这里先说两个概念:1、堆(heap)2、栈(stack)
堆 是堆内存的简称。
栈 是栈内存的简称。
说到堆栈,我们讲的就是内存的使用和分配了,没有寄存器的事,也没有硬盘的事。
各种语言在处理堆栈的原理上都大同小异。堆是动态分配内存,内存大小不一,也不会自动释放。栈是自动分配相对固定大小的内存空间,并由系统自动释放。
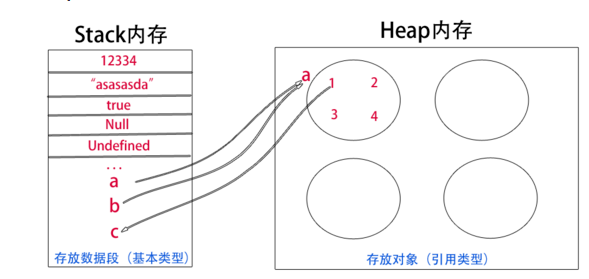
javascript的基本类型就5种:Undefined、Null、Boolean、Number和String,它们都是直接按值存储在栈中的,每种类型的数据占用的内存空间的大小是确定的,并由系统自动分配和自动释放。这样带来的好处就是,内存可以及时得到回收,相对于堆来说,更加容易管理内存空间。
javascript中其他类型的数据被称为引用类型的数据 : 如对象(Object)、数组(Array)、函数(Function) …,它们是通过拷贝和new出来的,这样的数据存储于堆中。其实,说存储于堆中,也不太准确,因为,引用类型的数据的地址指针是存储于栈中的,当我们想要访问引用类型的值的时候,需要先从栈中获得对象的地址指针,然后,在通过地址指针找到堆中的所需要的数据。
说来也是形象,栈,线性结构,后进先出,便于管理。堆,一个混沌,杂乱无章,方便存储和开辟内存空间
传值与传址

上方例子得知,当我改变arr2中的数据时,arr1中数据也发生了变化,当改变str1的数据值时,arr1却没有发生改变。为什么?这就是传值与传址的区别。
因为arr1是数组,属于引用类型,所以它赋予给arr2的时候传的是栈中的地址(相当于新建了一个不同名“指针”),而不是堆内存中的对象的值。str1得到的是一个基本类型的赋值,因此,str1仅仅是从arr1堆内存中获取了一个数值,并直接保存在栈中。arr1、arr2都指向同一块堆内存,arr2修改的堆内存的时候,也就会影响到arr1,str1是直接在栈中修改,并且不能影响到arr1堆内存中的数据。
浅拷贝和深拷贝
上边说到的赋值方式就是浅拷贝,那么什么叫作深拷贝呢?就是要将arr1的每个基本类型的数据都遍历一遍,依次的赋值给arr2的对应字段。避免产生因为地址引用带来的问题。

javascript面向对象的语言本身在处理对象和非对象上就进行了划分,从数据结构的角度来讲,对象就是栈的指针和堆中的数值。