上一篇介绍了决策树之分类树构造的几种方法,本文主要介绍使用CART算法构建回归树及剪枝算法实现。主要包括以下内容:
1、CART回归树的介绍
2、二元切分的实现
3、总方差法划分特征
4、回归树的构建
5、回归树的测试与应用
6、剪枝算法
一、CART回归树的介绍
回归树与分类树比较类似,不同的是分类树最后的决策的结果是离散型的值,回归树决策的结果是输出一个实数。
二、二元切分的实现
CART算法做回归树时,只做二元切分,最后生成的树是一棵二叉树。切分代码如下:
1 def bin_split_data_set(data_set, feature, value): 2 """对数据集进行二元切分""" 3 # np.nonzero(data_set[:,feature] > value)[0] 返回feture值 大于 value 的行号 4 mat0 = data_set[np.nonzero(data_set[:, feature] == value)[0], :] 5 mat1 = data_set[np.nonzero(data_set[:, feature] != value)[0], :] 6 return mat0, mat1
由于使用的数据集特征是枚举类型的,所以这里条件是 【等于】 np.nonzero(data_set[:, feature] == value,假如为连续数值型的,可以使用【小于】或【大于】
三、总方差法划分特征
上一节讲到分类树有三种常用划分特征的方法,分别是信息增益,增益率,和基尼指数。CART回归树这里使用最小总方差法选取划分特征。
1 def reg_leaf(data_set): 2 """生成叶子结点""" 3 # 计算平均值 4 result = tools.filter_reg_values(data_set) 5 value = np.mean(result) 6 return value 7 8 9 def reg_err(data_set): 10 """总方差""" 11 # np.val 计算标准差 12 result = tools.filter_reg_values(data_set) 13 return np.var(result) * np.shape(data_set)[0] 14 15 def choose_best_split(data_set, ops=(1, 4)): 16 """ 17 选取最好的划分特征值 18 data_set:数据集 19 ops(x,y):x--误差减少最小值 y--分类后样本最少个数 20 """ 21 tols = ops[0] 22 toln = ops[1] 23 24 # 所有分类相同(mat.flatten() 将矩阵数据压平) 25 if len(set(np.array(data_set[:, -1].flatten()[0])[0])) == 1: 26 return None, reg_leaf(data_set) 27 28 m, n = np.shape(data_set) 29 s = reg_err(data_set) 30 31 # np.inf 无限大的数 32 best_s = np.inf 33 best_index = 0 34 best_value = 0 35 36 # 遍历每一个特征 37 for feat_index in range(n - 1): 38 # 遍历当前特征的所有值 39 for value in set(flatten(np.array(data_set)[:, feat_index])): 40 mat0, mat1 = bin_split_data_set(data_set, feat_index, value) 41 # 分类后样本个数较少,则退出本次循环 42 if np.shape(mat0)[0] < toln or np.shape(mat1)[0] < toln: 43 continue 