RDD为什么会出现?
- MapReduce 执行迭代计算任务

多个 MapReduce 任务之间没有基于内存的数据共享方式, 只能通过磁盘来进行共享,这种方式明显比较低效
- RDD执行迭代计算任务

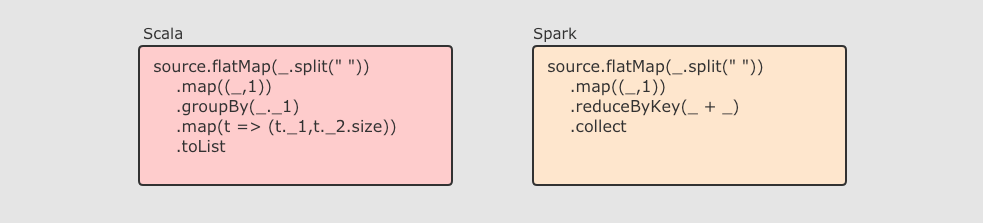
在 Spark 中, 最终 Job3 从逻辑上的计算过程是: Job3 = (Job1.map).filter, 整个过程是共享内存的, 而不需要将中间结果存放在可靠的分布式文件系统中。这种方式可以在保证容错的前提下, 提供更多的灵活, 更快的执行速度, RDD 在执行迭代型任务时候的表现可以通过下面代码体现
// 线性回归 val points = sc.textFile(...) .map(...) .persist(...) val w = randomValue for (i <- 1 to 10000) { val gradient = points.map(p => p.x * (1 / (1 + exp(-p.y * (w dot p.x))) - 1) * p.y) .reduce(_ + _) w -= gradient }
在这个例子中, 进行了大致 10000 次迭代, 如果在 MapReduce 中实现, 可能需要运行很多 Job, 每个 Job 之间都要通过 HDFS 共享结果, 熟快熟慢一窥便知
RDD特点
RDD 不仅是数据集, 也是编程模型
RDD 即是一种数据结构, 同时也提供了上层 API, 同时 RDD 的 API 和 Scala 中对集合运算的 API 非常类似, 同样也都是各种算子
RDD 的算子大致分为两类:
-
Transformation 转换操作, 例如
mapflatMapfilter等 -
Action 动作操作, 例如
reducecollectshow等
执行 RDD 的时候, 在执行到转换操作的时候, 并不会立刻执行, 直到遇见了 Action 操作, 才会触发真正的执行, 这个特点叫做 惰性求值
RDD 可以分区
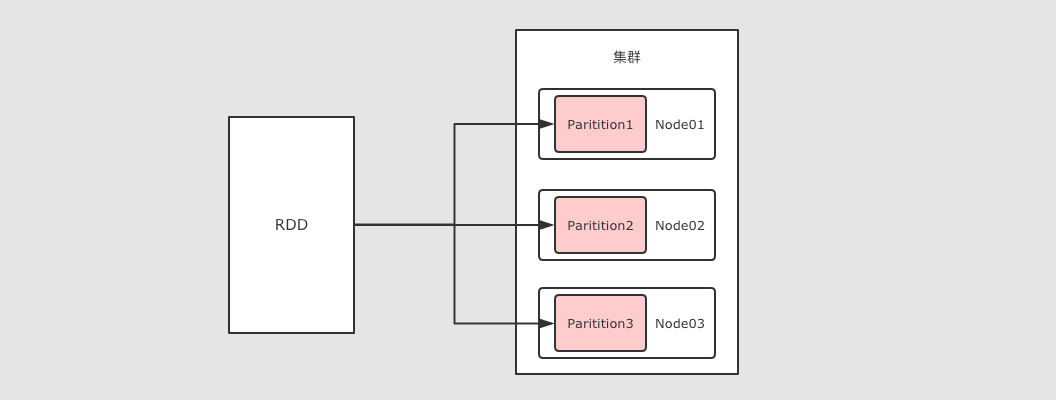
RDD 是一个分布式计算框架, 所以, 一定是要能够进行分区计算的, 只有分区了, 才能利用集群的并行计算能力
同时, RDD 不需要始终被具体化, 也就是说: RDD 中可以没有数据, 只要有足够的信息知道自己是从谁计算得来的就可以, 这是一种非常高效的容错方式
RDD 是只读的
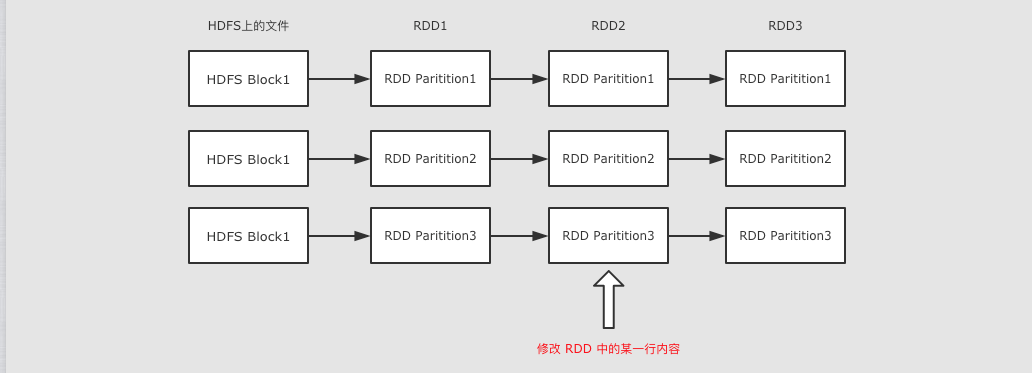
RDD 是只读的, 不允许任何形式的修改. 虽说不能因为 RDD 和 HDFS 是只读的, 就认为分布式存储系统必须设计为只读的. 但是设计为只读的, 会显著降低问题的复杂度, 因为 RDD 需要可以容错, 可以惰性求值, 可以移动计算, 所以很难支持修改.
