1.1.1 辅助排序(二次排序)
(1)二次排序定义
通常情况下我们只对键进行排序,例如(年份,温度)组成的键值对,我们通常只对key年份进行排序,如果先按照年份排好序,还要求年份相同的再按照温度进行进行逆序排列,像这样先按照第一字段进行排序,然后再对第一字段相同的行按照第二字段排序,我们称为二次排序。
(2)组合键定义
因为排序都是针对键的排序,现在要求按照两个字段进行排序,那么可以定义一个对象,包含两个字段,并且把这个对象作为map的输出键,就可以实现组合键的排序。如果map输出值的话不重要,就设置为NullWritable对象。因为这个对象要作为map的键,而且还要能够进行比较,所以对象要实现WritableComparable接口。定义一个两个字段的Class如下,first保存年份,second保存温度。实现序列化、反序列化接口、对比接口。对比接口是比较两个字段,按照第一字段升序排列,第一字段相同的按第二字段逆序排列。
package Temperature;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class IntPair implements WritableComparable<IntPair> {
long first;
double second;
public IntPair()
{
}
public IntPair(long first, double second) {
this.first = first;
this.second = second;
}
@Override
public int compareTo(IntPair o) {
if (first!=o.getFirst()) {
return (int) (first-o.getFirst());
}
return (second-getSecond())==0? 0:(second-getSecond())>0? 1:-1;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(first);
dataOutput.writeDouble(second);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
first=dataInput.readLong();
second=dataInput.readDouble();
}
public long getFirst() {
return first;
}
public void setFirst(long first) {
this.first = first;
}
public double getSecond() {
return second;
}
public void setSecond(double second) {
this.second = second;
}
}
(3)二次排序实例
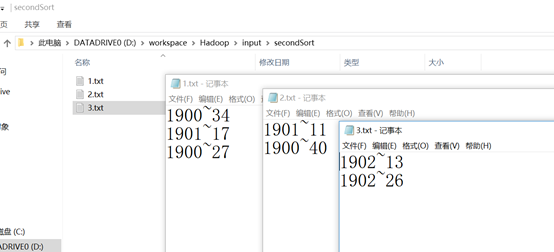
需求:求出下列数据中气象站每年的最高气温,下面只是为了说明,实际肯定不只6行数据。6行数据保存在三个不同文件中。
文件1
1900~34
1901~17
1900~27
文件2
1901~11
1900~40
文件3
1902~13
1902~26
实现步骤:
1)定义map类,读取三个文件中的数据,定义组合键类FirstSecondPair,将年份写入第一个字段,温度写入第二个字段,实现CompareTo函数,按照年份升序,按照温度降序排列。
public static class SecondSortMaper extends Mapper<LongWritable, Text, IntPair, NullWritable>
{
@Override
//map的作用是解析记录,得到年和 温度,组成组合键输出
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntPair, NullWritable>.Context context) throws IOException, InterruptedException {
String strValue=value.toString();
String values[]=strValue.split("~");
int year=Integer.parseInt(values[0]);
double temperature=Double.parseDouble(values[1]);
//map输出默认按照键排序,也就是按照FirstSecondPair的CompareTo定义的排序规则排序
context.write(new IntPair(year,temperature),NullWritable.get());
}
}
map处理后输出数据应该是如下这样。
1900 40 NULL
1900 34 NULL
1900 27 NULL
1901 17 NULL
1901 11 NULL
1902 26 NULL
1902 13 NULL
2)如果是大量数据的话,需要对多个reduce任务来处理,为了让年份相同的数据被同一个reduce处理,这样才能找出每一年的最高气温,需要定义分区类Partitioner,让年份相同数据进入同一个分区。按组合键第一字段分区的类定义如下:
//按照组合键的第一个字段年份进行分区,让相同年份的数据被同一个分区处理,才能比较出每一年的最高气温
public static class FirstPartitioner extends Partitioner<IntPair,NullWritable>{
@Override
public int getPartition(IntPair intPair, NullWritable nullWritable, int numPartition) {
//numPartition是分区数,根据年份取余得到分区编号,可以保证年份相同记录进入通一个分区,但一个分区内有多个年份的记录。
//例如1900~2000年的数据,numPartition为10,则1900,1910,1930……2000这些取余后都为0,这些年份的记录都会放入分区0,
//需要对分区0中的记录按照年份分组,setGroupingComparatorClass就起到了这个分组的作用,分组后再按温度逆序排序
int partition=(int)(intPair.getFirst()%numPartition);
return partition;
}
}
例如采用两个reduce任务,就会有两个分区,分区函数采用年份取余2。那么1900和1902年的数据都会被分到第一个reduce,1901年的数据被分到第二个reduce。shuftle分区后的数据如下所示:
分区1
1900 40 NULL
1900 34 NULL
1900 27 NULL
1902 26 NULL
1902 13 NULL
分区2
1901 17 NULL
1901 11 NULL