44 # 计算新的误差 45 new_s = reg_err(mat0) + reg_err(mat1) 46 47 # 更新最小误差 48 if new_s < best_s: 49 best_index = feat_index 50 best_value = value 51 best_s = new_s 52 53 # 如果误差减小不大,则退出 54 if s - best_s < tols: 55 return None, reg_leaf(data_set) 56 57 # 如果切片分出的数据集很小,就退出 58 mat0, mat1 = bin_split_data_set(data_set, best_index, best_value) 59 if mat0.shape[0] < toln or mat1.shape[0] < toln: 60 return None, reg_leaf(data_set) 61 62 return best_index, best_value
四、回归树的构建
递归创建树形结构:
1 def create_tree(data_set, ops=(1, 4)): 2 """创建回归树""" 3 feat, val = choose_best_split(data_set, ops) 4 if feat is None: 5 return val 6 ret_tree = dict() 7 ret_tree['feature'] = feat 8 ret_tree['value'] = val 9 10 # 左右子树 11 left_data, right_data = bin_split_data_set(data_set, feat, val) 12 ret_tree['left'] = create_tree(left_data, ops) 13 ret_tree['right'] = create_tree(right_data, ops) 14 15 return ret_tree
五、回归树的测试与应用
选取UCI上面的用于回归的数据集,分为训练集 和 测试集。
生成的回归决策树图形如下:
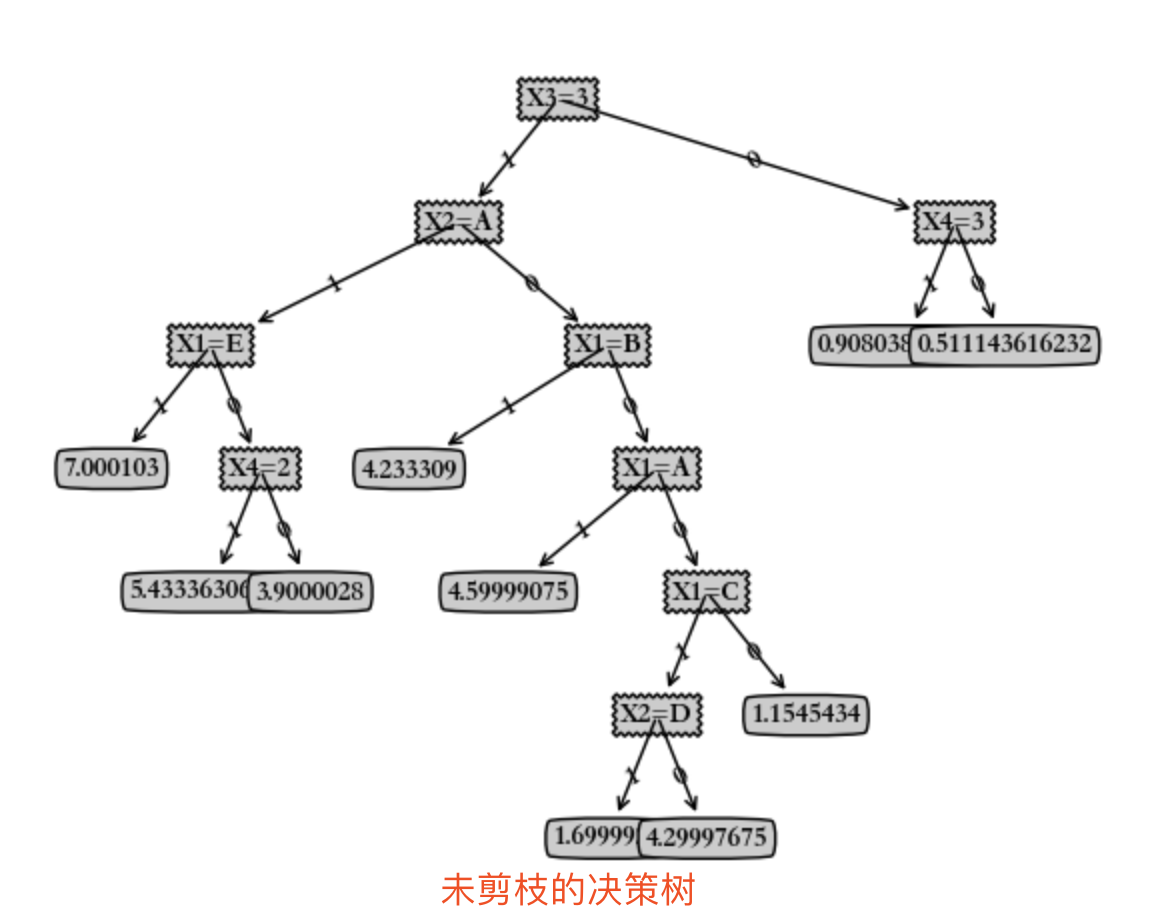
六、决策树的修剪:
决策树在构造之后,可能会出现过度拟合的现象,决策树的复杂度过大,预测效果并不理想,所以需要对决策树进行剪枝。剪枝就是将决策树的枝叶适当减去,使决策树更加精简,预测效果更加准确。根据剪枝所出现的时间点不同,分为预剪枝和后剪枝。预剪枝是在决策树的生成过程中进行的;后剪枝是在决策树生成之后进行的。
预剪枝:
在构造决策树的同时进行剪枝。为了避免过拟合,可以设定一个阈值,如决策树的高度等,使构造的决策树不能大于此阈值,由于事先定好阈值,这种方法实际中的效果并不好。决策树构造完成后进行剪枝。剪枝的过程是对拥有同样父节点的一组节点进行检查,判断如果将其合并,熵的增加量是否小于某一阈值。如果确实小,则这一组节点可以合并一个节点,其中包含了所有可能的结果。
后剪枝:
后剪枝的剪枝过程是删除一些子树,然后用其叶子节点代替,这个叶子节点所标识的类别通过大多数原则确定。所谓大多数原则,是指剪枝过程中, 将一些子树删除而用叶节点代替,这个叶节点所标识的类别用这棵子树中大多数训练样本所属的类别来标识。
后剪枝算法
后剪枝算法有很多种,这里简要介绍两种:
Reduced-Error Pruning (REP,错误率降低剪枝)
用训练样本构造的决策树可能过度拟合,所以再用测试数据集去修正。对于完全决策树中的每一个非叶子节点的子树,我们尝试着把它替换成一个叶子节点,该叶子节点的类别我们用子树所覆盖训练样本中存在最多的那个类来代替,这样就产生了一个简化决策树,然后比较这两个决策树在测试数据集中的表现,如果简化决策树在测试数据集中的错误比较少,那么该子树就可以替换成叶子节点,如果。
Pessimistic Error Pruning (PEP,悲观剪枝)
