一、MyBatis介绍
MyBatis本是apache的一个开源项目iBatis,2010年这个项目由apache software foundation迁移到了google code,并且改名为MyBatis。2013年11月迁移到Github。MyBatis是一个优秀的持久层框架,它对JDBC的操作数据库的过程进行了封装,使开发者只需要关注SQL本身,而不需要花费精力去处理例如注册驱动、创建Connection、创建Statement、手动设置参数、结果集检索等JDBC繁杂的过程代码了。
MyBatis通过xml或注解的方式将要执行的各种Statement(Statement、PreparedStatemnt、CallableStatement)配置起来,并通过Java对象和Statement中的SQL进行映射生成最终执行的SQL语句,最后由MyBatis框架执行SQL语句并将结果映射成Java对象并返回。
二、MyBatis框架的架构
MyBatis框架的架构如下图所示。
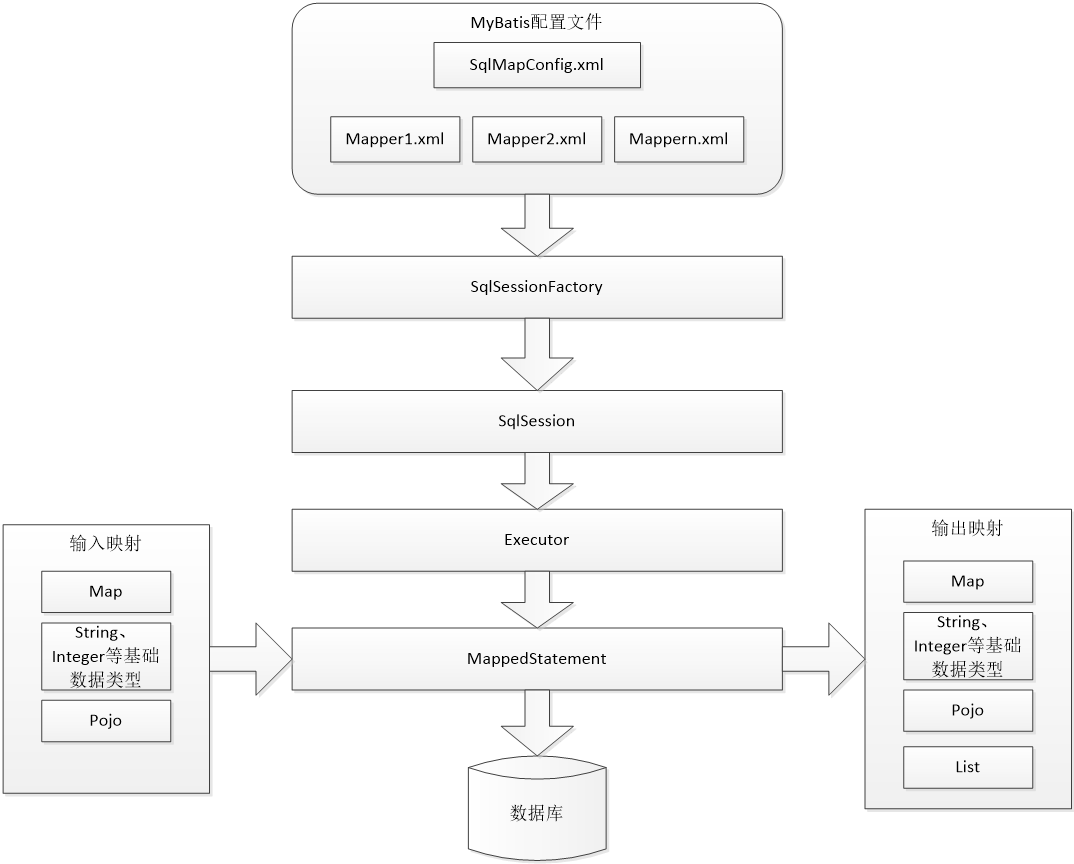
- SqlMapConfig.xml,此文件作为MyBatis的全局配置文件,配置了MyBatis的运行环境等信息。mapper.xml文件即SQL映射文件,文件中配置了操作数据库的SQL语句,此文件需要在SqlMapConfig.xml文件中进行加载;
- 通过MyBatis环境等配置信息构造SqlSessionFactory(即会话工厂);
- 由会话工厂创建SqlSession(即会话),操作数据库需要通过SqlSession;
- MyBatis底层自定义了Executor执行器接口操作数据库,Executor接口有两个实现,一个是基本执行器、一个是缓存执行器;
- MappedStatement也是MyBatis一个底层封装对象,它包装了MyBatis配置信息以及SQL映射信息等。mapper.xml文件中一个SQL对应一个MappedStatement对象,SQL的id即是MappedStatement对象的id;
- MappedStatement对象对SQL执行输入参数进行定义,包括HashMap、基本类型、pojo,Executor通过该对象在执行SQL前将输入的Java对象映射至该SQL中,输入参数映射就是JDBC编程中对PreparedStatement对象设置参数;
- MappedStatement对象对SQL执行输出结果进行定义,包括HashMap、基本类型、pojo,Executor通过该对象在执行SQL后将输出结果映射至Java对象中,输出结果映射过程相当于JDBC编程中对结果集的解析处理过程。
在这里,我们必须明确一点的就是,MyBatis框架默认使用log4j来输出日志信息。
SqlMapConfig.xml是MyBatis框架的核心配置文件,以上文件的配置内容为数据源、事务管理。温馨提示:等后面MyBatis和Spring两个框架整合之后,environments的配置将被废除。
根据用户id查询用户信息
首先,在user.xml映射文件中添加如下配置:
<select id="getUserById" parameterType="int" resultType="com.jdbc.pojo.User"> select * from user where id=#{id} </select>
针对以上<select>标签的配置,我觉得有必要说明如下几点:
- id:表示SQL语句的id,即SQL语句的唯一标识;
- parameterType:查询参数(入参)的数据类型,即定义输入到SQL语句中的映射类型;
- resultType:查询结果的数据类型,若是pojo则应该给出全路径。如果查询结果返回的是List集合,那么resultType属性的值只需要设置为List集合中的一个元素的数据类型即可。
还有一点需要说明,SQL语句中的#{id2}表示使用PreparedStatement设置占位符号并将输入变量id2传到SQL语句中。说得直白点,#{}就是一个占位符,相当于JDBC中的?,如果入参为普通数据类型,例如Integer、String等,那么{}内部就可以随便写了!
${}表示字符串替换:${value}表示使用参数将${value}替换,做字符串的拼接,${}为字符串拼接指令。温馨提示:如果是取简单数据类型的参数,括号中的值必须为value。
