3.mysql数据库
3.10 单表查询
3.10.1. 简单查询
查询在数据库中使用的频率是最高的:十次查询,一次增删改。
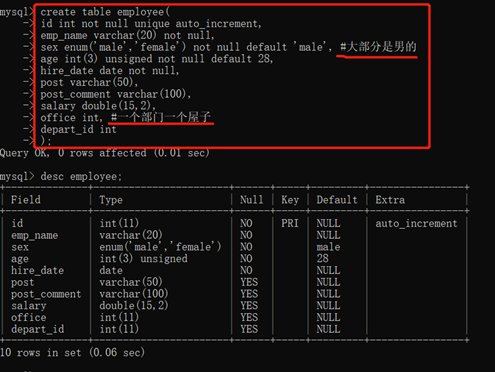
1)建表
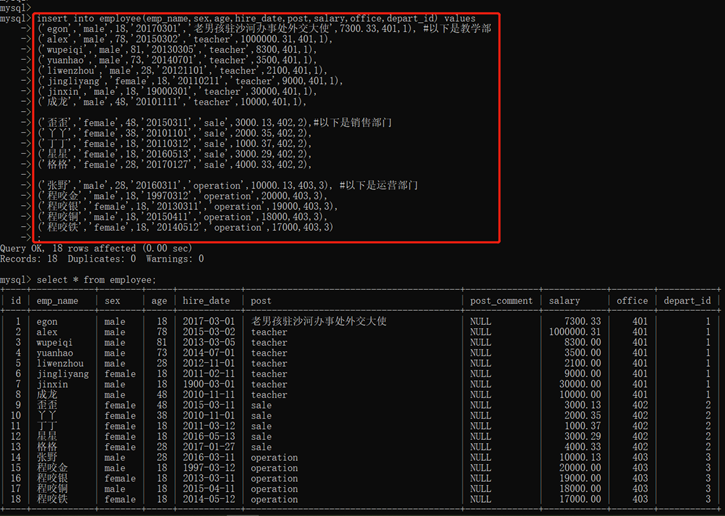
2)插入数据
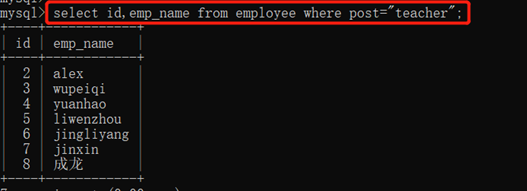
3.10.1.1. 选择字段:select
select 字段名1,字段名2…… from 表名 where 条件;
3.10.1.2. 字段重命名(别名):as
select 字段名1,字段名2 as 别名…… from 表名 where 条件;
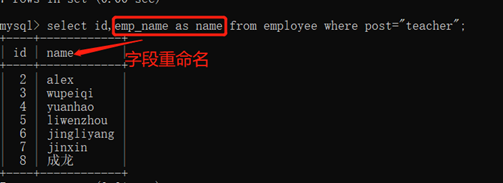
可以省略as,用空格代替
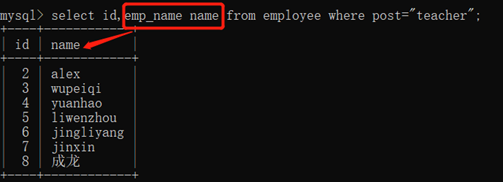
使用别名不会修改数据库中的字段名
3.10.1.3. 去重:distinct
select distinct 字段名 from 表名 where 条件;
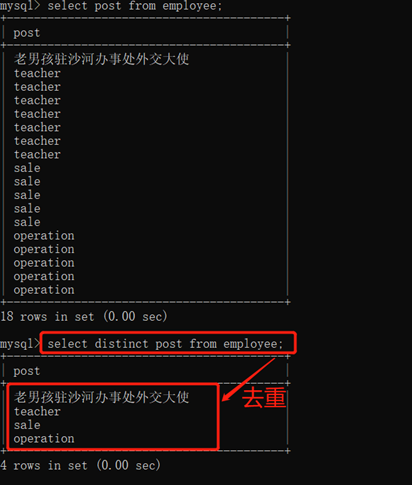
联合去重
select distinct 字段名1, 字段名2…… from 表名 where 条件;
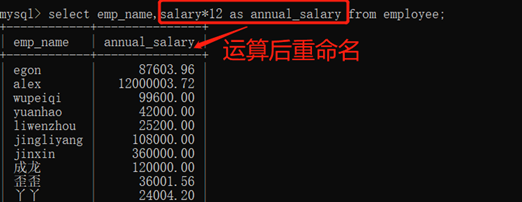
3.10.1.4. 四则运算(+ - * /)
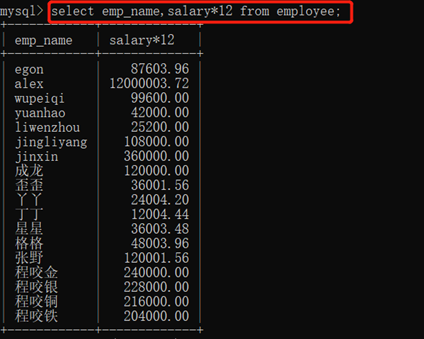
运算后重命名
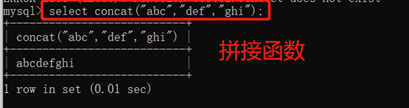
3.10.1.5. 拼接函数:concat(),拼接数据输出字符串