-
RDD2 中可能没有数据, 只是保留了依赖关系和计算函数, 那修改啥?
-
如果因为支持修改, 而必须保存数据的话, 怎么容错?
-
如果允许修改, 如何定位要修改的那一行? RDD 的转换是粗粒度的, 也就是说, RDD 并不感知具体每一行在哪.
RDD 是可以容错的

- RDD 的容错有两种方式
- 保存 RDD 之间的依赖关系, 以及计算函数, 出现错误重新计算
- 直接将 RDD 的数据存放在外部存储系统, 出现错误直接读取, Checkpoint
什么叫弹性分布式数据集
分布式
RDD 支持分区, 可以运行在集群中
弹性
-
RDD 支持高效的容错
-
RDD 中的数据即可以缓存在内存中, 也可以缓存在磁盘中, 也可以缓存在外部存储中
数据集
-
RDD 可以不保存具体数据, 只保留创建自己的必备信息, 例如依赖和计算函数
-
RDD 也可以缓存起来, 相当于存储具体数据
RDD的算子
分类
RDD 中的算子从功能上分为两大类
-
Transformation(转换) 它会在一个已经存在的 RDD 上创建一个新的 RDD, 将旧的 RDD 的数据转换为另外一种形式后放入新的 RDD
-
Action(动作) 执行各个分区的计算任务, 将的到的结果返回到 Driver 中
RDD 中可以存放各种类型的数据, 那么对于不同类型的数据, RDD 又可以分为三类
-
针对基础类型(例如 String)处理的普通算子
-
针对
Key-Value数据处理的byKey算子 -
针对数字类型数据处理的计算算子
特点
-
Spark 中所有的 Transformations 是 Lazy(惰性) 的, 它们不会立即执行获得结果. 相反, 它们只会记录在数据集上要应用的操作. 只有当需要返回结果给 Driver 时, 才会执行这些操作, 通过 DAGScheduler 和 TaskScheduler 分发到集群中运行, 这个特性叫做 惰性求值
-
默认情况下, 每一个 Action 运行的时候, 其所关联的所有 Transformation RDD 都会重新计算, 但是也可以使用
presist方法将 RDD 持久化到磁盘或者内存中. 这个时候为了下次可以更快的访问, 会把数据保存到集群上
Transformations (转换)算子
map(T ⇒ U)
sc.parallelize(Seq(1, 2, 3)) .map( num => num * 10 ) .collect()

作用:把 RDD 中的数据 一对一 的转为另一种形式