#{}和${}
#{}表示一个占位符号,可以很好地去避免SQL注入。其原理是将占位符位置的整个参数和SQL语句两部分提交给数据库,数据库去执行SQL语句,去表中匹配所有的记录是否和整个参数一致。

${}表示一个SQL拼接符号,其原理是在向数据库发出SQL语句之前去拼接好SQL语句再提交给数据库执行。

一般情况下建议使用#{},只有在特殊情况下才必须要用到${},比如:
- 动态拼接SQL中动态组成排序字段,要通过
${}将排序字段传入SQL中; - 动态拼接SQL中动态组成表名,要通过
${}将表名传入SQL中。
parameterType和resultType

使用SqlSession对象中的selectOne方法可以查询一条记录,但如果使用selectOne方法查询多条记录则会抛出如下异常,selectList()可以查询多条记录。
插入数据:
//手动提交事务(在Mybatis中,事务是默认不提交的) sqlSession.commit();
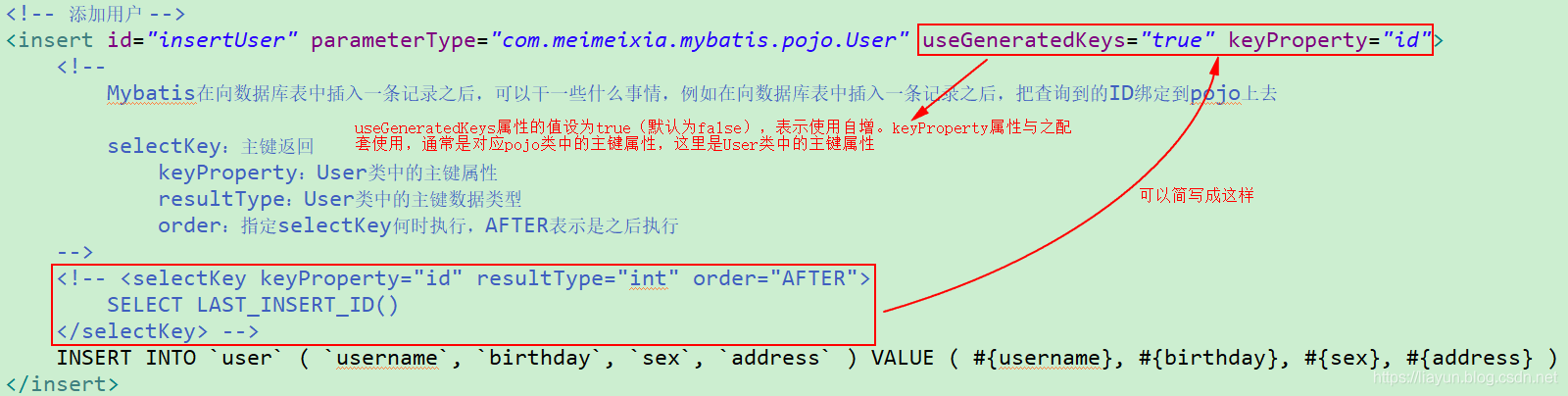
实现主键返回:

针对以上<selectKey>标签的配置,我觉得有必要说明如下几点:
- keyProperty:返回的主键存储在pojo中的哪个属性(即其对应pojo的主键属性)上。获取主键,实际上是将主键取出来之后封装到了pojo的主键属性当中;
- resultType:返回的主键是什么类型(即其对应pojo的主键的数据类型);
- order:selectKey的执行顺序,是相对于insert语句来说的,由于MySQL的自增原理,执行完insert语句之后才将主键生成,所以这里selectKey的执行顺序为AFTER。
其实,user.xml映射文件中的<insert>标签可以简写成下面这个样子,一样可以获取到MySQL自增主键。
在使用UUID算法生成主键时,需要增加通过SELECT UUID()语句得到一个UUID值作为主键。这时,我们可以在user.xml映射文件中添加如下配置。

因为是使用UUID算法生成主键,所以应该先生成主键然后再向数据库中插入数据,此时order属性的值应是BEFORE。

删除与修改较简单。
MyBatis与Hibernate的不同之处
MyBatis和Hibernate不同,它不完全是一个ORM框架,因为MyBatis需要程序员自己编写SQL语句,不过MyBatis可以通过XML或注解方式灵活配置要运行的SQL语句,并将Java对象和SQL语句映射生成最终执行的SQL,最后将SQL执行的结果再映射生成Java对象。
MyBatis学习门槛低,简单易学,程序员直接编写原生态SQL,可严格控制SQL执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,例如互联网软件、企业运营类软件等,因为这类软件需求变化频繁,一但需求变化要求成果输出迅速。但是灵活的前提是MyBatis无法做到数据库无关性,如果需要实现支持多种数据库的软件则需要自定义多套SQL映射文件,工作量大。
Hibernate对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件(例如需求固定的定制化软件),如果用Hibernate开发可以节省很多代码,提高效率。但是Hibernate的学习门槛高,要精通门槛更高,而且怎么设计O/R映射,在性能和对象模型之间如何权衡,以及怎样用好Hibernate需要具有很强的经验和能力才行。
总之,按照用户的需求在有限的资源环境下只要能做出维护性、扩展性良好的软件架构都是好架构,所以框架只有适合才是最好的。
我个人总结的MyBatis与Hibernate这两个框架的不同之处:
- MyBatis是不完全的ORM框架,它学习成本低,入门门槛也低。MyBatis需要程序员自己写SQL,对SQL修改和优化就比较灵活。适用场景:需求变化较快的项目开发,比如互联网项目、电商等;
- Hibernate学习成本高,入门门槛高,Hibernate是ORM框架,不需要程序员编写SQL,自动根据对象映射生成SQL。适用场景:需求固定的中小型项目,如OA系统、ERP系统。
MyBatis常用API的使用范围
在使用MyBatis这个框架开发dao层之前,你应该知道一下MyBatis常用的API。
SqlSessionFactoryBuilder的使用范围