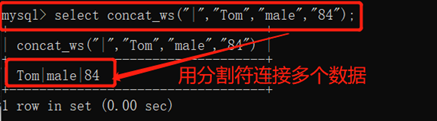
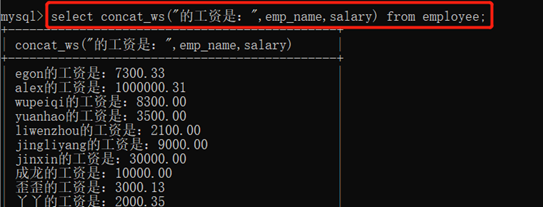
concat_ws(分隔符,字段1,字段2……)
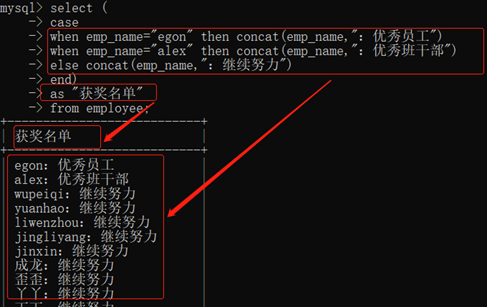
3.10.1.6. 判断:case...end
3.10.2. where 约束
where作用:筛选所有符合条件的行
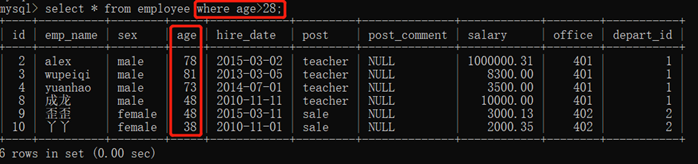
3.10.2.1. 比较运算符:> < >= <= <> !=
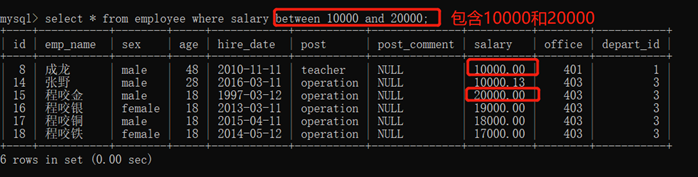
3.10.2.2. 满足区间:between...and...
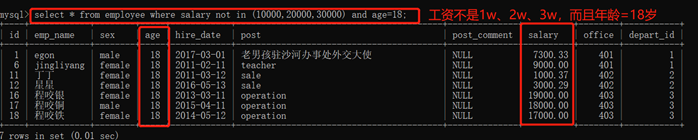
3.10.2.3. 成员判断:in()

