2017-2018-1 20155228 《信息安全系统设计基础》第九周学习总结
教材学习内容总结
常见的存储技术
RAM
随机访问存储器(Random-Access Memory, RAM)分为两类:静态的和动态的。静态
RAM(SRAM)比动态RAM(DRAM)更快,但也贵得多。SRAM用来作为高速缓存存储
器,既可以在CPU芯片上,也可以在片下。DRAM用来作为主存以及图形系统的帧缓冲
区。典型地,一个桌面系统的SRAM不会超过几兆字节,但是DRAM却有几百或几千兆
字节。
-
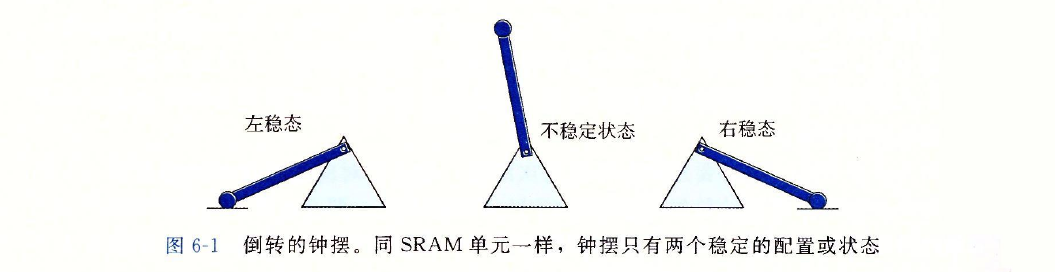
SRAM将每个位存储在一个双稳态的(bistable)存储器单元里。每个单元是用一个六
晶体管电路来实现的。这个电路有这样一个属性,它可以无限期地保持在两个不同的电压
配置(configuration)或状态(state)之一。其他任何状态都是不稳定的—从不稳定状态开
始,电路会迅速地转移到两个稳定状态中的一个。这样一个存储器单元类似于图6-1中画
出的倒转的钟摆。 -
DRAM将每个位存储为对一个电容的充电。这个电容非常小,通常只有大约30毫微
微法拉(femtofarad)— 30 X 10-'S法拉。不过,回想一下法拉是一个非常大的计量单位。
DRAM存储器可以制造得非常密集—每个单元由一个电容和一个访问晶体管组成。但
是,与SRAM不同,DRAM存储器单元对干扰非常敏感。当电容的电压被扰乱之后,它
就永远不会恢复了。暴露在光线下会导致电容电压改变。实际上,数码照相机和摄像机中
的传感器本质上就是DRAM单元的阵列。 -
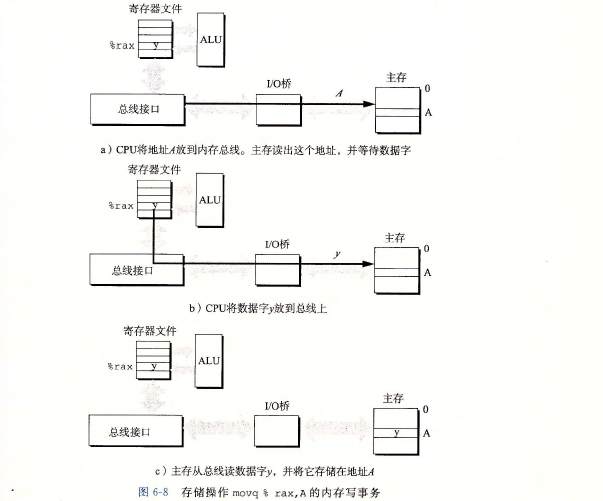
DRAM芯片中的单元(位)被分成d个超单元(supercell),每个超单元都由w个DRAM
单元组成。一个dXw的DRAM总共存储了dw位信息。超单元被组织成一个:行。列的长
方形阵列,这里:c=d。每个超单元有形如((i, j)的地址,这里i表示行,而J表示列。 -
DRAM芯片封装在内存模块(memory module)中,它插到主板的扩展槽上。
系统使用的240个引脚的双列直插内存模块(Dual Inline Memory Module, DIMM)
Core i7
,它以64位为块传送数据到内存控制器和从内存控制器传出数据。 -
有许多种DRAM存储器,而生产厂商试图跟上迅速增长的处理器速度,市场上就会
定期推出新的种类。每种都是基于传统的DRAM单元,并进行一些优化,
提高访问基本DRAM单元的速度。
磁盘存储
磁盘是广为应用的保存大量数据的存储设备,存储数据的数量级可以达到几百到几千
千兆字节,而基于RAM的存储器只能有几百或几千兆字节。不过,从磁盘上读信息的时
间为毫秒级,比从DRAM读慢了10万倍,比从SRAM读慢了100万倍。
磁盘是由盘片(platter)构成的。每个盘片有两面或者称为表面(surface),表面覆盖着
磁性记录材料。盘片中央有一个可以旋转的主轴(spindle),它使得盘片以固定的旋转速率
(rotational rate)旋转,通常是5400^-15 000转每分钟(Revolution Per Minute, RPM)。磁
盘通常包含一个或多个这样的盘片,并封装在一个密封的容器内。