调用:def map[U: ClassTag](f: T ⇒ U): RDD[U]
参数:f → Map 算子是 原RDD → 新RDD 的过程, 传入函数的参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据
flatMap(T ⇒ List[U])
sc.parallelize(Seq("Hello lily", "Hello lucy", "Hello tim"))
.flatMap( line => line.split(" ") )
.collect()
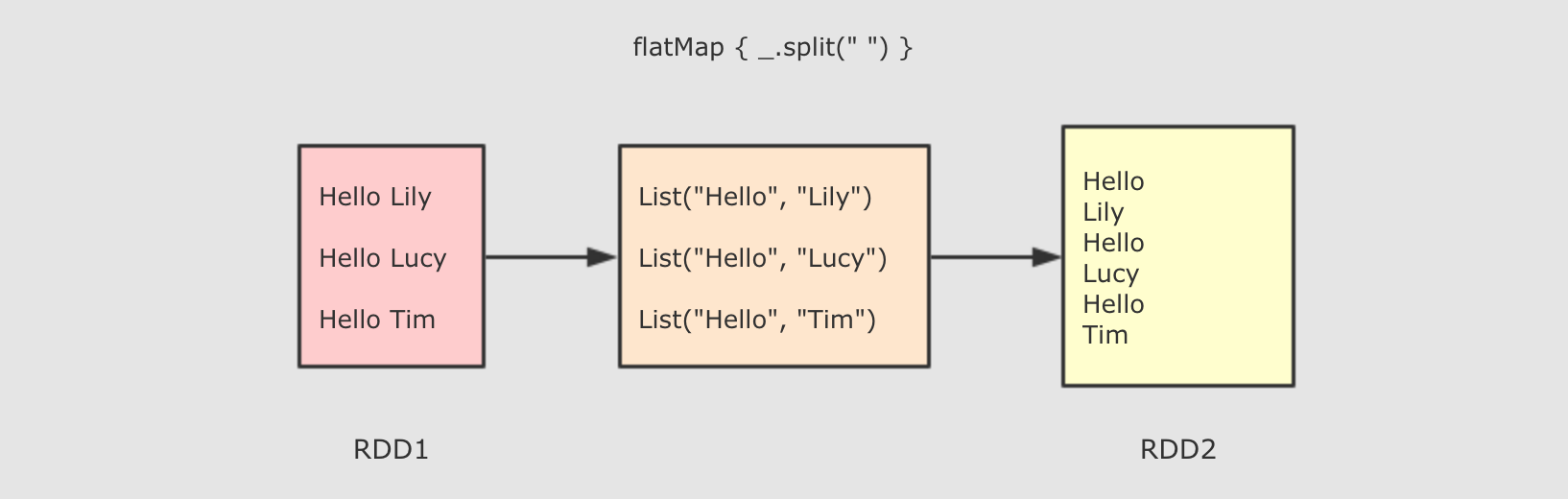
作用:FlatMap 算子和 Map 算子类似, 但是 FlatMap 是一对多
调用:def flatMap[U: ClassTag](f: T ⇒ List[U]): RDD[U]
参数:f → 参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据, 需要注意的是返回值是一个集合, 集合中的数据会被展平后再放入新的 RDD
filter(T ⇒ Boolean)
sc.parallelize(Seq(1, 2, 3)) .filter( value => value >= 3 ) .collect()
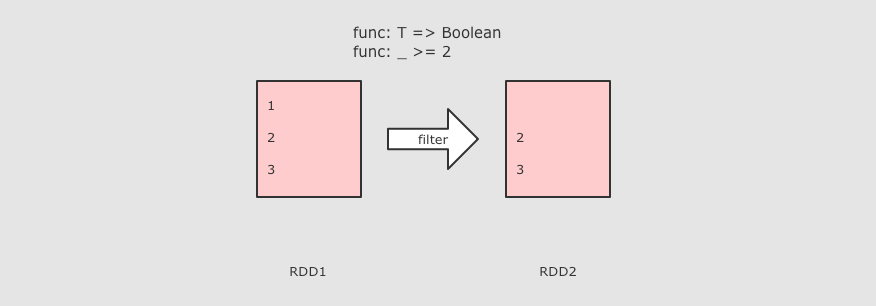
作用:Filter 算子的主要作用是过滤掉不需要的内容
mapPartitions(List[T] ⇒ List[U])
sc.parallelize(Seq(1,2,3,4,5,6),2) .mapPartitions(iter => { iter.map(iter => iter*10) }) .collect()
作用:和 map 类似, 但是针对整个分区的数据转换
mapPartitionsWithIndex
sc.parallelize(Seq(1,2,3,4,5,6),2) .mapPartitionsWithIndex((index,iter) =>{ println("index: "+index) iter.foreach(iter => println(iter)) iter }) .collect()
作用:和 mapPartitions 类似, 只是在函数中增加了分区的 Index
mapValues
sc.parallelize(Seq(("a", 1), ("b", 2), ("c", 3)))
