeAllButRetain(MovedBlocks<StorageGroup> movedBlocks) {
for (Iterator<Block> i = map.keySet().iterator(); i.hasNext();) {
if (!movedBlocks.contains(i.next())) {
i.remove();
}
}
}
}
static class StorageGroupMap {
private static String toKey(String datanodeUuid, StorageType storageType) {
return datanodeUuid + ":" + storageType;
}
private final Map<String, StorageGroup> map = new HashMap<String, StorageGroup>();
StorageGroup get(String datanodeUuid, StorageType storageType) {
return map.get(toKey(datanodeUuid, storageType));
}
void put(StorageGroup g) {
final String key = toKey(g.getDatanodeInfo().getDatanodeUuid(), g.storageType);
final StorageGroup existing = map.put(key, g);
Preconditions.checkState(existing == null);
}
int size() {
return map.size();
}
void clear() {
map.clear();
}
}
/** This class keeps track of a scheduled block move */
private class PendingMove {
private DBlock block;
private Source source;
private DDatanode proxySource;
private StorageGroup target;
private PendingMove() {
}
@Override
public String toString() {
final Block b = block.getBlock();
return b + " with size=" + b.getNumBytes() + " from "
+ source.getDisplayName() + " to " + target.getDisplayName()
+ " through " + proxySource.datanode;
}
/**
* Choose a block & a proxy source for this pendingMove whose source &
* target have already been chosen.
*
* @return true if a block and its proxy are chosen; false otherwise
*/
private boolean chooseBlockAndProxy() {
// iterate all source's blocks until find a good one
for (Iterator<DBlock> i = source.getBlockIterator(); i.hasNext();) {
if (markMovedIfGoodBlock(i.next())) {
i.remove();
return true;
}
}
return false;
}
/**
* @return true if the given block is good for the tentative move.
*/
private boolean markMovedIfGoodBlock(DBlock block) {
synchronized (block) {
synchronized (movedBlocks) {
if (isGoodBlockCandidate(source, target, block)) {
this.block = block;
if (chooseProxySource()) {
movedBlocks.put(block);
if (LOG.isDebugEnabled()) {
LOG.debug("Decided to move " + this);
}
return true;
}
}
}
}
return false;
}
/**
* Choose a proxy source.
*
* @return true if a proxy is found; otherwise false
*/
private boolean chooseProxySource() {
final DatanodeInfo targetDN = target.getDatanodeInfo();
// if node group is supported, first try add nodes in the same node group
if (cluster.isNodeGroupAware()) {
for (StorageGroup loc : block.getLocations()) {
if (cluster.isOnSameNodeGroup(loc.getDatanodeInfo(), targetDN)
&& addTo(loc)) {
return true;
}
}
}
// check if there is replica which is on the same rack with the target
for (StorageGroup loc : block.getLocations()) {
if (cluster.isOnSameRack(loc.getDatanodeInfo(), targetDN) && addTo(loc)) {
return true;
}
}
// find out a non-busy replica
for (StorageGroup loc : block.getLocations()) {
if (addTo(loc)) {
return true;
}
}
return false;
}
/** add to a proxy source for specific block movement */
private boolean addTo(StorageGroup g) {
final DDatanode dn = g.getDDatanode();
if (dn.addPendingBlock(this)) {
proxySource = dn;
return true;
}
return false;
}
/** Dispatch the move to the proxy source & wait for the response. */
private void dispatch() {
if (LOG.isDebugEnabled()) {
LOG.debug("Start moving " + this);
}
Socket sock = new Socket();
DataOutputStream out = null;
DataInputStream in = null;
try {
sock.connect(
NetUtils.createSocketAddr(target.getDatanodeInfo().getXferAddr()),
HdfsServerConstants.READ_TIMEOUT);
sock.setKeepAlive(true);
OutputStream unbufOut = sock.getOutputStream();
InputStream unbufIn = sock.getInputStream();
ExtendedBlock eb = new ExtendedBlock(nnc.getBlockpoolID(),