3)在分区1中有1900和1902两个年份的数据,为了得到每一年的最高气温,需要对同一个分区的数据,按照年份进行分组,每一组的第一条数据就是我们想要的每年最高的气温。这时候就需要用GroupingComparator来实现分组,就是把年份相同的分为一组。分组类定义如下:
//一个reduce中有多个年份的数据,按照年份进行分组,分组后在按键进行聚合,年份相同的键都被认为是同一个键,聚合为第一个键,值都是NULL
public static class ReducerGroupingComparator extends WritableComparator
{
public ReducerGroupingComparator()
{
super(IntPair.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
IntPair pairA=(IntPair)a;
IntPair pairB=(IntPair)b;
//年份相同,返回值为0的分为一组
return (int) (pairA.getFirst()-pairB.getFirst());
}
}
分区1中的数据分组之后变为
组1
1900 40 NULL
1900 34 NULL
1900 27 NULL
组2
1902 26 NULL
1902 13 NULL
分组并不是分为一组那么简单,还有按键聚合的功能。组1中三条记录虽然三个键都不相同<1900 40>、<1900 34>、<1900 27>,但是ReducerGroupingComparator进行键的比较只是按照第一字段年份进行比较,所以是相同的键,所以年份相同的键会被合并,即为第一个键<1900 40>,三条记录的值也会合并,变为<NULL,NULL,NULL>。这里的值并不重要。所以按键聚合之后数据为
组1
1900 40 <NULL,NULL,NULL>
组2
1902 26 <NULL,NULL >
4)分组之后再按键聚合的数据就是我们要获取的的每年的最高气温值,还要通过reduce函数排个序。在将键传给reduce函数的key,值组成的values的迭代器iterator传给reduce方法的入参values,这里的值其实不重要,直接将key写入输出文件,默认就会按照键IntPair排序(年份升序,没有年份相同的气温)。
public static class SecondSortReducer extends Reducer<IntPair,NullWritable, LongWritable, DoubleWritable>
{
//Reducer<LongWritable, Text, FirstSecondPair, NullWritable>.Context 一定要这么写,否则会报异常
protected void reduce(IntPair key, Iterable<NullWritable> values, Reducer<IntPair,NullWritable, LongWritable, DoubleWritable>.Context context) throws IOException, InterruptedException {
context.write(new LongWritable(key.getFirst()),new DoubleWritable(key.getSecond()));
}
}
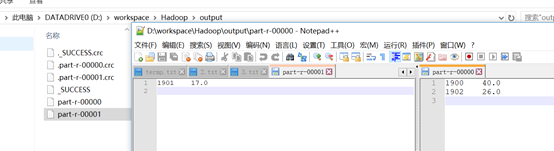
reduce处理之后的的数据结果是
1900 40
1901 17
1902 26
(4)详细的二次排序代码实例
package Temperature;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.File;
import java.io.IOException;
public class MaxTemperatureUsingSecondSort extends Configured implements Tool {
public static class SecondSortMaper extends Mapper<LongWritable, Text, IntPair, NullWritable>
{
@Override
//map的作用是解析记录,得到年和 温度,组成组合键输出
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntPair, NullWritable>.Context context) throws IOException, InterruptedException {
String strValue=value.toString();
String values[]=strValue.split("~");
int year=Integer.parseInt(values[0]);
double temperature=Double.parseDouble(values[1]);
//map输出默认按照键排序,也就是按照FirstSecondPair的CompareTo定义的排序规则排序
context.write(new IntPair(year,temperature),NullWritable.get());
}
}
//按照组合键的第一个字段年份进行分区,让相同年份的数据被同一个分区处理,才能比较出每一年的最高气温
public static class FirstPartitioner extends Partitioner<IntPair,NullWritable>{
@Override
public int getPartition(IntPair intPair, NullWritable nullWritable, int numPartition) {
//numPartition是分区数,根据年份取余得到分区编号,可以保证年份相同记录进入通一个分区,但一个分区内有多个年份的记录。
//例如1900~2000年的数据,numPartition为10,则1900,1910,1930……2000这些取余后都为0,这些年份的记录都会放入分区0,
//需要对分区0中的记录按照年份分组,setGroupingComparatorClass就起到了这个分组的作用,分组后再按温度逆序排序
int partition=(int)(intPair.getFirst()%numPartition);
return partition;
}
}
//一个reduce中有多个年份的数据,按照年份进行分组,分组后在按键进行聚合,年份相同的键都被认为是同一个键,聚合为第一个键,值都是NULL
public static class ReducerGroupingComparator extends WritableComparator
{
public ReducerGroupingComparator()
{
super(IntPair.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