.mapValues( value => value * 10 )
.collect()
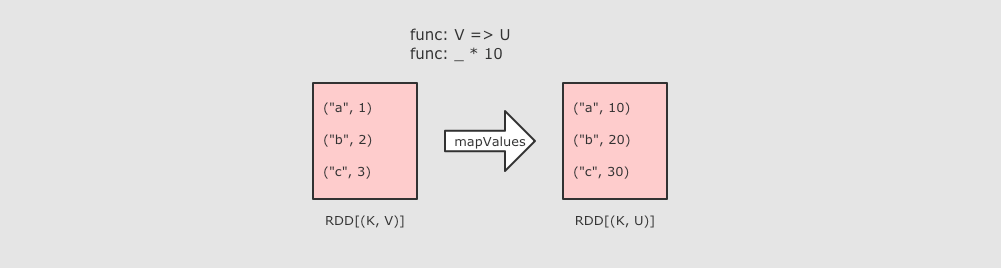
作用:MapValues 只能作用于 Key-Value 型数据, 和 Map 类似, 也是使用函数按照转换数据, 不同点是 MapValues 只转换 Key-Value 中的 Value
sample(withReplacement, fraction, seed)
sc.parallelize(Seq(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)) .sample(withReplacement = true, 0.6, 2) .collect()
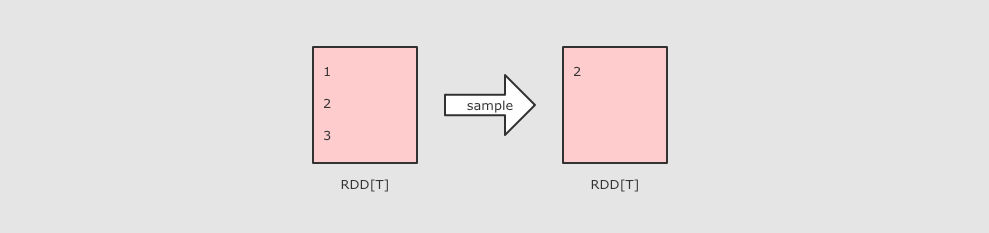
作用:Sample 算子可以从一个数据集中抽样出来一部分, 常用作于减小数据集以保证运行速度, 并且尽可能少规律的损失
参数:
-
withReplacement, 意为取样后是否放回原数据集供下次使用
-
fraction, 意为抽样的比例
-
seed, 随机数种子, 用于 Sample 内部随机生成下标, 一般不指定, 使用默认值
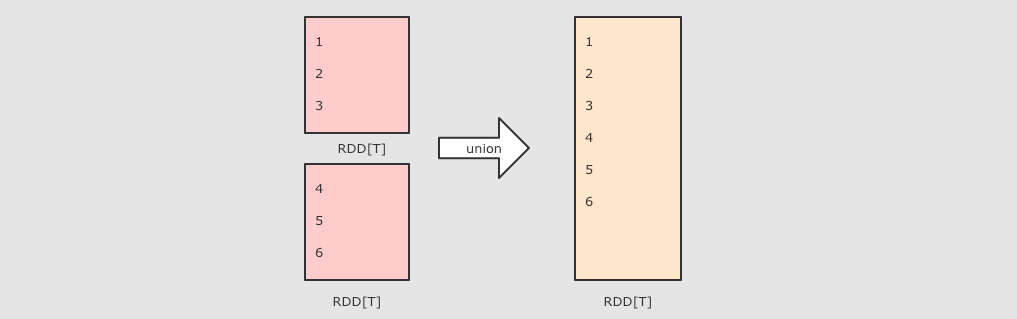
union(other) 并集
val rdd1 = sc.parallelize(Seq(1, 2, 3)) val rdd2 = sc.parallelize(Seq(4, 5, 6)) rdd1.union(rdd2) .collect()
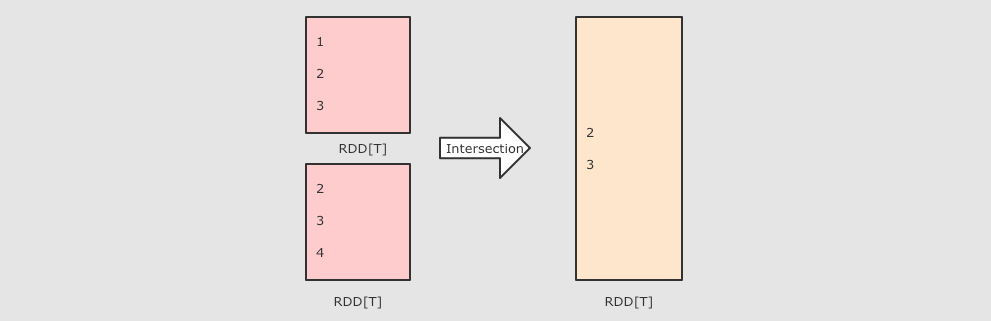
intersection(other) 交集
val rdd1 = sc.parallelize(Seq(1, 2, 3, 4, 5)) val rdd2 = sc.parallelize(Seq(4, 5, 6, 7, 8)) rdd1.intersection(rdd2) .collect()
subtract(other, numPartitions) 差集
val rdd1=sc.parallelize(Seq(1,2,3,4,5)) val rdd2=sc.parallelize(Seq(3,4,5,6,7)) rdd1.subtract(rdd2) .collect()
distinct(numPartitions)
sc.parallelize(Seq(1, 1, 2, 2, 3))