固态硬盘
固态硬盘(Solid State Disk, SSD)是一种基于闪存的存储技术,在某
些情况下是传统旋转磁盘的极有吸引力的替代产品。展示了它的基本思想。SSD
封装插到I/O总线上标准硬盘插槽(通常是USB或SATA)中,行为就和其他硬盘一样,
处理来自CPU的读写逻辑磁盘块的请求。一个SSD封装由一个或多个闪存芯片和闪存翻
译层((flash translation layer)组成,闪存芯片替代传统旋转磁盘中的机械驱动器,而闪存
翻译层是一个硬件/固件设备,扮演与磁盘控制器相同的角色,将对逻辑块的请求翻译成
对底层物理设备的访问。
局部性原理
-
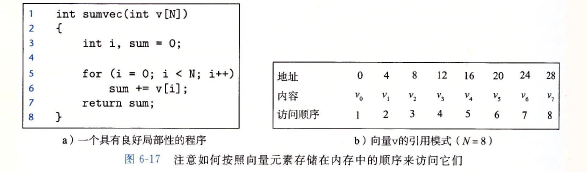
一个编写良好的计算机程序常常具有良好的局部性(locality)。也就是,它们倾向于引
用邻近于其他最近引用过的数据项的数据项,或者最近引用过的数据项本身。这种倾向
性,被称为局部性原理(principle of locality),是一个持久的概念,对硬件和软件系统的设
计和性能都有着极大的影响。 -
局部性通常有两种不同的形式:时间局邵性(temporal locality)和空间局部性(spatial
locality)。在一个具有良好时间局部性的程序中,被引用过一次的内存位置很可能在不远
的将来再被多次引用。在一个具有良好空间局部性的程序中,如果一个内存位置被引用了
一次,那么程序很可能在不远的将来引用附近的一个内存位置。 -
程序员应该理解局部性原理,因为一般而言,有良好局部性的程序比局部性差的程序
运行得更快。现代计算机系统的各个层次,从硬件到操作系统、再到应用程序,它们的设
计都利用了局部性。在硬件层,局部性原理允许计算机设计者通过引人称为高速缓存存储
器的小而快速的存储器来保存最近被引用的指令和数据项,从而提高对主存的访问速度。
在操作系统级,局部性原理允许系统使用主存作为虚拟地址空间最近被引用块的高速缓
存。类似地,操作系统用主存来缓存磁盘文件系统中最近被使用的磁盘块。局部性原理在
应用程序的设计中也扮演着重要的角色。例如,Web浏览器将最近被引用的文档放在本地
磁盘上,利用的就是时间局部性。大容量的Web服务器将最近被请求的文档放在前端磁
盘高速缓存中,这些缓存能满足对这些文档的请求,而不需要服务器的任何干预。
-
量化评价程序中局部性的一些
简单原则:
- 重复引用相同变量的程序有良好的时间局部性。
- 对于具有步长为k的引用模式的程序,步长越小,空间局部性越好。具有步长为l
的引用模式的程序有很好的空间局部性。在内存中以大步长跳来跳去的程序空间局
部性会很差。 - 对于取指令来说,循环有好的时间和空间局部性。循环体越小,循环迭代次数越
多,局部性越好。
缓存思想
-
一般而言.高速缓存(cache,读作“cash")是一个小而快速的存储设备,它作为存储
在更大、也更慢的设备中的数据对象的缓冲区域。使用高速缓存的过程称为缓存(caching,
读作“cashing")o -
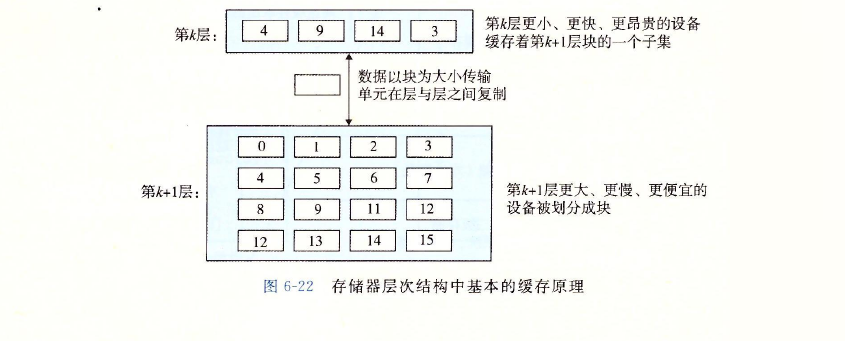
存储器层次结构的中心思想是,对于每个k,位于k层的更快更小的存储设备作为位于
k十1层的更大更慢的存储设备的缓存。换句话说,层次结构中的每一层都缓存来自较低一层