IntPair pairA=(IntPair)a;
IntPair pairB=(IntPair)b;
//年份相同,返回值为0的分为一组
return (int) (pairA.getFirst()-pairB.getFirst());
}
}
//与FirstSecondComparator中定义的默认对比函数功能相同,这个用于显示设置对比类
public static class FirstSecondComparator extends WritableComparator
{
//这里一定要加
public FirstSecondComparator()
{
super(IntPair.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
IntPair pairA=(IntPair)a;
IntPair pairB=(IntPair)b;
int cmp= (int) (pairA.getFirst()-pairA.getFirst());
if (cmp!=0)
{
return cmp;
}
double A=pairA.getSecond();
double B=pairB.getSecond();
return -((A==B)? 0:(A>B? 1:-1));
}
}
//将已经排序、分组、聚合后的数据写入文件,默认按照FirstSecondPair进行排序。
public static class SecondSortReducer extends Reducer<IntPair,NullWritable, LongWritable, DoubleWritable>
{
//Reducer<LongWritable, Text, FirstSecondPair, NullWritable>.Context 一定要这么写,否则会报异常
protected void reduce(IntPair key, Iterable<NullWritable> values, Reducer<IntPair,NullWritable, LongWritable, DoubleWritable>.Context context) throws IOException, InterruptedException {
context.write(new LongWritable(key.getFirst()),new DoubleWritable(key.getSecond()));
}
}
public static class JobBuilder {
public static Job parseInputAndOutput(Tool tool, Configuration conf, String[] args) throws IOException {
if (args.length != 2) {
return null;
}
Job job = null;
try {
job = new Job(conf, tool.getClass().getName());
} catch (IOException e) {
e.printStackTrace();
}
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job;
}
}
public int run(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job =JobBuilder.parseInputAndOutput(this,getConf(),args);
if (job==null)
{
return -1;
}
//设置map和reduce
job.setMapperClass(SecondSortMaper.class);
job.setReducerClass(SecondSortReducer.class);
//显示设置排序类,先按照第一字段年份升序排列,年份相同的按照温度逆序排列。
job.setSortComparatorClass(FirstSecondComparator.class);
//设置分区类,根据年份分区,1990~2000分到10个分区,每个分区10年的数据
job.setMapOutputKeyClass(IntPair.class);
job.setMapOutputValueClass(NullWritable.class);
job.setPartitionerClass(FirstPartitioner.class);
//需要将每个分区中的10年的数据按照年份进行分组,每组的第一个值就是这一年的最高气温
job.setGroupingComparatorClass(ReducerGroupingComparator.class);
job.setOutputKeyClass(IntPair.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(2);
//删除结果目录,重新生成
FileUtil.fullyDelete(new File(args[1]));
// solve the Result, Put, KeyValue Serialization
// job.getConfiguration().setStrings("io.serializations", job.getConfiguration().get("io.serializations"), FirstSecondPair.class.getName());
return job.waitForCompletion(true)? 0:1;
}
public static void main(String[] args) throws Exception
{
int exitCode= ToolRunner.run(new MaxTemperatureUsingSecondSort(),args);
System.exit(exitCode);
}
}
执行作业的hadoop命令, -secondsort表示二次排序
%hadoop jar hadoop-example.jar MaxTemperatureUsingSecondSort input/ncdc/all output –secondsort
查看结果的命令
%hadoop fs –cat output –secondarysort/part-* | sort | head
或者在idea中直接调试,在程序的src同级目录下创建文件夹input

将上面实例中的三组数据写入input/sencondSort文件夹中
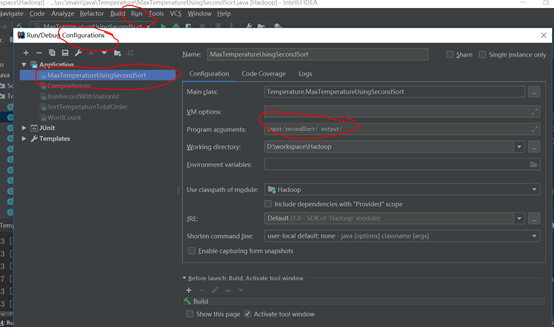
在run->edit Cnfiguration选中这个类,设置输入路径,输出路径
点击运行程序就可以在output路径看到输出结果
参考文献:
https://blog.csdn.net/sinat_32329183/article/details/73741880