SqlSessionFactoryBuilder用于创建SqlSessionFactory,SqlSessionFactory一旦创建完成就不需要SqlSessionFactoryBuilder了,因为SqlSession是通过SqlSessionFactory生产的,所以可以将SqlSessionFactoryBuilder当成一个工具类使用,最佳使用范围是方法范围(即方法体内局部变量)。
SqlSessionFactory的使用范围
SqlSessionFactory是一个接口,接口中定义了openSession的不同重载方法,SqlSessionFactory的最佳使用范围是整个应用运行期间,一旦创建后可以重复使用,通常以单例模式管理SqlSessionFactory。
SqlSession的使用范围
SqlSession中封装了对数据库的操作,如查询、插入、更新、删除等。通过SqlSessionFactory创建SqlSession,而SqlSessionFactory是通过SqlSessionFactoryBuilder进行创建的。
SqlSession是一个面向程序员的接口,SqlSession中定义了一些数据库操作方法,所以SqlSession作用是操作数据库,并且SqlSession对象要存储数据库连接、事务和一级缓存结构等。
每个线程都应该有它自己的SqlSession实例。SqlSession的实例不能共享使用,它是线程不安全的(多线程访问系统,当多线程同时使用一个SqlSession对象时会造成数据冲突问题)。由于SqlSession对象是线程不安全的,因此它的最佳使用范围是请求或方法范围(也可说为SqlSession的最佳使用场合是在方法体内作为局部变量来使用),绝对不能将SqlSession实例的引用放在一个类的静态字段或实例字段中。
打开一个SqlSession,记得使用完毕就要关闭它。通常会把这个关闭操作放到finally代码块中以确保每次都能执行该关闭操作。
SqlSession session = sqlSessionFactory.openSession(); try { // do work } finally { session.close(); }
原始dao开发方式
原始dao开发方式需要程序员自己编写dao层接口以及其实现类。首先,我们要在工程的src目录下创建一个com.meimeixia.mybatis.dao包,并在该包下编写一个UserDao接口。
然后,再在src目录下创建一个com.meimeixia.mybatis.dao.impl包,在该包下编写以上UserDao接口的一个实现类(即UserDaoImpl.java)。
由于SqlSessionFactory是一个接口,而且接口中定义了openSession的不同重载方法,如下图所示。

(自动提交事务)
从以上UserDaoImpl实现类的代码,可以看出原始dao开发方式存在以下问题:
-
dao层接口实现类的方法中存在着大量的重复代码,这些重复的代码就是模板代码。这些模板代码为:
- 先创建SqlSession
- 再调用SqlSession的方法
- 再提交SqlSession
- 再关闭SqlSession
设想能否将这些代码提取出来,因为这可以大大减轻程序员的工作量。
-
调用SqlSession的数据库操作方法需要指定Statement的id,这里存在硬编码,不便于开发维护。
-
调用SqlSession方法时传入的变量,由于SqlSession方法使用泛型,即使变量类型传入错误,在编译阶段也不会报错,这不利于程序员开发。
于是,下面我将使用mapper代理方法来开发dao层,来解决上面我们所发现的问题。
开发规范
Mapper动态代理开发方式只需要程序员编写Mapper接口(相当于dao层的接口),由MyBatis框架根据接口定义创建接口的动态代理对象,代理对象的方法体与上边dao层接口的实现类方法体相似。注意:Mapper动态代理开发需要遵循以下规范:
- Mapper.xml文件中的namespace与Mapper接口的类路径相同,即namespace必须是接口的全限定名;
- Mapper接口的方法名和Mapper.xml文件中定义的每个Statement的id相同;
- Mapper接口方法的输入参数类型和Mapper.xml文件中定义的每个SQL的parameterType的类型相同;