.distinct()
.collect()

作用:去重
reduceByKey((V, V) ⇒ V, numPartition)
sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1)))
.reduceByKey( (curr, agg) => curr + agg )
.collect()

作用:按照 Key 分组生成一个 Tuple, 然后针对每个组执行 reduce 算子
参数:执行数据处理的函数, 传入两个参数, 一个是当前值, 一个是局部汇总, 这个函数需要有一个输出, 输出就是这个 Key 的汇总结果
groupByKey()
sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1)))
.groupByKey()
.collect()
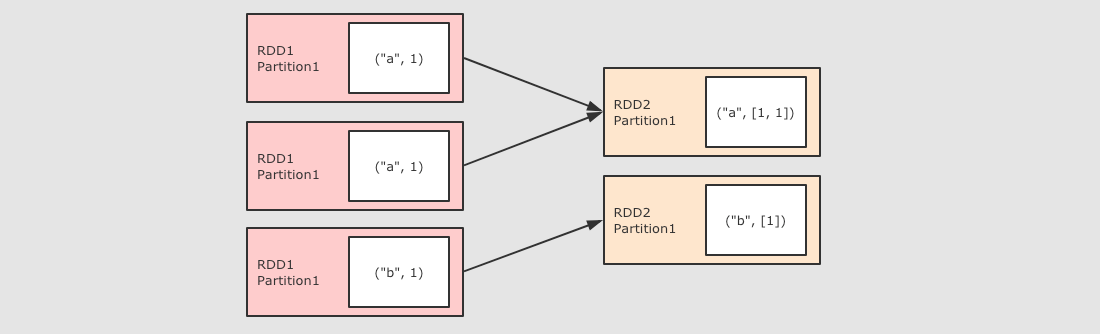
作用:按照 Key 分组, 和 ReduceByKey 有点类似, 但是 GroupByKey 并不求聚合, 只是列举 Key 对应的所有 Value
combineByKey()
val rdd=sc.parallelize(Seq( ("zhangsan", 99.0), ("zhangsan", 96.0), ("lisi", 97.0), ("lisi", 98.0), ("zhangsan", 97.0) )) //算子运算 // 1 createCombiner 转换数据 // 2 mergeValue 分区上的聚合 // 3 mergeCombiners 把所有分区上的结果再次聚合,生成最终结果 val combineResult = rdd.combineByKey( createCombiner = (curr: Double) => (curr, 1), mergeValue = (curr: (Double, Int), nextValue: Double) => (curr._1 + nextValue, curr._2 + 1), mergeCombiners = (curr: (Double, Int), agg: (Double, Int)) => (curr._1 + agg._1, curr._2 + agg._2) ) val resultRDD = combineResult.map(item => (item._1, item._2._1 / item._2._2)) resultRDD.collect().foreach(print(_))
