在实际分析中,经常遇到连续值需要离散化,或者离散值需要哑元化的问题,下面将分别举例说明。
1、连续指标离散化
可以根据自己的需求划分不同的区间,然后使用pandas中cut()、qcut()函数来完成连续变量离散化操作。
1 #导入模块 2 import pandas as pd 3 4 # 将范围划分为(0, 18]、(18, 25]、(25, 35]、(35, 60]、(60, 100] 5 ages = [10, 21, 24, 25, 32, 23, 22, 42, 35, 66, 21] 6 bins = [0, 18, 25, 35, 60, 100] 7 cats = pd.cut(ages, bins, right=True) #right=False表示区间是左闭右开的 8 cats 9 [(0, 18], (18, 25], (18, 25], (18, 25], (25, 35], ..., (18, 25], 10 (35, 60], (25, 35], (60, 100], (18, 25]] 11 Length: 11 12 Categories (5, interval[int64]): [(0, 18] < (18, 25] < (25, 35] < (35, 60] < (60, 100]] 13 #查看ages中不同值对应的标签 14 cats.codes 15 array([0, 1, 1, 1, 2, 1, 1, 3, 2, 4, 1], dtype=int8) 16 #对不同区间的数进行统计 17 cats.value_counts() 18 (0, 18] 1 19 (18, 25] 6 20 (25, 35] 2 21 (35, 60] 1 22 (60, 100] 1 23 dtype: int64
1 import numpy as np 2 3 data = np.random.rand(20) 4 #cut传入的是区间数量时候,他会根据数据的最小值和最大值计算等长面元 5 pd.cut(data, 4, precision=2) 6 [(0.53, 0.76], (0.76, 0.99], (0.068, 0.3], (0.3, 0.53], (0.53, 0.76], ..., (0.76,0.99], (0.76, 0.99], (0.068, 0.3], (0.53, 0.76], (0.068, 0.3]] 7 Length: 20 8 Categories (4, interval[float64]): [(0.068, 0.3] < (0.3, 0.53] < (0.53, 0.76] <(0.76, 0.99]] 9 10 #qcut()是pandas中的一个类似于cut的函数,根据样本分位数对数据进行面元划分 11 data = np.random.rand(1000) 12 cats = pd.qcut(data, 4) #按四分位数切割 13 cats.value_count() 14 (-0.000589, 0.257] 250 15 (0.257, 0.516] 250 16 (0.516, 0.761] 250 17 (0.761, 0.994] 250 18 dtype: int64 19 20 #自定义分位数 21 cats = pd.qcut(data, [0, 0.1, 0.5, 0.9, 1.]) 22 cats.value_counts() 23 (-0.000589, 0.115] 100 24 (0.115, 0.516] 400 25 (0.516, 0.908] 400 26 (0.908, 0.994] 100 27 dtype: int64
2、离散指标哑元化
分类变量哑元化是指将分类变量转换成“哑变量矩阵”(dummy matrix),如果DataFrame中的某一列中含有k个不同的值,则可以派生出一个k列矩阵,pandas中的get_dummies()函数可以实现该功能。
1 df = pd.DataFrame({'key':['b', 'b', 'a', 'c', 'a', 'b'], 2 'data1':range(6)}) 3 dummies = pd.get_dummies(df['key'], prefix='key')
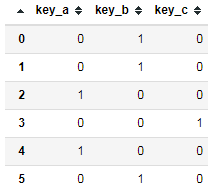
5 #合并 6 df[['data1']].join(dummies)
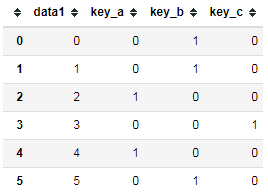
如果遇到DataFrame中某行同属于多个类,处理如下。
1 df = pd.DataFrame({'id':range(6), 2 'key':['b|a|c', 'a|b|d', 'e|f', 'c', 'a', 'b'], 3 }) 4 df
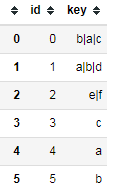
5 keys_iter = (set(x.split('|')) for x in df.key) 6 keys = sorted(set.union(*keys_iter)) 7 keys #['a', 'b', 'c', 'd', 'e', 'f']
8 dummies = pd.DataFrame(np.zeros((len(df), len(keys))), columns=keys) 9 dummies
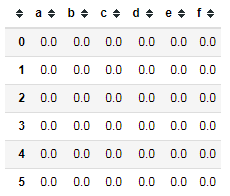
10 for i, key in enumerate(df.key): #enumerate(df.key) 返回迭代对象的(索引,值)
11 dummies.loc[i, key.split('|')] = 1
12 dummies
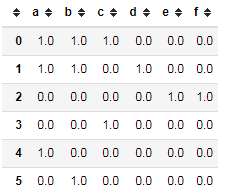
13 df.join(dummies.add_prefix("key_"))
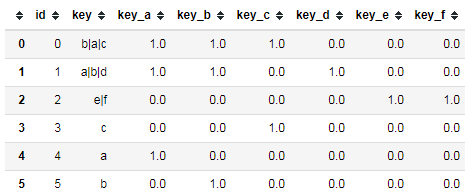
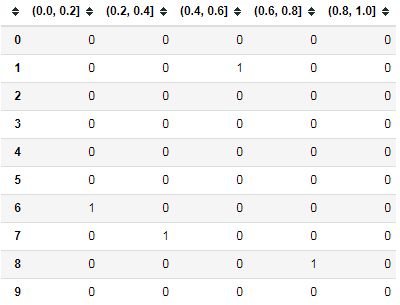
3、二者结合使用
1 np.random.seed(12345) 2 values = np.random.randn(10) 3 bins = [0, 0.2, 0.4, 0.6, 0.8, 1] 4 5 pd.get_dummies(pd.cut(values, bins))