- Mapper接口方法的输出参数类型和Mapper.xml文件中定义的每个SQL的resultType的类型相同。
只要遵循了以上四个开发规则,那么我们就可以使用Mapper动态代理开发方式来开发dao层了。
编写Mapper.xml(映射文件)
之前,我们在config源码目录下新建了一个mybatis的普通文件夹,该文件夹专门用于存放映射文件。这里,我们可以在该文件夹下创建一个名为UserMapper.xml的映射文件,其内容如下:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- 动态代理开发规则: 1. namespace必须是接口的全路径名 2. 接口的方法名必须与SQL语句的ID一致 3. 接口的入参必须与parameterType类型一致 4. 接口的返回值必须与resultType类型一致 --> <mapper namespace="com.meimeixia.mybatis.mapper.UserMapper"> <!-- id属性即SQL ID,表示SQL语句的唯一标识 parameterType:入参的数据类型 resultType:返回结果的数据类型 --> <select id="getUserById" parameterType="int" resultType="com.meimeixia.mybatis.pojo.User"> SELECT `id`, `username`, `birthday`, `sex`, `address` FROM `user` WHERE id = #{id2} </select> <!-- 如果查询结果返回的是List集合,那么resultType属性的值只需要设置为List集合中的一个元素的数据类型即可 --> <select id="getUserByUserName" parameterType="string" resultType="com.meimeixia.mybatis.pojo.User"> SELECT `id`, `username`, `birthday`, `sex`, `address` FROM `user` WHERE `username` LIKE '%${value}%' </select> <!-- useGeneratedkeys属性的值设为true(默认为false),表示使用自增。keyProperty属性与之配套使用,通常是对应pojo类中的主键属性,这里是User类中的主键属性 --> <insert id="insertUser" parameterType="com.meimeixia.mybatis.pojo.User" useGeneratedKeys="true" keyProperty="id"> INSERT INTO `user` ( `username`, `birthday`, `sex`, `address` ) VALUE ( #{username}, #{birthday}, #{sex}, #{address} ) </insert> </mapper>
编写Mapper接口
在工程的src目录下新建一个com.meimeixia.mybatis.mapper包,并在该包下创建一个Mapper接口,即UserMapper.java。
接口的定义有如下特点:
- Mapper接口的方法名和Mapper.xml文件中定义的Statement的id相同;
- Mapper接口方法的输入参数类型和Mapper.xml文件中定义的Statement的parameterType的类型相同;
- Mapper接口方法的输出参数类型和Mapper.xml文件中定义的Statement的resultType的类型相同。
@Test public void testGetUserByUserName() { SqlSession sqlSession = SqlSessionFactoryUtils.getSqlSessionFactory().openSession(); //获取接口的代理实现类,只不过不需要我们去写了 UserMapper userMapper = sqlSession.getMapper(UserMapper.class); List<User> list = userMapper.getUserByUserName("范"); for (User user : list) { System.out.println(user); } sqlSession.close(); }
