合作者:201631062505+201631062302
码云地址:https://gitee.com/SC_looker/wc.exe15.git
另一个队友的博客地址:https://www.cnblogs.com/zjx123456/p/9800829.html
本次作业要求地址链接:https://edu.cnblogs.com/campus/xnsy/2018Systemanalysisanddesign/homework/2188
制定c/c++编程规范
命名约定
类(结构)名
- 类名必须是名词,类名必须明确表示这个类代表了什么。
- 如果类名超过3个单词,说明这个类有可能需要拆分了。
- 不要把父类的名字带到子类中。
- 类名加上后缀也是一种选择。如下载代理类,可以写为DownloadProxy。
- 类名首字母大写;用大写字母分隔单词,除单词的首字母外,全部小写;类名中不要出现下划线“_”。
类(结构)属性名
- 属性由成员前缀”m_“属性,属性名采用匈牙利命名规范。
方法
- 方法与函数执行一个任务,因此应当用动词来命名。比方说,DumpDataToFile()就要好于DataFile()。
- 方法名首字母大写;用大写字母分隔单词,除单词的首字母外,全部小写,方法名中不要出现下划线。
函数
- 方法与函数执行一个任务,因此应当用动词来命名。
- 函数名全部小写,单词之间用下划线分隔。
方法与函数参数名
- 首字母小写。
- 除了第一个单词,所有单词的首字母大写。
- 名称中不应出现”_”。
类库名
- 如果使用C书写类库,或在C++不使用namespace书写类库,为了避免命名冲突,需要在类名,结构名,函数名前加上类库名前缀。类库名应当简洁、明确。 如:
ImEgg* ImEgg_new();
变量名
- 变量名使用匈牙利命名规则。
- 全部小写字母。
- 使用”_”作为分隔符。
- 唯一能违反以上命名规则的,是一些循环中需要用到的自增变量。 如:
格式
1、行宽原则上不超过80列,把22寸的显示屏都占完,怎么也说不过去;
2、尽量不使用非ASCII字符,如果使用的话,参考 UTF-8 格式(尤其是 UNIX/Linux 下,Windows 下可以考虑宽字符),尽量不将字符串常量耦合到代码中,比如独立出资源文件,返不仅仅是风格问题了;
3、UNIX/Linux下无条件使用空格,MSVC的话使用 Tab 也无可厚非; (我没用过Linux,不懂为什么在Linux下无条件使用空格)
4、函数参数、逻辑条件、初始化列表:要么所有参数和函数名放在同一行,要么所有参数并排分行;
5、除函数定义的左大括号可以置于行首外,包括函数/类/结极体/枚举声明、各种语句的左大括号置于行尾,所有右大括号独立成行;
6、./->操作符前后丌留空格,*/&不要前后都留,一个就可,靠左靠右依各人喜好;
7、预处理指令/命名空间不使用额外缩进,类/结构体/枚举/函数/语句使用缩进;
8、初始化用=还是()依个人喜好,统一就好;
9、return不要加();
10、水平/垂直留白不要滥用,怎么易读怎么来。
函数注释
所有的参数都应该有文档说明(param),所有的返回代码都应该有文档说明(return),所有的例外都应该有文档说明(exception)。可以使用(see)引用有关的开发资源。
注释属性
一些自动文档工具定义的属性可以包含在文档中,常用的有:
n 前提条件 (pre)
定义调用这个函数的前提条件
n 警告说明 (warning)
定义一些关于这个函数必须知道的事情。
n 备注说明 (remarks)
定义一些关于这个函数的备注信息。
n 将要完成的工作 (todo)
说明哪些事情将在不久以后完成
n 使用例子说明 (example)
一个图片能表达100句话,一个好的例子能解答1000个问题。
一、功能分析及实现情况
· 基本功能:
统计file.c的字符数(实现)
统计file.c的单词数(实现)
统计file.c的行数(实现)
· 拓展功能:
递归处理目录下符合类型的文件(实现)
显示代码行、空行和注释行的行数(实现)
支持通配符(* , ?)(实现)
· 高级功能:
支持GUI界面并显示详细信息(待实现)
原因:对于这个模块,还不是很熟悉,出现了很多bug,visualC++6.0运用不熟练,搜索了百度依然没有找到解决方法,但是时间来不及了,我们只有把这个模块放在之后完成。
二、PSP
|
PSP |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