block.getBlock());
final KeyManager km = nnc.getKeyManager();
Token<BlockTokenIdentifier> accessToken = km.getAccessToken(eb);
IOStreamPair saslStreams = saslClient.socketSend(sock, unbufOut,
unbufIn, km, accessToken, target.getDatanodeInfo());
unbufOut = saslStreams.out;
unbufIn = saslStreams.in;
out = new DataOutputStream(new BufferedOutputStream(unbufOut,
HdfsConstants.IO_FILE_BUFFER_SIZE));
in = new DataInputStream(new BufferedInputStream(unbufIn,
HdfsConstants.IO_FILE_BUFFER_SIZE));
sendRequest(out, eb, accessToken);
receiveResponse(in);
bytesMoved.addAndGet(block.getNumBytes());
LOG.info("Successfully moved " + this);
} catch (IOException e) {
LOG.warn("Failed to move " + this + ": " + e.getMessage());
// Proxy or target may have some issues, delay before using these nodes
// further in order to avoid a potential storm of "threads quota
// exceeded" warnings when the dispatcher gets out of sync with work
// going on in datanodes.
proxySource.activateDelay(DELAY_AFTER_ERROR);
target.getDDatanode().activateDelay(DELAY_AFTER_ERROR);
} finally {
IOUtils.closeStream(out);
IOUtils.closeStream(in);
IOUtils.closeSocket(sock);
proxySource.removePendingBlock(this);
target.getDDatanode().removePendingBlock(this);
synchronized (this) {
reset();
}
synchronized (Dispatcher.this) {
Dispatcher.this.notifyAll();
}
}
}
/** Send a block replace request to the output stream */
private void sendRequest(DataOutputStream out, ExtendedBlock eb,
Token<BlockTokenIdentifier> accessToken) throws IOException {
new Sender(out).replaceBlock(eb, target.storageType, accessToken,
source.getDatanodeInfo().getDatanodeUuid(), proxySource.datanode);
}
/** Receive a block copy response from the input stream */
private void receiveResponse(DataInputStream in) throws IOException {
BlockOpResponseProto response =
BlockOpResponseProto.parseFrom(vintPrefixed(in));
while (response.getStatus() == Status.IN_PROGRESS) {
// read intermediate responses
response = BlockOpResponseProto.parseFrom(vintPrefixed(in));
}
if (response.getStatus() != Status.SUCCESS) {
if (response.getStatus() == Status.ERROR_ACCESS_TOKEN) {
throw new IOException("block move failed due to access token error");
}
throw new IOException("block move is failed: " + response.getMessage());
}
}
/** reset the object */
private void reset() {
block = null;
source = null;
proxySource = null;
target = null;
}
}
/** A class for keeping track of block locations in the dispatcher. */
private static class DBlock extends MovedBlocks.Locations<StorageGroup> {
DBlock(Block block) {
super(block);
}
}
/** The class represents a desired move. */
static class Task {
private final StorageGroup target;
private long size; // bytes scheduled to move
Task(StorageGroup target, long size) {
this.target = target;
this.size = size;
}
long getSize() {
return size;
}
}
/** A class that keeps track of a datanode. */
static class DDatanode {
/** A group of storages in a datanode with the same storage type. */
class StorageGroup {
final StorageType storageType;
final long maxSize2Move;
private long scheduledSize = 0L;
private StorageGroup(StorageType storageType, long maxSize2Move) {
this.storageType = storageType;
this.maxSize2Move = maxSize2Move;
}
private DDatanode getDDatanode() {
return DDatanode.this;
}
DatanodeInfo getDatanodeInfo() {
return DDatanode.this.datanode;
}
/** Decide if still need to move more bytes */
synchronized boolean hasSpaceForScheduling() {
return availableSizeToMove() > 0L;
}
/** @return the total number of bytes that need to be moved */
synchronized long availableSizeToMove() {
return maxSize2Move - scheduledSize;