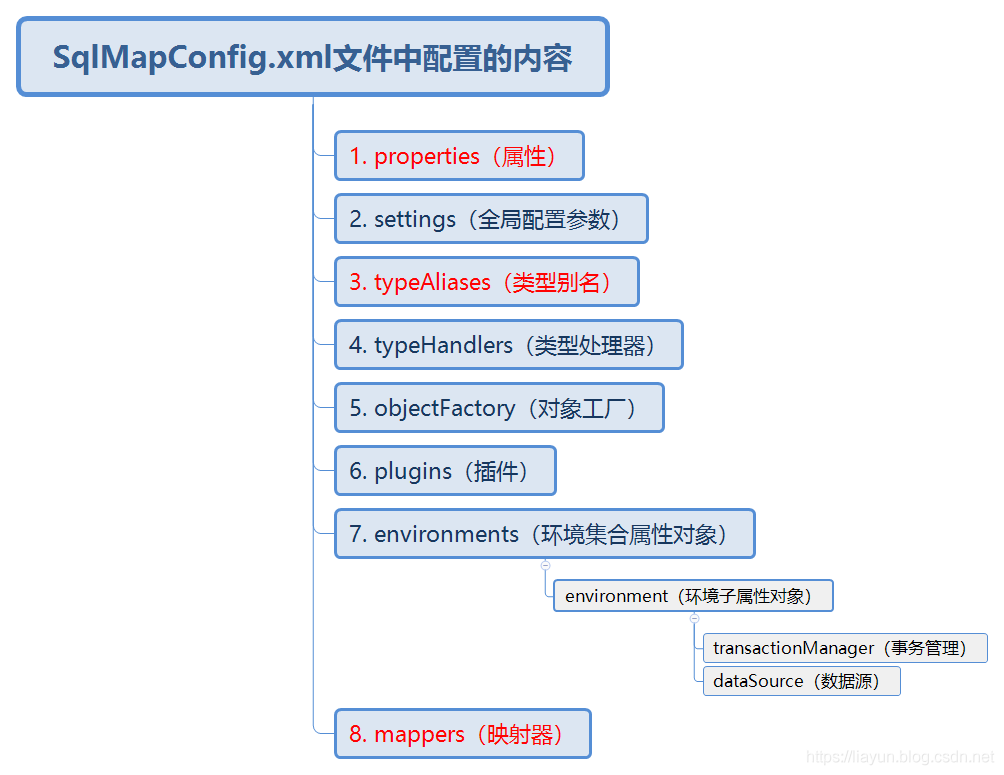
SqlMapConfig.xml文件中配置的内容
SqlMapConfig.xml文件中配置的内容和顺序如下图所示。
properties(属性)
在SqlMapConfig.xml配置文件中,我们可把数据库连接信息配置到properties标签当中,类似如下:
<properties>
<property name="jdbc.username" value="root"/>
<property name="jdbc.password" value="root"/>
</properties>
<!-- 和spring整合后 environments配置将废除, default属性表示使用哪一个环境? -->
<environments default="development">
<environment id="development">
<!-- 使用jdbc事务管理 -->
<transactionManager type="JDBC" />
<!-- 数据库连接池 -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver" />
<property name="url" value="jdbc:mysql:///mybatis?characterEncoding=utf-8&serverTimezone=Asia/Shanghai" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="root" />
</dataSource>
可以引入外部文件配置:
<properties resource="jdbc.properties">
<property name="jdbc.username" value="root"/>
<property name="jdbc.password" value="root"/>
</properties>
注意:MyBatis将按照下面的顺序来加载属性:
- 在properties元素体内定义的属性首先被读取;
- 然后会读取properties元素中resource或url加载的属性,它会覆盖已读取的同名属性。
typeAliases(类型别名)
MyBatis支持别名
MyBatis支持的别名如下列表所示
| 别名 | 映射的类型 |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| map | Map |
给类起别名:
<typeAliases>
<typeAlias type="com.jdbc.pojo.User" alias="user"/>
</typeAliases>
给包下所有类起别名:默认别名为类名字,且不区分大小写
<typeAliases>
<!-- <typeAlias type="com.jdbc.pojo.User" alias="user"/> -->
<package name="com.jdbc.pojo"/>
</typeAliases>
SqlMapConfig.xml文件加载Mapper.xml文件
Mapper(映射器)的配置有如下三种方式:
- 第一种方式:使用
<mapper resource="..." />标签来加载相对于类路径的映射文件。正如下图所示的那样。 - 第二种方式:使用
<mapper class="..." />标签配置映射文件的class扫描器,也就是说加载Mapper接口类路径下的映射文件。正如下图所示的那样。注意:这种方式要求Mapper接口名称和Mapper映射文件名称相同,且放在同一个目录中。 - 第三种方式:使用
<package name="..." />标签配置映射文件包扫描,注册指定包下的所有Mapper接口,也就是说能加载指定包下的所有映射文件了。正如下图所示的那样。
- 注意:这种方式也要求Mapper接口名称和Mapper映射文件名称相同,且放在同一个目录中。
虽然Mapper(映射器)配置有以上三种方式,但是在实际开发中就用第三种方法,其他方式仅做了解就行!