30 |
30 |
|
Estimate |
· 估计这个任务需要多少时间 |
10 |
10 |
|
Development |
开发 |
480 |
600 |
|
Analysis |
· 需求分析 (包括学习新技术) |
60 |
70 |
|
Design Spec |
· 生成设计文档 |
5 |
5 |
|
Design Review |
· 设计复审 (和同事审核设计文档) |
30 |
50 |
|
Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
10 |
10 |
|
Design |
· 具体设计 |
60 |
65 |
|
Coding |
· 具体编码 |
480 |
540 |
|
Code Review |
· 代码复审 |
60 |
75 |
|
Test |
· 测试(自我测试,修改代码,提交修改) |
60 |
120 |
|
Reporting |
报告 |
120 |
120 |
|
Test Report |
· 测试报告 |
30 |
60 |
|
Size Measurement |
· 计算工作量 |
10 |
5 |
|
Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 |
60 |
总结:开发的时间远远超出自己所规划的时间,复审也超出了自己预计的时间,事后总结虽然自己规定的时间是那么多,但是两个人的意见不一样,所以时间也超出了
,就这次的设计而言,我还是有些不满意的,对于时间上的规划没有预计好,下次一定会有进步的。
三、代码审核
代码自审 |
代码互审 |
代码评价 |
合并代码 |
|
根据共同的编码规范我们各自审查了自己的代码,总结了以下不足: 1.检查函数名,函数名称不规范,没有让人看出函数的功能。 2.检查注释,注释太少,没有具体的描述 3.检查规格,没有在该留空格的时候打上空格。 4.检查头文件,头文件命名有问题 |
根据共同的编码规范我审查了伙伴的代码,总结了以下不足和好处: 1.检查函数名,函数名称规范,还写出了必要的注释。 2.检查注释,有些地方没有注释。 3.检查规格,格式规范,{}都是单行,函数之间也有空行。 4.检查头文件,头文件没有问题。 |
总体来说代码很清晰,有简单的注释,就是在命名方面还不够严谨。 | 合并代码时,我们统一了命名,在必要的地方加上了注释,规定了代码字体大小。 |
四.关键代码
1.基本功能
int CodeCount(char *Path) { //计算字符个数
FILE *file = fopen(Path, "r");
assert(file != NULL); //若文件不存在则报错
char code;
int count = 0;
while ((code = fgetc(file)) != EOF) //读取字符直到结束
count+= ((code != ' ') && (code != '
') && (code != ' ')); //判断是否是字符
fclose(file);
return count;
}
int WordCount(char *Path) { //计算单词个数
FILE *file = fopen(Path, "r");
assert(file != NULL);
char word;
int is_word = 0; //用于记录字符是否处于单词中
int count = 0;
while ((word = fgetc(file)) != EOF) {
if ((word >= 'a' && word <= 'z') || (word >= 'A' && word <= 'Z')) { //判断是否是字母
count += (is_word == 0);
is_word = 1; //记录单词状态
}
else
is_word = 0; //记录不处于单词状态
}
fclose(file);
return count;
}
int LineCount(char *Path) { //计算行数
FILE *file = fopen(Path, "r");
assert(file != NULL);
char *s = (char*)malloc(200 * sizeof(char));
int count = 0;
for (; fgets(s, 200, file) != NULL; count++); //逐次读行
free(s);
