20155228 2017-2018-1 《程序设计与数据结构》第五周学习总结
教材学习内容总结
X86寻址方式经历三代
- DOS时代的平坦模式,不区分用户空间和内核空间,很不安全
- 8086的分段模式
- IA32的带保护模式的平坦模式
ISA的定义
计算机系统使用了多种不同形式的抽象,利用更简单的抽象模型来隐藏实现的细节。对于机器级编程来说,其中两种抽象尤为重要。第一种是由指令集体系结构或指令集架构(Instruction Set Architecture, ISA)来定义机器级程序的格式和行为,它定义了处理器状态、指令的格式,以及每条指令对状态的影响。大多数ISA,包括x86-64,将程序的行为描述成好像每条指令都是按顺序执行的,一条指令结束后,下一条再开始。处理器的硬件远比描述的精细复杂,它们并发地执行许多指令,但是可以采取措施保证整体行为与ISA指定的顺序执行的行为完全一致。
Intel和ATT格式的不同
- Intel代码省略了指示大小的后缀。我们看到指令push和~,而不是pushq和movqo
- Intel代码省略了寄存器名字前面的‘%’符号,用的是rbx,而不是%0orbxoIntel- 代码用不同的方式来描述内存中的位置,例如是'QWORD PTR [rbx]'而不是'(%rbx)'。
- 在带有多个操作数的指令情况下,列出操作数的顺序相反。
数据格式

访问信息

操作数提示符
有多种不同的寻址模式,允许不同形式的内存引用。表中底部用语法Imm(rb,ri,s)表示的是最常用的形式。这样的引用有四个组成部分:一个立即数偏移Imm,一个基址寄存器rb,一个变址寄存器ri和一个比例因子s,这里:必须是1, 2, 4或者8。基址和变址寄存器都必须是64位寄存器。有效地址被计算为Imm+R[rb]十R[i]*s。引用数组元素时,会用到这种通用形式。其他形式都是这种通用形式的特殊情况,只是省略了某些部分。正如我们将看到的,当引用数组和结构元素时,比较复杂的寻址模式是很有用的。

数据传送指令

- MOV相当于C语言的赋值"=",注意ATT格式中的方向
- 注意不能从内存地址直接MOV到另一个内存地址,要用寄存器中转一下。
push和pop
- 两个数据传送操作可以将数据压入程序栈中,以及从程序栈中弹出数据,栈在处理过程调用中起到至关重要的作用。栈是一种数据结构,可以添加或者删除值,不过要遵循“后进先出”的原则。通过push操作把数据压入栈中,通过pop操作删除数据;它具有一个属性:弹出的值永远是最近被压人而且仍然在栈中的值。栈可以实现为一个数组,总是从数组的一端插人和删除元素。这一端被称为找顶。在x86-64中,程序栈存放在内存中某个区域。如图3-9所示,栈向下增长,这样一来,栈顶元素的地址是所有栈中元素地址中最低的,栈指针%rsp保存着栈顶元素的地址。
- 注意栈顶元素的地址是所有栈中元素地址中最低的。
算术和逻辑运算