输入映射和输出映射
Mapper.xml映射文件中定义了操作数据库的SQL,每个SQL就是一个Statement,映射文件是MyBatis框架的核心。
parameterType(输入类型)
传递简单类型
传递简单类型,我之前就已经讲过了,这里只给出案例,如下图所示。
<select id="getUserById" parameterType="int" resultType="user"> select * from user where id=#{id} </select>
传递pojo对象
MyBatis会使用OGNL表达式解析对象字段的值,#{}或者${}花括号中的值就是pojo属性名称。传递pojo对象,之前我也讲过了,这里同样只给出案例,如下图所示。

传递pojo包装对象
在实际开发中,通常都可以通过pojo来传递查询条件,这样的查询条件一般是综合的查询条件,不仅包括用户查询条件还包括其它的查询条件(比如将用户购买商品信息也作为查询条件),这时便可以使用包装对象来传递输入参数了,即pojo类中包含pojo类。
(like后的字符串需要加引号)
传递HashMap
传递HashMap在实际开发中用的很少,但我还是要讲一下。以传递HashMap综合查询用户信息为例来说,首先我们要在UserMapper.xml映射文件中添加如下配置信息。
resultType(输出类型)
输出简单类型
有这样一个需求:要查询用户表中的总记录数。返回类型为int时使用Integer(也可以混用)
输出pojo对象
输出pojo对象
有时返回的某一属性为空,很明显这并不是我们所想要的结果。为了达到我们预期的效果,可为user_id这一列加个别名,即将OrderMapper.xml映射文件中id为getOrderList的select元素修改成下面这个样子。

只要你返回的结果的列名和pojo类中的属性名一致,那么就可以自动映射了。这样当我们再次以Debug模式运行testGetOrderList方法时,就能达到我们预期的结果了,如下图所示。
这种为列取别名的方式比较简单粗暴,其实要达到我们所预期的效果,还有另一种方式,那就是使用resultMap这个属性,下面我就会讲到。
resultMap
resultType虽然可以指定将查询结果映射为pojo,但需要pojo的属性名和SQL语句查询的列名一致方可映射成功。如果SQL语句查询字段名和pojo的属性名不一致,那么可以通过resultMap将字段名和属性名作一个对应关系,resultMap实质上还是需要将查询结果映射到pojo对象中。resultMap可以实现将查询结果映射为复杂类型的pojo,比如在查询结果映射对象中包括pojo和List集合就能分别实现一对一查询和一对多查询。
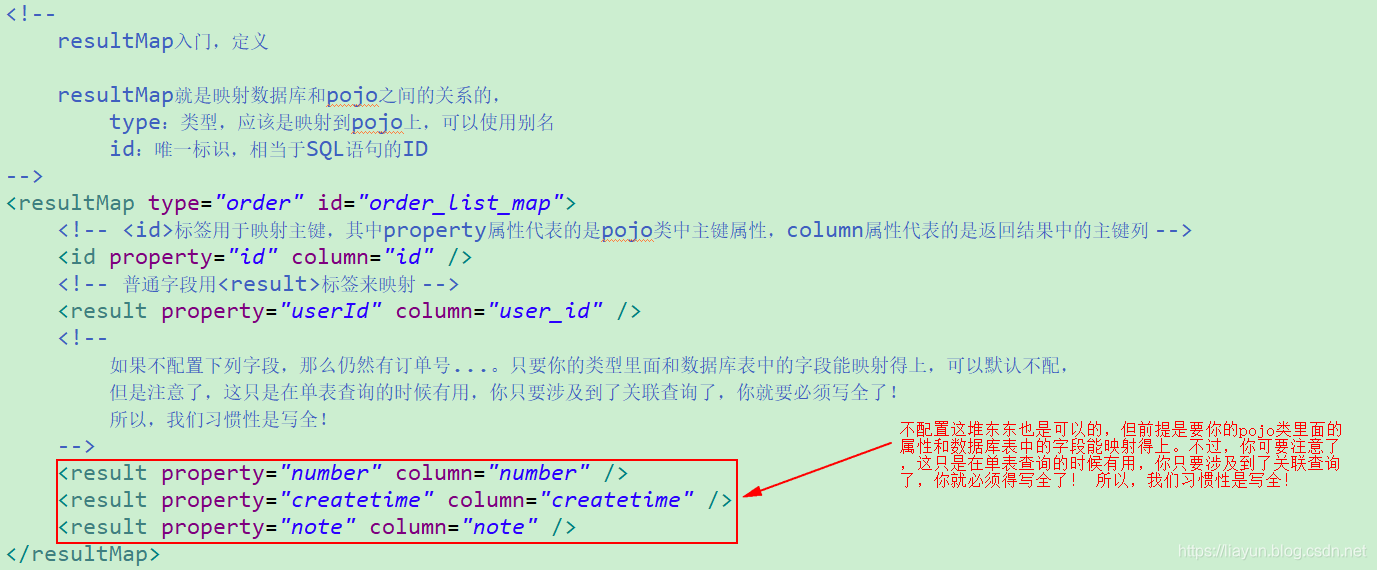
针对以上<resultMap>标签的配置,我觉得有必要说明如下几点:
- type:指resultMap要映射成的数据类型,即返回结果映射的pojo类,可以使用别名;
<id>:此标签表示查询结果集的唯一标识,非常重要。如果是多个字段为复合唯一约束,那么就需要定义多个<id>标签了;<result>:普通列使用result标签映射。id标签与result标签均有如下两个属性:- property:表示Order类中的属性;
- column:表示SQL语句查询出来的字段名。
column和property放在一块儿表示将SQL语句查询出来的字段映射到指定的pojo类属性上。
动态SQL
我们可通过MyBatis提供的各种标签方法实现动态拼接SQL语句。
if
现有这样一个需求:传递pojo类综合查询用户信息,更具体地说就是我们要能使用用户的username和sex更加灵活地查询用户信息。为了解决这个需求,我们就要使用<if>标签了。首先在UserMapper.xml映射文件中添加一个如下<select>元素。
<select id="getUserByPojo" parameterType="user" resultType="user"> select * from user where 1=1 <if test="username!=null and username!=''"> and username like '%${username}%' </if> <if test="sex!=null and sex!=''"> and sex = #{sex} </if> </select>
where
可使用<where>标签改成下面这个样子。
<select id="getUserByPojo" parameterType="user" resultType="com.meimeixia.mybatis.pojo.User"> SELECT `id`, `username`, `birthday`, `sex`, `address` FROM `user` <where> <if test="username != null and username != ''"> and username LIKE '%${username}%' </if> <if test="sex != null and sex != ''"> and sex = #{sex} </if> </where> </select>
<where>标签可以自动补上SQL语句中的where关键字,而且还能处理掉where条件中的第一个and关键字。还有一点需要我们注意,那就是只要用了<where>标签,就不能再手动地加上where关键字了!
foreach
现有这样一个需求:传入多个id查询用户信息。如若编写SQL语句,可用下面两条SQL语句来实现:
SELECT * FROM USER WHERE username LIKE '%张%' AND (id =10 OR id =89 OR id=16)
SELECT * FROM USER WHERE username LIKE '%张%' id IN (10,89,16)
为了解决这个需求,我们可以在QueryVo类中定义一个List集合类型的ids属性存储多个用户id,并为其添加getter/setter方法。
public class QueryVo { private User user; private List<Integer> ids; public User getUser() { return user; } public void setUser(User user) { this.user = user; } public List<Integer> getIds() { return ids; } public void setIds(List<Integer> ids) { this.ids = ids; } }

SQL片段
SQL语句中可将重复的语句给提取出来,使用时用include标签引用即可,最终达到SQL语句重用的目的。例如像下面这样的<select>元素:
我们可以将要查询的字段抽取出来。
<!-- SQL片段的抽取,定义 -->
<sql id="user_sql">
`id`,
`username`,
`birthday`,
`sex`,
`address`
</sql>
然后,使用include标签来引用。
<select id="getUserByIds" parameterType="queryvo" resultType="user"> SELECT <!-- SQL片段的使用,refid引用定义好的SQL片段 --> <include refid="user_sql" /> FROM `user` <where> <!-- <foreach>是一个循环标签 collection指定要遍历的集合 --> <!-- 目的是要输出`id` IN (1,25,29,30)这样子的内容。 open:循环开始之前输出的内容,即循环开始之前输出一段`id` IN (这样的字符串 item:设置循环的变量 separator:循环的分隔符,即以,作为分隔符 close:循环结束之后输出的内容,即循环结束之后输出一个) --> <foreach collection="ids" open="`id` IN (" item="uId" separator="," close=")"> #{uId} </foreach> </where> </select>
注意:如果引用其它映射文件的SQL片段,则需要在引用时需要加上namespace,如下所示。
<include refid="namespace.SQL片段"/>
一对一一对多
一对一查询
有这样一个需求:查询所有订单信息时,关联查询下单的用户信息。
方法一:使用resultType
使用resultType,定义一个订单信息po类,此po类中包括了订单信息和用户信息。于是,我们首先要在com.meimeixia.mybatis.pojo包下新建一个OrderUser类
使用resultType,定义一个订单信息po类,此po类中包括了订单信息和用户信息。于是,我们首先要在com.meimeixia.mybatis.pojo包下新建一个OrderUser类。
public class OrderUser extends Order { private String username;// 用户姓名 private String address;// 地址 public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public String getAddress() { return address; } public void setAddress(String address) { this.address = address; } @Override public String toString() { return "OrderUser [username=" + username + ", address=" + address + ", getId()=" + getId() + ", getUserId()=" + getUserId() + ", getNumber()=" + getNumber() + ", getCreatetime()=" + getCreatetime() + ", getNote()=" + getNote() + "]"; } }
OrderUser类继承Order类之后,自然就包括了Order类中的所有字段,所以在该类中只需要定义用户的信息字段即可。
然后,按照需求编写SQL语句,在OrderMapper.xml映射文件中添加一个如下<select>元素。
<select id="getOrderUser" resultType="orderuser"> SELECT o.`id`, o.`user_id` userId, o.`number`, o.`createtime`, o.`note`, u.username, u.address FROM `order` o LEFT JOIN `user` u ON u.id = o.user_id </select>
小结
定义专门的po类作为输出类型,其中定义了SQL查询结果集所有的字段。此方法较为简单,企业中使用普遍。
方法二:使用resultMap