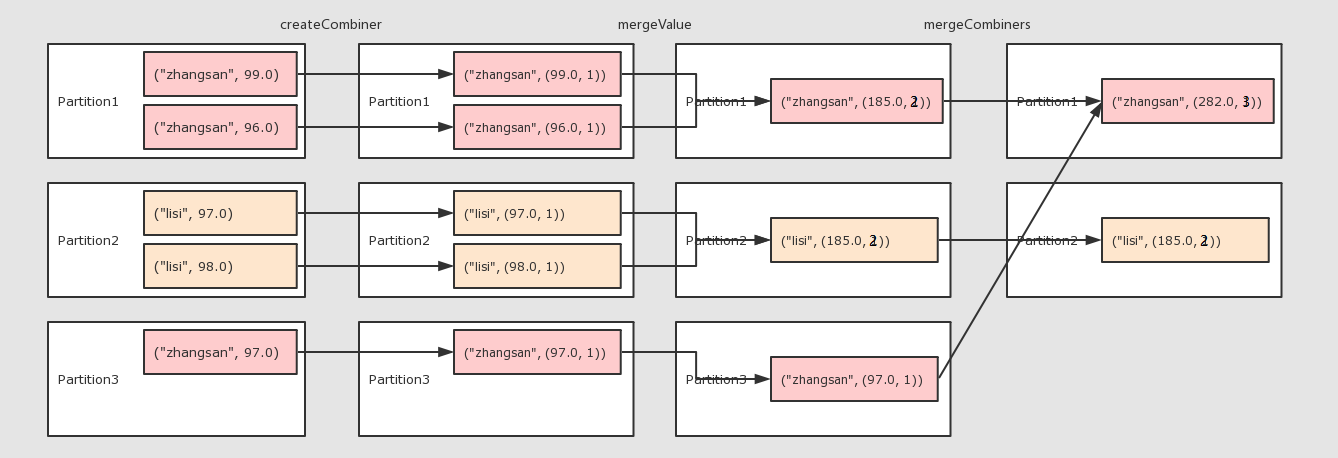
作用:对数据集按照 Key 进行聚合
调用:combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner], [mapSideCombiner], [serializer])
参数:
-
createCombiner将 Value 进行初步转换 -
mergeValue在每个分区把上一步转换的结果聚合 -
mergeCombiners在所有分区上把每个分区的聚合结果聚合 -
partitioner可选, 分区函数 -
mapSideCombiner可选, 是否在 Map 端 Combine -
serializer序列化器
aggregateByKey()
val rdd=sc.parallelize(Seq(("手机",10.0),("手机",15.0),("电脑",20.0)))
rdd.aggregateByKey(0.8)(( zeroValue,item) =>item * zeroValue,(curr,agg) => curr+agg)
.collect()
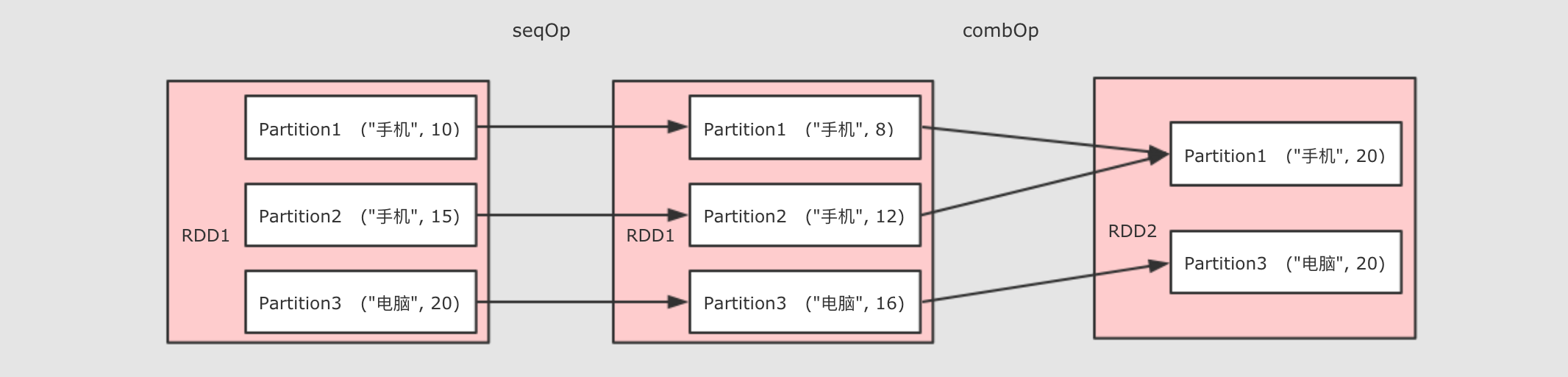
作用:聚合所有 Key 相同的 Value, 换句话说, 按照 Key 聚合 Value
调用:aggregateByKey(zeroValue)(seqOp, combOp)
参数:
-
zeroValue初始值 -
seqOp转换每一个值的函数 -
comboOp将转换过的值聚合的函数
foldByKey(zeroValue)((V, V) ⇒ V)
sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1)))
.foldByKey(zeroValue = 10)( (curr, agg) => curr + agg )
.collect()
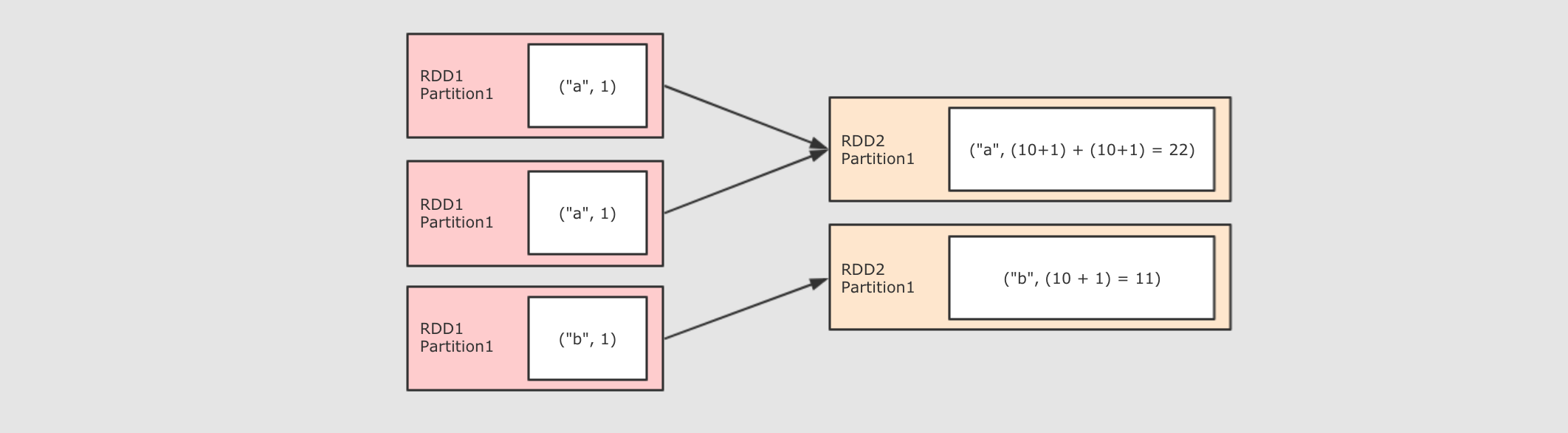
作用:和 ReduceByKey 是一样的, 都是按照 Key 做分组去求聚合, 但是 FoldByKey 的不同点在于可以指定初始值
调用:foldByKey(zeroValue)(func)
参数:
-
zeroValue初始值 -
funcseqOp 和 combOp 相同, 都是这个参数