控制
CMP指令根据两个操作数之差来设置条件码。除了只设置条件码而不更新目的寄存器之外,CMP指令与SUB指令的行为是一样的。在ATT格式中,列出操作数的顺序是相反的,这使代码有点难读。如果两个操作数相等,这些指令会将零标志设置为1,而其他的标志可以用来确定两个操作数之间的大小关系。TEST指令的行为与AND指令一样,除了它们只设置条件码而不改变目的寄存器的值。
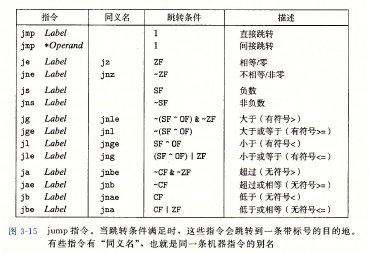
跳转指令
if-else
long fact_do(long n)
{
long result=1;
do{
result*=n;
n=n-1;
}while (n>1);
return result;
}
fact_ do:
movl $1,%eax
.L2:
imulq }rdi,frax
subq $1,%rdi
cmpq $1,%rdi
Jg .L2
rep; ret
do-while
long fact_do(long n)
{
long result=1;
do{
result*=n;
n=n-1;
}while (n>1);
return result;
}
while
long fact_while(long n)
{
long result=1;
while (n>1){
result*=n;
n=n-1;
}
return result;
}
fact_ while:
movl $1,%eax
jmp .L5
.L6:
imulq %rdi,%rax
subq $1,%rdi
.L5:
cmpq $1,%rdi
jg .L6
rep; ret
switch
void switch_eg(long x, long n,
long *dest)
{
long val=x;
switch (n){
case 100:
val*=13
break;
case 102:
val+=10;
/*Fall through*/
case 103:
val+=1i;
break
case
case
104:
106:
val*=val;
break;
default:
val=0;
}
*dest=val;
}
运行时栈
C语言过程调用机制的一个关键特性(大多数其他语言也是如此)在于使用了栈数据结构提供的后进先出的内存管理原则。在过程P调用过程Q的例子中,可以看到当Q在执行时,P以及所有在向上追溯到P的调用链中的过程,都是暂时被挂起的。当Q运行时,它只需要为局部变量分配新的存储空间,或者设置到另一个过程的调用。另一方面,当Q返回时,任何它所分配的局部存储空间都可以被释放。因此,程序可以用栈来管理它的过程所需要的存储空间,栈和程序寄存器存放着传递控制和数据、分配内存所需要的信息。当P调用Q时,控制和数据信息添加到栈尾。当P返回时,这些信息会释放掉。
call
call指令有一个目标,即指明被调用过程起始的指令地址。同跳转一样,调用可以是直接的,也可以是间接的。在汇编代码中,直接调用的目标是一个标号,而间接调用的目标是*后面跟一个操作数指示符。
教材学习中的问题和解决过程
区分MOV,MOVS,MOVZ
- 两类数据移动指令,在将较小的源值复制到较大的目的时使用。所有这些指令都把数据从源(在寄存器或内存中)复制到目的寄存器。MOVZ类中的指令把目的中剩余的字节填充为0,而MOVS类中的指令通过符号扩展来填充,把源操作的最高位进行复制。可以观察到,每条指令名字的最后两个字符都是大小指示符:第一个字符指定源的大小,而第二个指明目的的大小。
代码调试中的问题和解决过程
汇编和反汇编
C语言代码文件mstore.c,包含如下的函数定义:
long mult2(long, long);
void multstore(long x, long y, long *dest){
long t=mult2(x, y);
*dest=t;
}
在命令行上使用“-s”选项,就能看到C语言编译器产生的汇编代码:
linux> gcc -Og -S mstore .c//gcc -S产生的汇编中可以把以`.`开始的语句都删除了再阅读
汇编代码文件包含各种声明,包括下面几行:
multstore:
pushq }rbx
movq %rdx, }rbx
call mult2
movq 0/rax, (}rbx)
popq %rbx
ret
//注意函数前两条和后两条汇编代码,所有函数都有,建立函数调用栈帧
上面代码中每个缩进去的行都对应于一条机器指令。比如,pushq指令表示应该将寄存器%rbx的内容压人程序栈中。这段代码中已经除去了所有关于局部变量名或数据类型的信息。
如果我们使用-c命令行选项,GCC会编译并汇编该代码
linux>gcc -Og -c store.c
这就会产生目标代码文件mstore.o,它是二进制格式的,所以无法直接查看。二进制文件可以用od命令查看,也可以用gdb的x命令查看。
有些输出内容过多,可以使用 more或less命令结合管道查看,也可以使用输出重定向来查看
od code.o | more
od code.o > code.txt
1368字节的文件mstore.o中有一段14字节的序列,它的十六进制表示为:
53 48 89 d3 e8 00 00 00 00 48 89 03 5b c3
这就是上面列出的汇编指令对应的目标代码。从中得到一个重要信息,即机器执行的程序只是一个字节序列,它是对一系列指令的编码。机器对产生这些指令的源代码几乎一无所知。
代码托管

本周结对学习情况
- [201552222](http://www.cnblogs.com/20155222lzj/))
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 10/10 | 1/1 | 6/12 | |
| 第三周 | 220/230 | 2/3 | 6/18 | |
| 第四周 | 270/500 | 1/4 | 6/24 | |
| 第五周 | 400/900 | 2/6 | 6/30 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:6小时
-
实际学习时间:6小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)