}
/** increment scheduled size */
synchronized void incScheduledSize(long size) {
scheduledSize += size;
}
/** @return scheduled size */
synchronized long getScheduledSize() {
return scheduledSize;
}
/** Reset scheduled size to zero. */
synchronized void resetScheduledSize() {
scheduledSize = 0L;
}
/** @return the name for display */
String getDisplayName() {
return datanode + ":" + storageType;
}
@Override
public String toString() {
return getDisplayName();
}
}
final DatanodeInfo datanode;
final EnumMap<StorageType, StorageGroup> storageMap
= new EnumMap<StorageType, StorageGroup>(StorageType.class);
protected long delayUntil = 0L;
/** blocks being moved but not confirmed yet */
private final List<PendingMove> pendings;
private final int maxConcurrentMoves;
@Override
public String toString() {
return getClass().getSimpleName() + ":" + datanode + ":" + storageMap.values();
}
private DDatanode(DatanodeStorageReport r, int maxConcurrentMoves) {
this.datanode = r.getDatanodeInfo();
this.maxConcurrentMoves = maxConcurrentMoves;
this.pendings = new ArrayList<PendingMove>(maxConcurrentMoves);
}
private void put(StorageType storageType, StorageGroup g) {
final StorageGroup existing = storageMap.put(storageType, g);
Preconditions.checkState(existing == null);
}
StorageGroup addStorageGroup(StorageType storageType, long maxSize2Move) {
final StorageGroup g = new StorageGroup(storageType, maxSize2Move);
put(storageType, g);
return g;
}
Source addSource(StorageType storageType, long maxSize2Move, Dispatcher d) {
final Source s = d.new Source(storageType, maxSize2Move, this);
put(storageType, s);
return s;
}
synchronized private void activateDelay(long delta) {
delayUntil = Time.monotonicNow() + delta;
}
synchronized private boolean isDelayActive() {
if (delayUntil == 0 || Time.monotonicNow() > delayUntil) {
delayUntil = 0;
return false;
}
return true;
}
/** Check if the node can schedule more blocks to move */
synchronized boolean isPendingQNotFull() {
return pendings.size() < maxConcurrentMoves;
}
/** Check if all the dispatched moves are done */
synchronized boolean isPendingQEmpty() {
return pendings.isEmpty();
}
/** Add a scheduled block move to the node */
synchronized boolean addPendingBlock(PendingMove pendingBlock) {
if (!isDelayActive() && isPendingQNotFull()) {
return pendings.add(pendingBlock);
}
return false;
}
/** Remove a scheduled block move from the node */
synchronized boolean removePendingBlock(PendingMove pendingBlock) {
return pendings.remove(pendingBlock);
}
}
/** A node that can be the sources of a block move */
class Source extends DDatanode.StorageGroup {
private final List<Task> tasks = new ArrayList<Task>(2);
private long blocksToReceive = 0L;
/**
* Source blocks point to the objects in {@link Dispatcher#globalBlocks}
* because we want to keep one copy of a block and be aware that the
* locations are changing over time.
*/
private final List<DBlock> srcBlocks = new ArrayList<DBlock>();
private Source(StorageType storageType, long maxSize2Move, DDatanode dn) {
dn.super(storageType, maxSize2Move);
}
/** Add a task */
void addTask(Task task) {
Preconditions.checkState(task.target != this,
"Source and target are the same storage group " + getDisplayName());
incScheduledSize(task.size);
tasks.add(task);
}
/** @return an iterator to this source's blocks */
Iterator<DBlock> getBlockIterator() {
return srcBlocks.iterator();
}
/**
* Fetch new blocks of this source from namenode and update this source's
* block list & {@link Dispatcher#globalBlocks}.
*
* @return the total size of the received blocks in the number of bytes.