join(other, numPartitions)
val rdd1 = sc.parallelize(Seq(("a", 1), ("a", 2), ("b", 1)))
val rdd2 = sc.parallelize(Seq(("a", 10), ("a", 11), ("a", 12)))
rdd1.join(rdd2).collect()
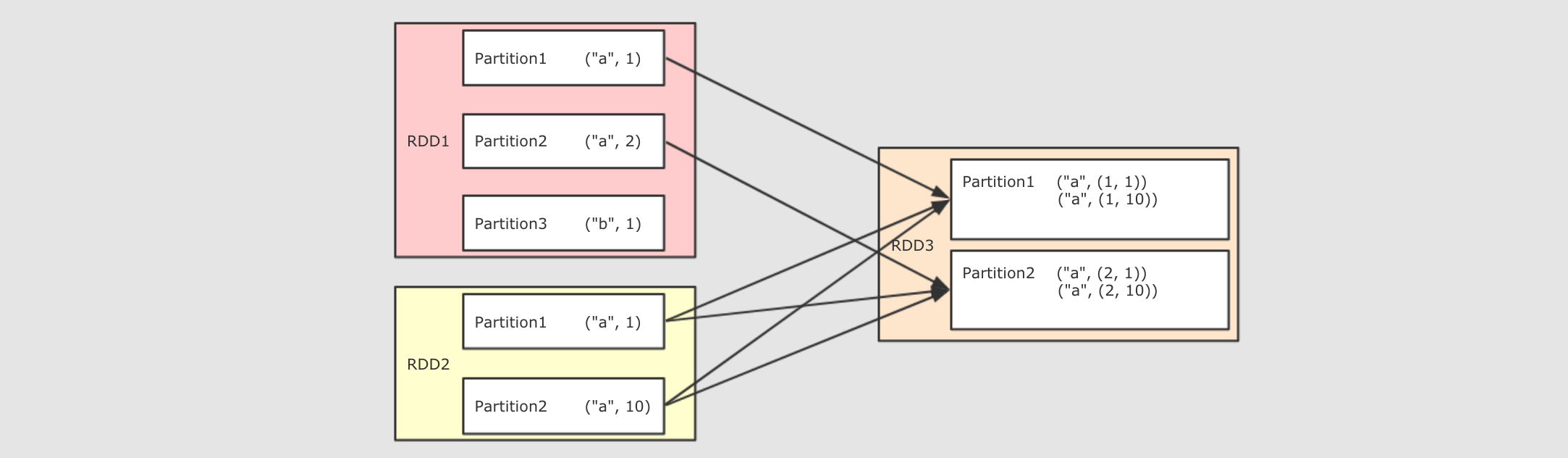
作用:将两个 RDD 按照相同的 Key 进行连接
调用:join(other, [partitioner or numPartitions])
参数:
-
other其它 RDD -
partitioner or numPartitions可选, 可以通过传递分区函数或者分区数量来改变分区
cogroup(other, numPartitions)
val rdd1 = sc.parallelize(Seq(("a", 1), ("a", 2), ("a", 5), ("b", 2), ("b", 6), ("c", 3), ("d", 2)))
val rdd2 = sc.parallelize(Seq(("a", 10), ("b", 1), ("d", 3)))
val rdd3 = sc.parallelize(Seq(("b", 10), ("a", 1)))
val result1 = rdd1.cogroup(rdd2).collect()
val result2 = rdd1.cogroup(rdd2, rdd3).collect()
/*
执行结果:
Array(
(d,(CompactBuffer(2),CompactBuffer(3))),
(a,(CompactBuffer(1, 2, 5),CompactBuffer(10))),
(b,(CompactBuffer(2, 6),CompactBuffer(1))),
(c,(CompactBuffer(3),CompactBuffer()))
)
*/
println(result1)
/*
执行结果:
Array(
(d,(CompactBuffer(2),CompactBuffer(3),CompactBuffer())),
(a,(CompactBuffer(1, 2, 5),CompactBuffer(10),CompactBuffer(1))),
(b,(CompactBuffer(2, 6),CompactBuffer(1),Co...