的数据对象。例如,本地磁盘作为通过网络从远程磁盘取出的文件(例如Web页面)的缓存,
主存作为本地磁盘上数据的缓存,依此类推,直到最小的缓存—CPU寄存器组。 -
图展示了存储器层次结构中缓存的一般性概念。第k -} 1层的存储器被划分成连
续的数据对象组块(chunk),称为块(block)。每个块都有一个唯一的地址或名字,使之区
别于其他的块。块可以是固定大小的(通常是这样的),也可以是可变大小的(例如存储在
Web服务器上的远程HTML文件)。例如,图中第k+1层存储器被划分成16个大
小固定的块,编号为0-15.
-
概括来说,基于缓存的存储器层次结构行之有效,是因为较慢的存储设备比较快的存
储设备更便宜,还因为程序倾向于展示局部性:
- 利用时间局部性:由于时间局部性,同一数据对象可能会被多次使用。一旦一个数
据对象在第一次不命中时被复制到缓存中,我们就会期望后面对该目标有一系列的
访问命中。因为缓存比低一层的存储设备更快,对后面的命中的服务会比最开始的
不命中快很多。 - 利用空间局部性:块通常包含有多个数据对象。由于空间局部性,我们会期望后面对该块中其他对象的访问能够补偿不命中后复制该块的花费。
高速缓存的原理和应用
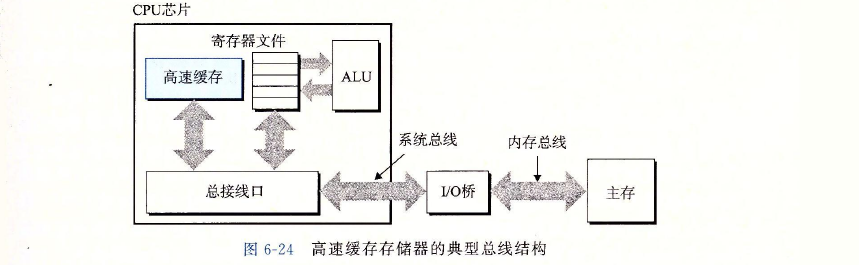
- 早期计算机系统的存储器层次结构只有三层:CPU寄存器、DRAM主存储器和磁盘
存储。不过,由于CPU和主存之间逐渐增大的差距,系统设计者被迫在CPU寄存器文件
和主存之间插人了一个小的SRAM高速缓存存储器,称为I_ 1高速缓存(一级缓存),如
图所示。Ll高速缓存的访问速度几乎和寄存器一样快,典型地是大约4个时钟周期。 - 随着CPU和主存之间的性能差距不断增大,系统设计者在L1高速缓存和主存之间又
插人了一个更大的高速缓存,称为L2高速缓存,可以在大约10个时钟周期内访问到它。
有些现代系统还包括有一个更大的高速缓存,称为L3高速缓存,在存储器层次结构中,
它位于L2高速缓存和主存之间,可以在大约50个周期内访问到它。虽然安排上有相当多
的变化,但是通用原则是一样的。对于下一节中的讨论,我们会假设一个简单的存储器层
次结构,CPU和主存之间只有一个Ll高速缓存。
教材学习中的问题和解决过程
存储器结构层次
存储技术和计算机软件的一些基本的和持久的属性:
- 存储技术:不同存储技术的访问时间差异很大。速度较快的技术每字节的成本要比速度较慢的技术高,而且容量较小。CPU和主存之间的速度差距在增大。
- 计算机软件:一个编写良好的程序倾向于展示出良好的局部性。
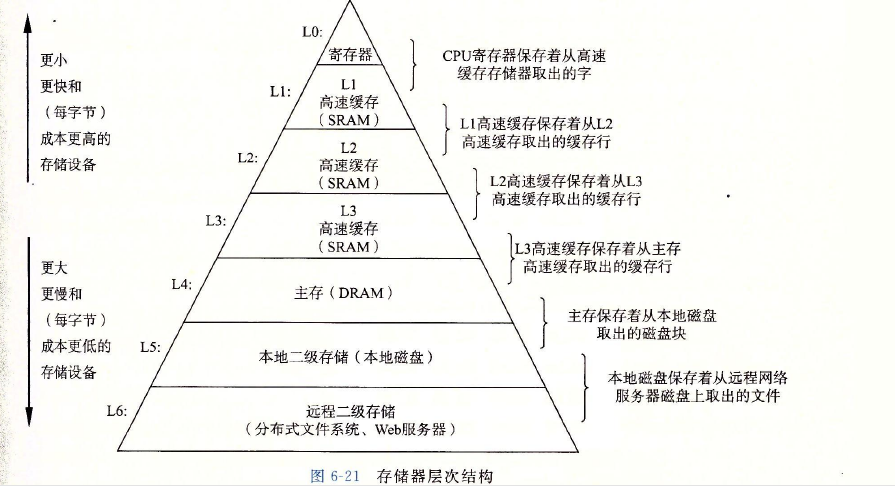
硬件和软件的这些基本属性互相补充得很完美。它们这种相互补充的性质使人想到一种组织存储器系统的方法,称为存储器层次结构(memory
hierarchy),所有的现代计算机系统中都使用了这种方法。图展示了一个典型的存储
器层次结构。一般而言,从高层往底层走,存储设备变得更慢、更便宜和更大。在最高层
(LO),是少量快速的CPU寄存器,CPU可以在一个时钟周期内访问它们。接下来是一个
或多个小型到中型的基于SRAM的高速缓存存储器,可以在几个CPU时钟周期内访问它
们。然后是一个大的基于DRAM的主存,可以在几十到几百个时钟周期内访问它们。接