*/
private long getBlockList() throws IOException {
final long size = Math.min(MAX_BLOCKS_SIZE_TO_FETCH, blocksToReceive);
final BlocksWithLocations newBlocks = nnc.getBlocks(getDatanodeInfo(), size);
long bytesReceived = 0;
for (BlockWithLocations blk : newBlocks.getBlocks()) {
bytesReceived += blk.getBlock().getNumBytes();
synchronized (globalBlocks) {
final DBlock block = globalBlocks.get(blk.getBlock());
synchronized (block) {
block.clearLocations();
// update locations
final String[] datanodeUuids = blk.getDatanodeUuids();
final StorageType[] storageTypes = blk.getStorageTypes();
for (int i = 0; i < datanodeUuids.length; i++) {
final StorageGroup g = storageGroupMap.get(
datanodeUuids[i], storageTypes[i]);
if (g != null) { // not unknown
block.addLocation(g);
}
}
}
if (!srcBlocks.contains(block) && isGoodBlockCandidate(block)) {
// filter bad candidates
srcBlocks.add(block);
}
}
}
return bytesReceived;
}
/** Decide if the given block is a good candidate to move or not */
private boolean isGoodBlockCandidate(DBlock block) {
for (Task t : tasks) {
if (Dispatcher.this.isGoodBlockCandidate(this, t.target, block)) {
return true;
}
}
return false;
}
/**
* Choose a move for the source. The block's source, target, and proxy
* are determined too. When choosing proxy and target, source &
* target throttling has been considered. They are chosen only when they
* have the capacity to support this block move. The block should be
* dispatched immediately after this method is returned.
*
* @return a move that's good for the source to dispatch immediately.
*/
private PendingMove chooseNextMove() {
for (Iterator<Task> i = tasks.iterator(); i.hasNext();) {
final Task task = i.next();
final DDatanode target = task.target.getDDatanode();
PendingMove pendingBlock = new PendingMove();
if (target.addPendingBlock(pendingBlock)) {
// target is not busy, so do a tentative block allocation
pendingBlock.source = this;
pendingBlock.target = task.target;
if (pendingBlock.chooseBlockAndProxy()) {
long blockSize = pendingBlock.block.getNumBytes();
incScheduledSize(-blockSize);
task.size -= blockSize;
if (task.size == 0) {
i.remove();
}
return pendingBlock;
} else {
// cancel the tentative move
target.removePendingBlock(pendingBlock);
}
}
}
return null;
}
/** Iterate all source's blocks to remove moved ones */
private void removeMovedBlocks() {
for (Iterator<DBlock> i = getBlockIterator(); i.hasNext();) {
if (movedBlocks.contains(i.next().getBlock())) {
i.remove();
}
}
}
private static final int SOURCE_BLOCKS_MIN_SIZE = 5;
/** @return if should fetch more blocks from namenode */
private boolean shouldFetchMoreBlocks() {
return srcBlocks.size() < SOURCE_BLOCKS_MIN_SIZE && blocksToReceive > 0;
}
private static final long MAX_ITERATION_TIME = 20 * 60 * 1000L; // 20 mins
/**
* This method iteratively does the following: it first selects a block to
* move, then sends a request to the proxy source to start the block move
* when the source's block list falls below a threshold, it asks the
* namenode for more blocks. It terminates when it has dispatch enough block
* move tasks or it has received enough blocks from the namenode, or the
* elapsed time of the iteration has exceeded the max time limit.