*/
println(result2)
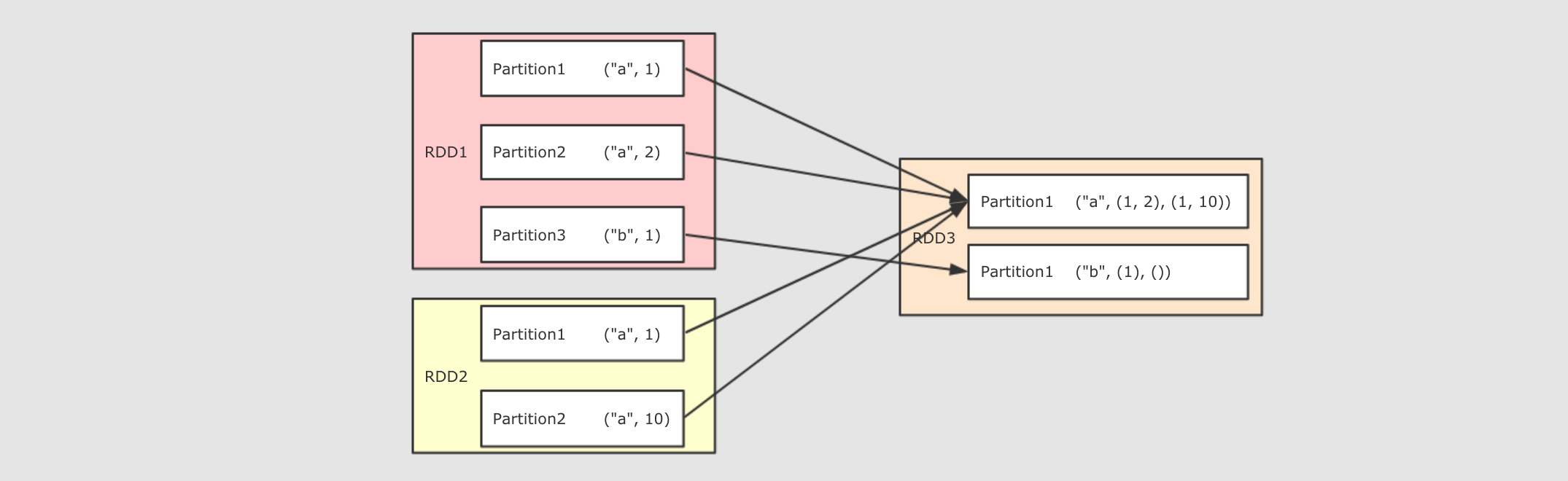
作用:多个 RDD 协同分组, 将多个 RDD 中 Key 相同的 Value 分组
调用:cogroup(rdd1, rdd2, rdd3, [partitioner or numPartitions])
参数:
-
rdd…最多可以传三个 RDD 进去, 加上调用者, 可以为四个 RDD 协同分组 -
partitioner or numPartitions可选, 可以通过传递分区函数或者分区数来改变分区
sortBy(ascending, numPartitions)
val rdd1 = sc.parallelize(Seq(("a", 3), ("b", 2), ("c", 1)))
val sortByResult = rdd1.sortBy( item => item._2 ).collect()
val sortByKeyResult = rdd1.sortByKey().collect()
作用:排序相关相关的算子有两个, 一个是`sortBy`, 另外一个是`sortByKey`
调用:sortBy(func, ascending, numPartitions)
参数:
-
`func`通过这个函数返回要排序的字段
-
`ascending`是否升序
-
`numPartitions`分区数
partitionBy(partitioner) coalesce(numPartitions)
val rdd=sc.parallelize(Seq(1,2,3,4,5),2) println((rdd.repartition(5)).partitions.size) println(rdd.coalesce(5,true).partitions.size)
作用:一般涉及到分区操作的算子常见的有两个, repartitioin 和 coalesce, 两个算子都可以调大或者调小分区数量
调用:
-
repartitioin(numPartitions) -
coalesce(numPartitions, shuffle)
参数:
-
numPartitions新的分区数 -
shuffle是否 shuffle, 如果新的分区数量比原分区数大, 必须 Shuffled, 否则重分区无效