fclose(file);
return count;
}
int Orrid(char *Path)
{
/*FILE *file = fopen(Path, "r");
assert(file != NULL);
printf("code count: %d
", CodeCount(Path));
printf("word count: %d
", WordCount(Path));
printf("line count: %d
", LineCount(Path));*/
int a,b,c;
FILE *fp1=fopen(Path,"w");
printf("字符数,单词数,行数:
");
scanf("%d %d %d",&a,&b,&c);
fprintf(fp1,"该文本文件的字符数为:%d
",a);
fprintf(fp1,"该文本文件的单词数为:%d
",b);
fprintf(fp1,"该文本文件的行数为:%d
",c);
fclose(fp1);
return 0;
2.特殊行数计算
void AllDetail(char *Path) { //显示空行, 代码行,注释行
FILE *file = fopen(Path, "r");
assert(file != NULL);
char *s = (char*)malloc(200 * sizeof(char));//申请空间
int i;
int is_codeline = 0; //状态记录变量
int is_annoline = 0;
int AnnoLock = 0;
int AnnoFileLock = 0;
int codecount = 0;
int annocount = 0;
int blankcount = 0;
while (fgets(s, 200, file) != NULL) { //逐次取文件中的行
for (i = 0; *(s+i) != '�'; i++) {
if ( ( ( *(s+i) >= 'a' && *(s+i) <= 'z') || ( *(s+i) >= 'A' && *(s+i) <= 'Z') ) && AnnoFileLock == 0) {//判断是否是代码行
codecount += (is_codeline == 0 && AnnoLock == 0); //进入代码行的时候代码行加一
is_codeline = 1;
}
if ( *(s+i) == '/' && *(s+i+1) == '/' && is_codeline == 0 && AnnoFileLock == 0){ //判断是否为注释行
annocount++;
AnnoLock = 1;
}
if (*(s + i) == '/' && *(s + i + 1) == '*'){ //判断文档注释开始
AnnoFileLock = 1;
annocount -= is_codeline; //注释在代码后不算注释行,因此减一
}
if (*(s + i) == '*' && *(s + i + 1) == '/') { //判断文档注释结束
AnnoFileLock = 0;
annocount += (*(s + i + 2) == '
'); //注释后换行情况
}
}
annocount += AnnoFileLock; //注释行结束时算作注释行加一
blankcount++; //每一行结束计数加一,并清空状态
is_codeline = 0;
is_annoline = 0;
AnnoLock = 0;
}
free(s);
fclose(file);
blankcount = blankcount - codecount - annocount;
printf("codeline:%d, annoline:%d, blankline:%d
", codecount, annocount, blankcount);
}
3.通过递归实现文件遍历:
void Scan(char *Path, char Type) {
char *FileName = NULL;
char *FileType = NULL;
char Temp[30]; //用于暂存改变得字符串
long Head;
struct _finddata_t FileData;
int i = 0;
FileName = Path;
while (*(Path + i) != '�') { //找出文件名和文件类型的位置