*/
private void dispatchBlocks() {
final long startTime = Time.monotonicNow();
this.blocksToReceive = 2 * getScheduledSize();
boolean isTimeUp = false;
int noPendingMoveIteration = 0;
while (!isTimeUp && getScheduledSize() > 0
&& (!srcBlocks.isEmpty() || blocksToReceive > 0)) {
final PendingMove p = chooseNextMove();
if (p != null) {
// move the block
moveExecutor.execute(new Runnable() {
@Override
public void run() {
p.dispatch();
}
});
continue;
}
// Since we cannot schedule any block to move,
// remove any moved blocks from the source block list and
removeMovedBlocks(); // filter already moved blocks
// check if we should fetch more blocks from the namenode
if (shouldFetchMoreBlocks()) {
// fetch new blocks
try {
blocksToReceive -= getBlockList();
continue;
} catch (IOException e) {
LOG.warn("Exception while getting block list", e);
return;
}
} else {
// source node cannot find a pending block to move, iteration +1
noPendingMoveIteration++;
// in case no blocks can be moved for source node's task,
// jump out of while-loop after 5 iterations.
if (noPendingMoveIteration >= MAX_NO_PENDING_MOVE_ITERATIONS) {
resetScheduledSize();
}
}
// check if time is up or not
if (Time.monotonicNow() - startTime > MAX_ITERATION_TIME) {
isTimeUp = true;
continue;
}
// Now we can not schedule any block to move and there are
// no new blocks added to the source block list, so we wait.
try {
synchronized (Dispatcher.this) {
Dispatcher.this.wait(1000); // wait for targets/sources to be idle
}
} catch (InterruptedException ignored) {
}
}
}
}
public Dispatcher(NameNodeConnector nnc, Set<String> includedNodes,
Set<String> excludedNodes, long movedWinWidth, int moverThreads,
int dispatcherThreads, int maxConcurrentMovesPerNode, Configuration conf) {
this.nnc = nnc;
this.excludedNodes = excludedNodes;
this.includedNodes = includedNodes;
this.movedBlocks = new MovedBlocks<StorageGroup>(movedWinWidth);
this.cluster = NetworkTopology.getInstance(conf);
this.moveExecutor = Executors.newFixedThreadPool(moverThreads);
this.dispatchExecutor = Executors.newFixedThreadPool(dispatcherThreads);
this.maxConcurrentMovesPerNode = maxConcurrentMovesPerNode;
final boolean fallbackToSimpleAuthAllowed = conf.getBoolean(
CommonConfigurationKeys.IPC_CLIENT_FALLBACK_TO_SIMPLE_AUTH_ALLOWED_KEY,
CommonConfigurationKeys.IPC_CLIENT_FALLBACK_TO_SIMPLE_AUTH_ALLOWED_DEFAULT);
this.saslClient = new SaslDataTransferClient(
DataTransferSaslUtil.getSaslPropertiesResolver(conf),
TrustedChannelResolver.getInstance(conf), fallbackToSimpleAuthAllowed);
}
StorageGroupMap getStorageGroupMap() {
return storageGroupMap;
}
NetworkTopology getCluster() {
return cluster;
}
long getBytesMoved() {
return bytesMoved.get();
}
long bytesToMove() {
Preconditions.checkState(
storageGroupMap.size() >= sources.size() + targets.size(),
"Mismatched number of storage groups (" + storageGroupMap.size()
+ " < " + sources.size() + " sources + " + targets.size()
+ " targets)");
long b = 0L;
for (Source src : sources) {
b += src.getScheduledSize();
}
return b;
}
void add(Source source, StorageGroup target) {
sources.add(source);
targets.add(target);
}
private boolean shouldIgnore(DatanodeInfo dn) {
// ignore decommissioned nodes
final boolean decommissioned = dn.isDecommissioned();
// ignore decommissioning nodes
final boolean decommissioning = dn.isDecommissionInProgress();
// ignore nodes in exclude list
final boolean excluded = Util.isExcluded(excludedNodes, dn);
// ignore nodes not in the include list (if include list is not empty)
final boolean notIncluded = !Util.isIncluded(includedNodes, dn);
if (decommissioned || decommissioning || excluded || notIncluded) {
if (LOG.isTraceEnabled()) {
LOG.trace("Excluding datanode " + dn + ": " + decommissioned + ", "
+ decommissioning + ", " + excluded + ", " + notIncluded);
}
return true;
}
return false;
}
/** Get live datanode storage reports and then build the network topology. */
List<DatanodeStorageReport> init() throws IOException {
final DatanodeStorageReport[] reports = nnc.getLiveDatanodeStorageReport();
final List<DatanodeStorageReport> trimmed = new ArrayList<DatanodeStorageReport>();
// create network topology and classify utilization collections:
// over-utilized, above-average, below-average and under-utilized.