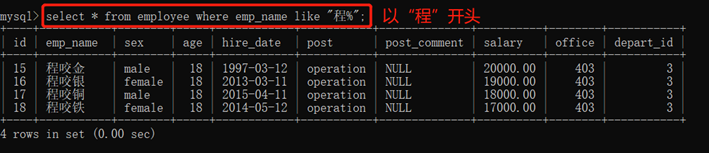
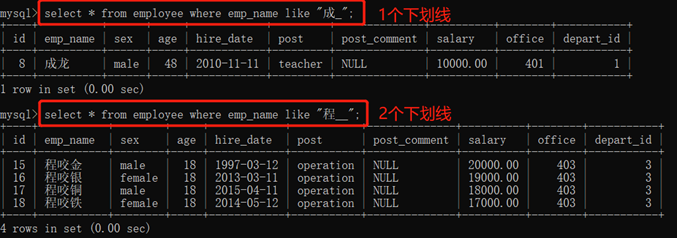
3.10.2.4. 模糊查询:like
1)%表示任意多字符


2)_表示一个任意字符
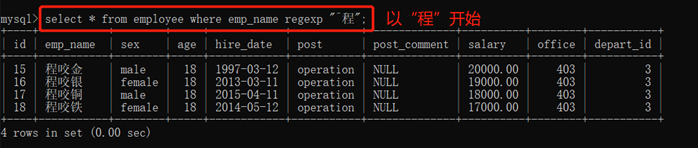
3.10.2.5. 使用正则表达式模糊查询:regexp
1)“^xxx” 表示以“xxx”开始
2)“xxx$” 表示以“x”结尾

3)“{n}” 重复n次

3.10.2.6. 逻辑运算符:and or not
在多个条件直接可以使用逻辑运算符 and or not
运算优先级:not > and > or

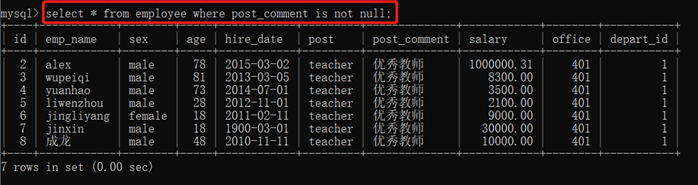
3.10.2.7. 判断是否为空:is null
3.10.3. 分组:group by
分组group by

3.10.4. 聚合:count、max、min、avg、sum
聚合函数聚合的是组的内容:COUNT()、MAX()、MIN()、AVG()、SUM()
没有使用group by分组,直接使用聚合函数,则把整张表作为一个分组。
1)count()根据分组计数
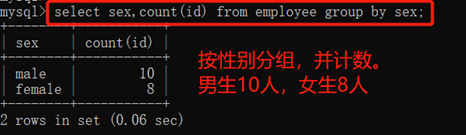
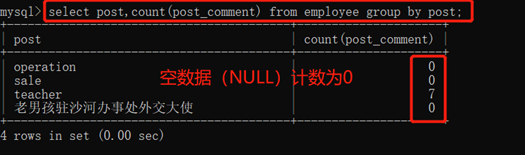
count(*)统计符合条件的行数

2)max()求最大值

3)min()求最小值

4)avg()求平均值

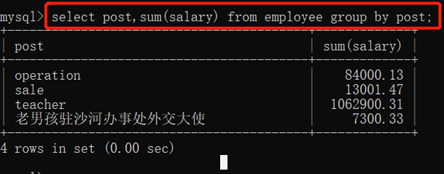
5)sum()求平均值
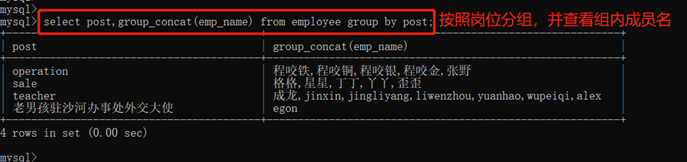
6)展示分组内某项数据的集合:GROUP_CONCAT()
只能展示,使用数据时无法分开取值
7)where 条件 + group by:对满足条件的数据,进行分组

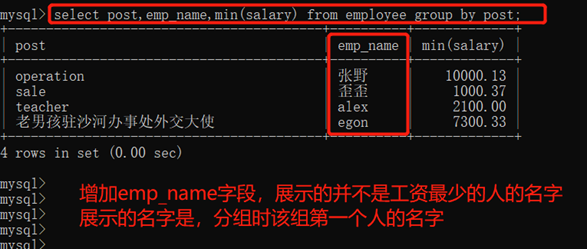
注意:使用聚合时,只有分组和聚合数据是匹配的
显示其它字段时,显示内容和聚合数据并不匹配。
3.10.5. 过滤:having
1)执行优先级从高到低:where > group by > having
2)Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。