if (*(Path + i) == '\')
FileName = Path + i + 1;
if (*(Path + i) == '.')
FileType = Path + i + 1;
i++;
}
strcpy(Temp, FileType);//调整字符串
*FileType = '*';
*(FileType + 1) = '�';
Head = _findfirst(Path, &FileData);
strcpy(FileType, Temp);//恢复字符串
do {
if ( !strcmp(FileData.name, "..") || !strcmp(FileData.name, ".")) //去除前驱文件路径
continue;
if (_A_SUBDIR == FileData.attrib) //是文件夹
{
strcpy(Temp, FileName); //调整字符串
for (i = 0; *(FileData.name + i) != '�'; i++) {
*(FileName + i) = *(FileData.name + i);
}
*(FileName + i) = '\';
*(FileName + i + 1) = '�';
strcat(Path, Temp);
Scan(Path, Type);
strcpy(FileName, Temp); //恢复字符串
}
else//是文件
{
for (i = 0; *(FileData.name + i) != '.'; i++);
if (!strcmp(FileData.name + i + 1, FileType)) { //是指定类型的文件
strcpy(Temp, FileName);
strcpy(FileName, FileData.name); //调整字符串
printf("%s: ", FileData.name);
Run(Type, NULL, Path); //将地址及功能传到启动函数
printf("
");
strcpy(FileName, Temp);//恢复字符串
}
}
} while (_findnext(Head, &FileData) == 0);
_findclose(Head);
}
4.启动他们的函数
void Run(char Type, char Type2, char *Path) {
switch (Type) {
case 'c': printf("code count: %d
", CodeCount(Path)); break;
case 'w': printf("word count: %d
", WordCount(Path)); break;
case 'l': printf("line count: %d
", LineCount(Path)); break;
case 'a': AllDetail(Path); break;
case 's': Scan(Path, Type2); break;
case 'o':Orrid(Path);break;
default: printf("type input error"); break;
}
}
五.测试结果
1.测试行数
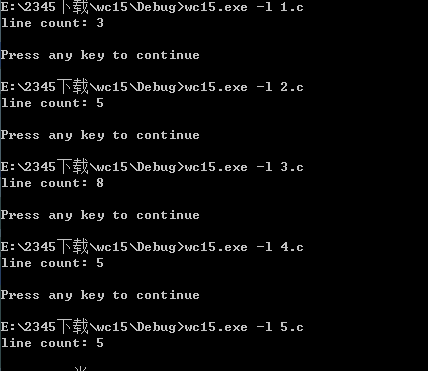 、
、
2.测试字符数
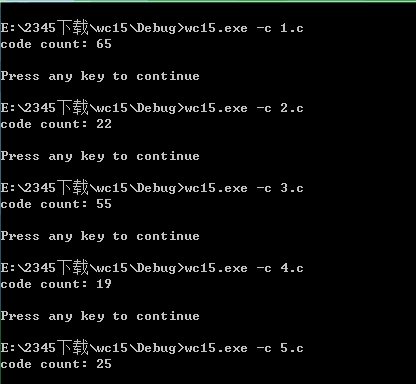
3.测试单词数
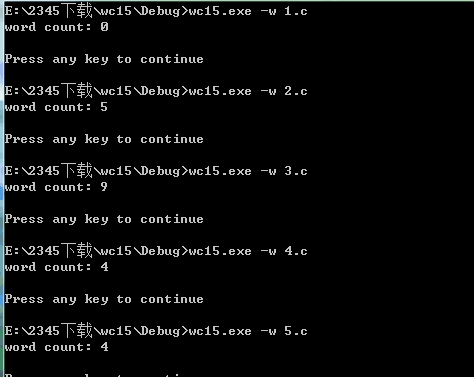
4.多种行数计算测试
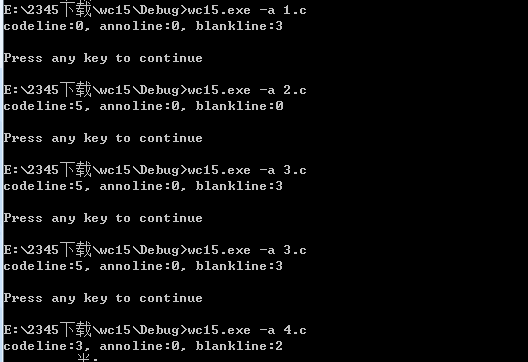
5.遍历文件
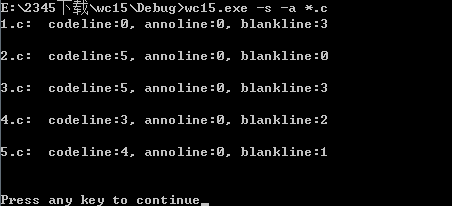
测试所用的文件
1.c
该文本文件的字符数为:64 该文本文件的单词数为:0 该文本文件的行数为:3
2.c
hhhhhhhhhh jjj hhh qqq kkk
3.c
mmm
#include<stdio.h>
int main()
{
printf("hello");
return 0;
}
4.c
ddd come on baby !!!
5.c
hhhhhhhhhhhhh hhhhh hhhh hhh
六 总结
对于这个结对编程,在过程中,我们遇见了很多的问题,其中一些被我们解决了,但仍然存在问题,在这个过程中,两个人之间遇见了很多不同的意见,我们需要磨合。也需要熟悉各自之间的编程模式。