论文地址:https://arxiv.org/abs/1906.03731v1
作者 : Sofia Serrano, Noah A. Smith
机构 :华盛顿大学
研究的问题:
在句子分类任务中讨论attention的作用,主要是通过中间表示擦除的方法来验证注意力机制的作用,即通过mask注意力权重来观察模型预测结果所发生的变化。本文和其它研究区别的一点在于,观察注意力在多大程度上表示了中间量的重要性,而以往的研究主要关注于注意力是否足以作为一个模型决策的整体解释。
研究方法:
可解释性可以理解为,Attention权重的高低应该与对应位置信息的重要程度正相关;高权重的输入单元对于输出结果有决定性作用。本文的主要研究方法是中间表示擦除,主要逻辑在于越重要的权重对输出结果的影响越大,将它置零就会对结果有直接的影响。
评价指标:
Total Variance Distance(TVD) :作为输出结果分布区别的指标:
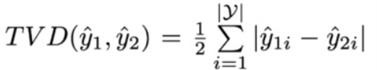
Jensen-Shannon Divergence(JSD)作为输出结果分布和Attention权重区别的指标:
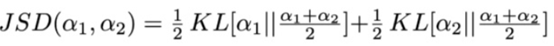
实现方式:
如下图所示,模型分为两个部分,第一个部分是嵌入和编码部分,例如一个全连接层实现词嵌入再用一层双向LSTM实现编码,实验中具体使用的多个模型各不相同。第二个是解码部分,将Attention层得到的输出张量解码成具体任务需要的结果,在文本分类任务上就是一个全连接层实现的维度变换。需要注意的是,这里Attention层并不是像seq2seq模型那样作用在解码器上的,而是作为一个独立的层来进行测试。
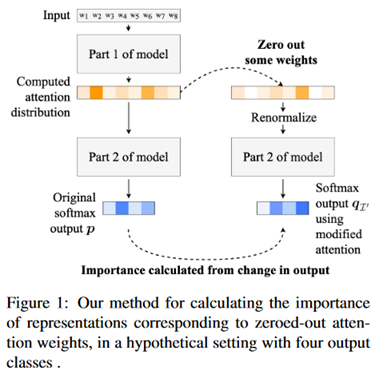
整个模型运行两次,第一次正常输入输出,保留得到的结果,第二次将Attention层上选中擦除的权重置为0,重新用Softmax归一化权重,继续之后的流程得到结果,与第一次得到的数据计算TVD指标。在Attention层上擦除而不是在输入端擦除是为了将其影响与前置的编码部分隔离。renormalizing的目的在于当模型置零了部分高权重的参数之后会导致Attention层输出的张量趋近于0,而这是模型在训练过程中没有遇到过的情况,进而会导致模型的决策行为不可控。
实验设置:
1、数据集:使用四个文本分类的数据集,分别是Yahoo Answers、IMDB、Amazon、Yelp,细节如下:

2、模型:
主要基于Hierarchical Attention Network(HAN),一个分层的Attention模型,分为词语级和句子级两个部分,实验只测试句子级的Attention层,将之前的部分均视为编码阶段。并且讨论了两种变体:
FLAN:在前一个模型的基础上修改得到的只有一个词级别的Attention层对不分句对整个文档进行操作
编码器的改变:,包括在编码器中使用双向RNN结构替换为CNN,和不使用编码器,直接将词嵌入之后的结果输入Attention层。
实验部分:
主要通过单一权重置0和一组权重置0两种方法,前者测试的是擦除最高权重对应的中间表示之后整个模型输出结果的变化大小,后者测试的是为了改变模型的最终决策需要擦除多少中间表示以及如何擦除,进而从实验数据中找到可解释性的依据。
实验一:mask最大的注意力权重与随机mask权重对模型输出的影响
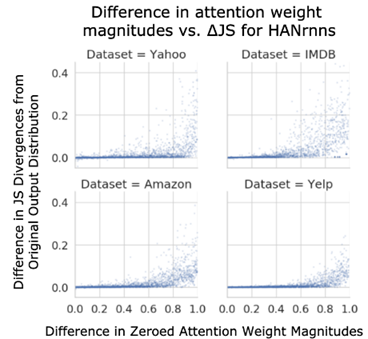
实验发现随着mask的最大权重与随机权重差距的增大,最大权重对模型影响也越大。图中可以看到,有大量的点在y=0附近,一方面可能是这些测试样本极性不强,注意力权重比较平均,另一方面也可能是由于作者使用的RNN学习到了上下文相关的知识,导致mask注意力权重对模型的影响减小。然而作者认为这项实验还不足以说明最大的权重与随机的权重对模型影响的差异,于是有了第二项实验。
实验二:mask最大权重与mask随机权重能否使模型分类错误
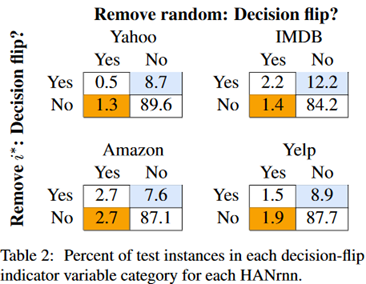
可以看出,mask最大权重比mask随机权重更容易让模型分类错误(蓝色部分),但仍然还有一小部分样本是反过来的(橙色部分)。
总体来说,大部分的情况下不影响模型决策,可以看出,单纯地擦除一个中间表示并不会影响attention层的鲁棒性。
实验三:找到一个最小的mask集合让模型保证正确分类
作者认为某项token越重要,那么mask它使模型分类错误的可能性也就越大,所以找到的mask集合越小,这个集合中的token越重要。作者提出了4种方法来找这样一个mask集合,并比较哪种方法找到的mask集合更小:
1、随机mask
2、将注意力权重从大到小排序,依次mask
3、使用注意力权重的梯度来对权重进行排序,依次mask
4、按照梯度值和注意力权重相乘的值来排序,依次mask
一般来说如果某个feature的梯度是一个很大的正值,那么我们就认为这个feature比较重要,这也是一种衡量重要性的方法。
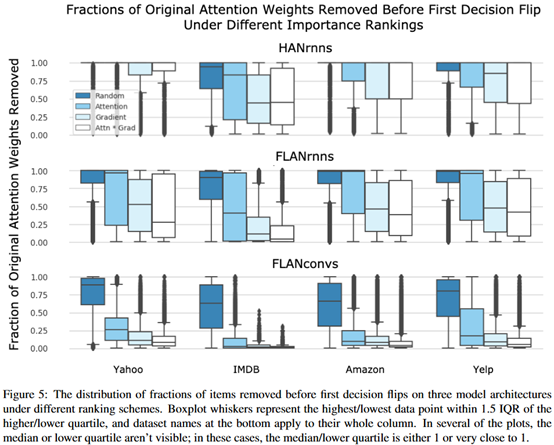
从图中可以看到,4种方法的效果是从1到4依次上升的,其中随机远差于另外三种方法。方法2效果虽然不如剩下两种方法好,但是差距并不大。作者得到的结论是Attention并未最大化描述模型的决策行为,以Attention权重作为依据是有效但不是最优的。
最终,作者给的结论如下:
What is clear is that in the settings we have examined, attention is not an optimal method of identifying which attended elements are responsible for an output. Attention may yet be interpretable in other ways, but as an importance ranking, it fails to explain model decisions.
评价:
探究注意力的可解释性的一篇论文,研究方法是通过mask相关参数探究影响。总的来说,attention的权重和特征的重要性并非很相关,但在一定程度上也反应了输入的重要性。