论文地址 :https://arxiv.org/abs/1906.00592
作者 :Baosong Yang, Longyue Wang, Derek F. Wong, Lidia S. Chao, Zhaopeng Tu
机构 : 腾讯AI lab
研究的问题:
在RNN类网络中,使用的是序列建模,可以表示位置信息。而在self-attention network(SAN)的网络中,学习位置信息的能力较弱。本文做的就是提出一种单词重排的检测任务来量化san和RNN的学习位置信息的能力。具体地说,就是随机地将一个单词移动到另一个位置,看一个训练好的模型能否同时检测到原始位置和插入位置。
研究方法:
单词重排检测任务:
描述如下:给定一个句子X,随机地将一个词插入到另一个位置上,任务的目的就是检测哪个单词被挑出来,以及它被插入在哪个位置。模型的输出包括“I”O”两个标记。也就是一个指针检测任务。如下所示。
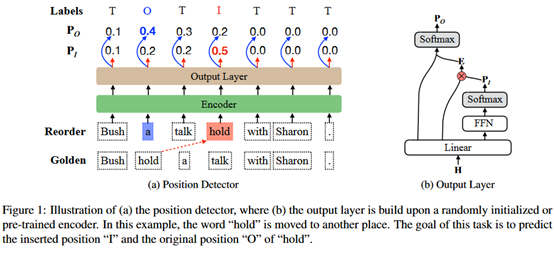
在训练过程中,训练目标是最小化真实插入位置和原始位置的交叉熵。
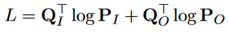
这里的Q_I和Q_O都是one-hot的向量。
实验部分:
模型:使用RNN、SAN、DiSAN三个模型
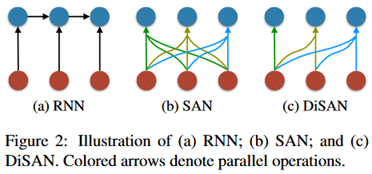
学习目标:分别使用两种策略来训练encoder,输出层都是上述单词重排检测任务。
策略一:直接使用单词重排检测任务的数据训练encoder,与输出层协同训练,使用检测精度作为学习目标。
策略二:以机器翻译为学习目标,先训练一个NMT模型,包括编码器和解码器,然后在单词重排检测任务上只训练与输出层有关的参数。
实验结果如下:
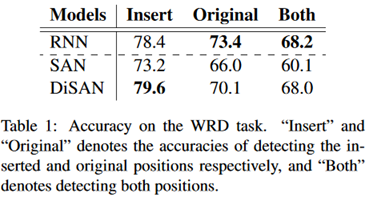
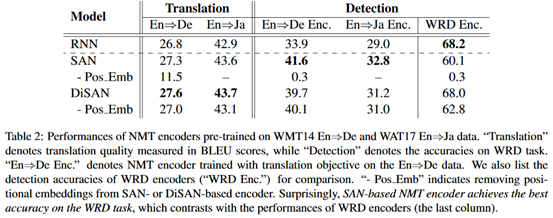
结论:
(1)SAN在该任务上的表示不如RNN,但在机器翻译中不成立。
(2)在下游任务(如翻译)中,学习目标比模型结构更重要。
(3)在机器翻译中,位置编码对于SAN来说已经足够好了。DiSAN对于SAN来说是一种更有效地学习词序信息的机制。
对于为什么在机器翻译中,SAN的表现较好。作者认为SAN通过保留更多的语序信息来弥补其在并行结构上的不足,从而有助于更深层的编码。作者补充了一个实验。
像“研表究明,汉字的序顺并不定一能影阅响读”这句话,大家基本都可以理解它的意思。那机器能不能理解呢?作者将语句打乱后用于翻译模型。结果如下:
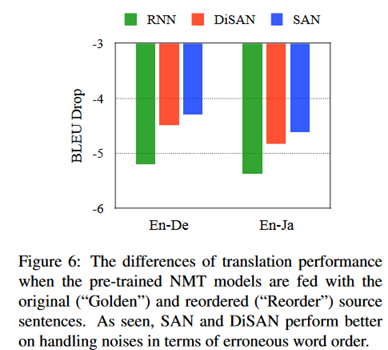
可以看到与RNN相比,SAN和DiSAN在翻译质量上的下降幅度更小,说明了self-attention在去除错误顺序的噪声方面的有效性。
评价:
通过识别打乱的token的任务来研究RNN和self-attention网络对于位置信息的建模能力。实验本身比较简单,不过作者结合具体的应用场景(机器翻译)的实验得到了一些新的结论。不过这里只讨论了机器翻译,没有提到在其他的NLP任务中是否是类似的结论。 3分。