for (DatanodeStorageReport r : DFSUtil.shuffle(reports)) {
final DatanodeInfo datanode = r.getDatanodeInfo();
if (shouldIgnore(datanode)) {
continue;
}
trimmed.add(r);
cluster.add(datanode);
}
return trimmed;
}
public DDatanode newDatanode(DatanodeStorageReport r) {
return new DDatanode(r, maxConcurrentMovesPerNode);
}
public boolean dispatchAndCheckContinue() throws InterruptedException {
return nnc.shouldContinue(dispatchBlockMoves());
}
/**
* Dispatch block moves for each source. The thread selects blocks to move &
* sends request to proxy source to initiate block move. The process is flow
* controlled. Block selection is blocked if there are too many un-confirmed
* block moves.
*
* @return the total number of bytes successfully moved in this iteration.
*/
private long dispatchBlockMoves() throws InterruptedException {
final long bytesLastMoved = bytesMoved.get();
final Future<?>[] futures = new Future<?>[sources.size()];
final Iterator<Source> i = sources.iterator();
for (int j = 0; j < futures.length; j++) {
final Source s = i.next();
futures[j] = dispatchExecutor.submit(new Runnable() {
@Override
public void run() {
s.dispatchBlocks();
}
});
}
// wait for all dispatcher threads to finish
for (Future<?> future : futures) {
try {
future.get();
} catch (ExecutionException e) {
LOG.warn("Dispatcher thread failed", e.getCause());
}
}
// wait for all block moving to be done
waitForMoveCompletion();
return bytesMoved.get() - bytesLastMoved;
}
/** The sleeping period before checking if block move is completed again */
static private long blockMoveWaitTime = 30000L;
/** set the sleeping period for block move completion check */
static void setBlockMoveWaitTime(long time) {
blockMoveWaitTime = time;
}
/** Wait for all block move confirmations. */
private void waitForMoveCompletion() {
for(;;) {
boolean empty = true;
for (StorageGroup t : targets) {
if (!t.getDDatanode().isPendingQEmpty()) {
empty = false;
break;
}
}
if (empty) {
return; //all pending queues are empty
}
try {
Thread.sleep(blockMoveWaitTime);
} catch (InterruptedException ignored) {
}
}
}
/**
* Decide if the block is a good candidate to be moved from source to target.
* A block is a good candidate if
* 1. the block is not in the process of being moved/has not been moved;
* 移动的块不是正在被移动的块
* 2. the block does not have a replica on the target;
* 在目标节点上没有移动的block块
* 3. doing the move does not reduce the number of racks that the block has
* 移动之后,不同机架上的block块的数量应该是不变的.
*/
private boolean isGoodBlockCandidate(Source source, StorageGroup target,
DBlock block) {
if (source.storageType != target.storageType) {
return false;
}
// check if the block is moved or not
//如果所要移动的块是存在于正在被移动的块列表,则返回false
if (movedBlocks.contains(block.getBlock())) {
return false;
}
//如果移动的块已经存在于目标节点上,则返回false,将不会予以移动
if (block.isLocatedOn(target)) {
return false;
}
//如果开启了机架感知的配置,则目标节点不应该有相同的block
if (cluster.isNodeGroupAware()
&& isOnSameNodeGroupWithReplicas(target, block, source)) {
return false;
}
//需要维持机架上的block块数量不变
if (reduceNumOfRacks(source, target, block)) {
return false;
}
return true;
}
/**
* Determine whether moving the given block replica from source to target
* would reduce the number of racks of the block replicas.