3)Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数

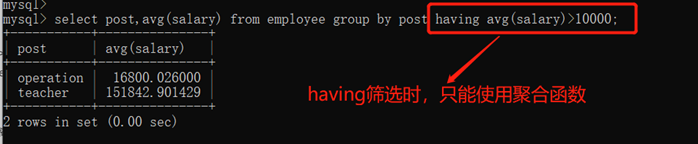
4)where和having联合使用

5)练习
(1)查询各岗位内包含的员工个数大于2的岗位名、岗位内包含员工名字、个数

(2)查询各岗位平均薪资大于10000的岗位名、平均工资
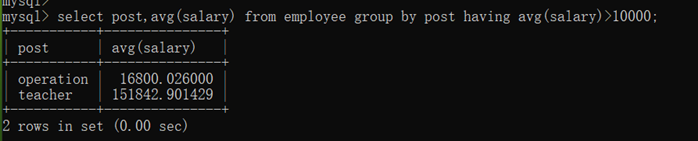
(3)查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资

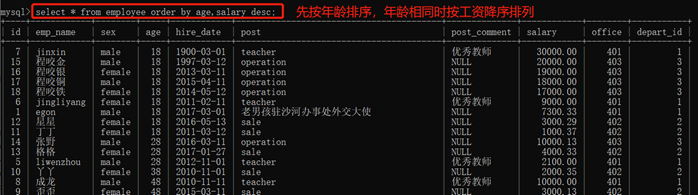
3.10.6. 查询排序:order by
1)默认排序是从小到大
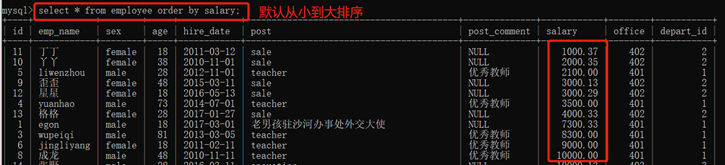

也可以用asc(升序关键字)从小到大排列

2)从大到小排序:desc(降序关键字)


3)组合排序(主要关键字在前)
order by 字段1,字段2:先按字段1排序,字段1相同时按字段2排序。也可使用desc降序。
3.10.7. 限制查询记录数:limit
limit 数字:限制显示几条数据


limit m,n:从第m+1记录开始取,取n条记录;没有给定m时,m默认为0。

limit n offset m = limit m,n

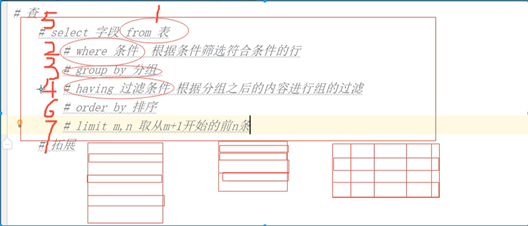
3.10.8. 数据查询的执行顺序
1)from子句指定数据源
2)where子句基于指定的条件对记录进行筛选
3)group by子句将数据划分为多个分组,使用聚合函数进行计算
4)使用having子句筛选分组
5)使用select取出字段值
6)使用oredr by对select取出的字段值进行排序
7)使用limit限制记录数量
注意:having虽然执行在select之前,但执行having时解析了select,因此:
(1)select中的别名having可以使用,
(2)select中没有的字段having不能使用。
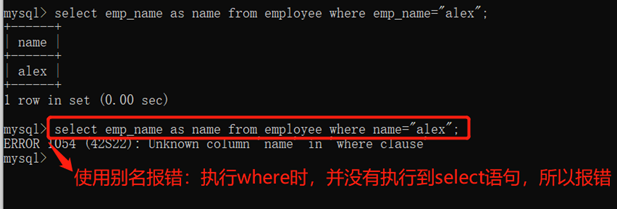

重命名使用规则:
(1)where条件中不能使用select字段的重命名
(2)order by或者having可以使用select字段的重命名
3.10.9. select获取数据机制
1)首先通过from表名,找到表
2)然后过where,group by,having锁定数据行。
3)最后循环每一行,执行select语句,找到数据。