下来是慢速但是容量很大的本地磁盘。最后,有些系统甚至包括了一层附加的远程服务器
上的磁盘,要通过网络来访问它们。例如,像安德鲁文件系统(Andrew File System,
AFS)或者网络文件系统(Network File System, NFS)这样的分布式文件系统,允许程序
访问存储在远程的网络服务器上的文件。类似地,万维网允许程序访问存储在世界上任何
地方的Web服务器上的远程文件。
代码调试中的问题和解决过程
练习题6. 8
- 三个函数,以不同的空间局部性程度,执行相同的操作。请对这些函数就空间局部性进行排序。解释如何得到排序结果的。
#define N 1000
typedef struct
{
int vel[3];
int acc[3];
} point;
point p [N]
void
{
cleari(point *p, int n)
int i,J;
for (i=0; i<n; i++)
{
for (j=0; j<3; j++) p [i].vel [j]=0;
for(j=0; j<3; j++)
p [i] .acc [j]=0;
}
}
void
{
clear2(point *p,
int n)
int i,J
for (i=0; i<n; i++)
{
for (j=0; j<3; j++)
{
p [i].vel [j]=0;
p [i7.acc [j]=0;
}
}
}
void clear3(point *p,int n)
{
int i,j;
for (j=0; j<3; j++)
{
for (i=0; i<n; i++)
p [i].vel [j] =0;
for (i=0; i<n; i++)
p [i].acc[j]=0;
}
}
解决这个问题的关键在子想象出数组是如何在内存中排列的,然后分析引用模式。函数’clearl以
步长为1的引用模式访问数组,因此明显地具有最好的空间局部性。函数clear2依次扫描N个结
构中的每一个,这是好的,但是在每个结构中,它以步长不为1的模式跳到下列相对于结构起始位
置的偏移处:0, 12, 4, 16, 8, 20。所以clear2的空间局部性比clean的要差。函数c工ear3
不仅在每个结构中跳来跳去,而且还从结构跳到结构,所以单ear3的空间局部性比clear2和
clean都要差。
代码托管
本周结对学习情况
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 500/1000 | 3/7 | 22/60 | |
| 第四周 | 300/1300 | 2/9 | 30/90 | |
| 第五周 | 400/900 | 2/6 | 6/30 | |
| 第六周 | 200/1100 | 1/7 | 6/30 | |
| 第七周 | 500/1600 | 2/9 | 6/36 | |
| 第八周 | 300/1900 | 1/10 | 6/42 | |
| 第九周 | 1000/2900 | 3/13 | 6/48 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:6小时
-
实际学习时间:6小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)