*/
private boolean reduceNumOfRacks(Source source, StorageGroup target,
DBlock block) {
final DatanodeInfo sourceDn = source.getDatanodeInfo();
if (cluster.isOnSameRack(sourceDn, target.getDatanodeInfo())) {
// source and target are on the same rack
return false;
}
boolean notOnSameRack = true;
synchronized (block) {
for (StorageGroup loc : block.getLocations()) {
if (cluster.isOnSameRack(loc.getDatanodeInfo(), target.getDatanodeInfo())) {
notOnSameRack = false;
break;
}
}
}
if (notOnSameRack) {
// target is not on the same rack as any replica
return false;
}
for (StorageGroup g : block.getLocations()) {
if (g != source && cluster.isOnSameRack(g.getDatanodeInfo(), sourceDn)) {
// source is on the same rack of another replica
return false;
}
}
return true;
}
/**
* Check if there are any replica (other than source) on the same node group
* with target. If true, then target is not a good candidate for placing
* specific replica as we don't want 2 replicas under the same nodegroup.
*
* @return true if there are any replica (other than source) on the same node
* group with target
*/
private boolean isOnSameNodeGroupWithReplicas(
StorageGroup target, DBlock block, Source source) {
final DatanodeInfo targetDn = target.getDatanodeInfo();
for (StorageGroup g : block.getLocations()) {
if (g != source && cluster.isOnSameNodeGroup(g.getDatanodeInfo(), targetDn)) {
return true;
}
}
return false;
}
/** Reset all fields in order to prepare for the next iteration */
void reset(Configuration conf) {
cluster = NetworkTopology.getInstance(conf);
storageGroupMap.clear();
sources.clear();
targets.clear();
globalBlocks.removeAllButRetain(movedBlocks);
movedBlocks.cleanup();
}
/** shutdown thread pools */
void shutdownNow() {
dispatchExecutor.shutdownNow();
moveExecutor.shutdownNow();
}
static class Util {
/** @return true if data node is part of the excludedNodes. */
static boolean isExcluded(Set<String> excludedNodes, DatanodeInfo dn) {
return isIn(excludedNodes, dn);
}
/**
* @return true if includedNodes is empty or data node is part of the
* includedNodes.
*/
static boolean isIncluded(Set<String> includedNodes, DatanodeInfo dn) {
return (includedNodes.isEmpty() || isIn(includedNodes, dn));
}
/**
* Match is checked using host name , ip address with and without port
* number.
*
* @return true if the datanode's transfer address matches the set of nodes.
*/
private static boolean isIn(Set<String> datanodes, DatanodeInfo dn) {
return isIn(datanodes, dn.getPeerHostName(), dn.getXferPort())
|| isIn(datanodes, dn.getIpAddr(), dn.getXferPort())
|| isIn(datanodes, dn.getHostName(), dn.getXferPort());
}
/** @return true if nodes contains host or host:port */
private static boolean isIn(Set<String> nodes, String host, int port) {
if (host == null) {
return false;
}
return (nodes.contains(host) || nodes.contains(host + ":" + port));
}
/**
* Parse a comma separated string to obtain set of host names
*
* @return set of host names
*/
static Set<String> parseHostList(String string) {
String[] addrs = StringUtils.getTrimmedStrings(string);
return new HashSet<String>(Arrays.asList(addrs));
}
/**
* Read set of host names from a file
*
* @return set of host names
*/
static Set<String> getHostListFromFile(String fileName, String type) {
Set<String> nodes = new HashSet<String>();
try {
HostsFileReader.readFileToSet(type, fileName, nodes);
return StringUtils.getTrimmedStrings(nodes);
} catch (IOException e) {
throw new IllegalArgumentException(
"Failed to read host list from file: " + fileName);
}
}
}
}