PEP剪枝算法是在C4.5决策树算法中提出的, 把一颗子树(具有多个叶子节点)用一个叶子节点来替代的话,比起REP剪枝法,它不需要一个单独的测试数据集。
REP剪枝算法的代码:
1 def is_tree(obj): 2 """判断是否是树""" 3 return isinstance(obj, dict) 4 5 6 def get_mean(tree): 7 """返回树的平均值""" 8 if is_tree(tree['right']): 9 tree['right'] = get_mean(tree['right']) 10 if is_tree(tree['left']): 11 tree['left'] = get_mean(tree['left']) 12 13 value = (tree['left'] + tree['right']) / 2.0 14 return float('%.2f' % value) 15 16 17 def prune(tree, test_data): 18 """对树进行剪枝""" 19 # 测试数据为空 20 if np.shape(test_data)[0] == 0: 21 return get_mean(tree) 22 23 # 切分测试数据 24 if is_tree(tree['left']) or is_tree(tree['right']): 25 l_set, r_set = tools.bin_split_data_set(test_data, tree['feature'], tree['value']) 26 27 # 递归对左右子树进行剪枝 28 if is_tree(tree['left']): 29 tree['left'] = prune(tree['left'], l_set) 30 if is_tree(tree['right']): 31 tree['right'] = prune(tree['right'], r_set) 32 33 # 左右都为叶子结点 34 if not is_tree(tree['left']) and not is_tree(tree['right']): 35 l_set, r_set = tools.bin_split_data_set(test_data, tree['feature'], tree['value']) 36 37 # 未合并的误差 38 error_no_merge = sum(tools.filter_reg_values(l_set) - tree['left'], 2) + sum( 39 np.power(tools.filter_reg_values(r_set) - float(tree['right']), 2)) 40 # 合并左右结点之后的误差 41 tree_mean = (tree['left'] + tree['right']) / 2.0 42 error_merge = sum(np.power(tools.filter_reg_values(test_data) - tree_mean, 2)) 43 44 # 如果合并后误差减小,则进行合并 45 if error_merge < error_no_merge: 46 print('merging') 47 return float('%.2f' % tree_mean) 48 else: 49 return tree 50 else: 51 return tree
剪枝后生成的决策树如下:

对比剪枝前和剪枝后的决策树,剪枝后的决策树更加精简,相应的准确率也更高。
本文的完整代码见https://gitee.com/beiyan/machine_learning/tree/master/decision_tree
本文只是简单实现CART回归树及剪枝算法,随着决策树的研究,也出现很多改进的或者新的划分算法和剪枝算法,后面慢慢学习。