使用resultMap,定义专门的resultMap用于映射一对一查询结果。首先要在Order类中加入一个User类型的user属性,该属性用于存储关联查询的用户信息,因为订单关联查询用户是一对一关系,所以这里使用单个User对象存储关联查询的用户信息。如此一来,Order类的代码就要改成下面这个样子了。
public class Order { private Integer id; private Integer userId; private String number; private Date createtime; private String note; private User user; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public Integer getUserId() { return userId; } public void setUserId(Integer userId) { this.userId = userId; } public String getNumber() { return number; } public void setNumber(String number) { this.number = number == null ? null : number.trim(); } public Date getCreatetime() { return createtime; } public void setCreatetime(Date createtime) { this.createtime = createtime; } public String getNote() { return note; } public void setNote(String note) { this.note = note == null ? null : note.trim(); } public User getUser() { return user; } public void setUser(User user) { this.user = user; } @Override public String toString() { return "Order [id=" + id + ", userId=" + userId + ", number=" + number + ", createtime=" + createtime + ", note=" + note + "]"; } }
然后,在OrderMapper.xml映射文件中添加一个如下的<select>元素。
<select id="getOrderUserMap" resultMap="order_user_map"> SELECT o.`id`, o.`user_id`, o.`number`, o.`createtime`, o.`note`, u.`username`, u.`address`, u.`birthday`, u.`sex` FROM `order` o LEFT JOIN `user` u ON u.id = o.user_id </select>
上面id为order_user_map的resultMap也须定义,如下所示
<!-- 定义resultMap -->
<resultMap type="order" id="order_user_map">
<!-- <id>用于映射主键 -->
<id property="id" column="id" />
<!-- 普通字段用<result>来映射 -->
<result property="userId" column="user_id" />
<result property="number" column="number" />
<result property="createtime" column="createtime" />
<result property="note" column="note" />
<!--
<association>用于配置一对一关系
property:映射的是Order实体类里面的user属性
javaType:Order实体类里面的user属性的数据类型,可以写成别名
-->
<association property="user" javaType="com.meimeixia.mybatis.pojo.User">
<id property="id" column="user_id" />
<result property="username" column="username" />
<result property="address" column="address" />
<result property="birthday" column="birthday" />
<result property="sex" column="sex" />
</association>
</resultMap>
针对以上<association>标签的配置,我觉得有必要说明如下几点:
- association:该标签表示进行关联查询单条记录,即可以使用它来配置一对一关联关系。
- property:该属性表示的是关联查询的结果要存储在Order实体类里面的user属性中。即它对应Order实体类里面一对一关联映射的那个属性(也就是user属性);
- javaType:该属性表示的是关联查询的结果类型,即user属性的数据类型,可使用别名;
<id property="id" column="user_id"/>:意思是查询结果的user_id列对应关联对象的id属性,这儿的<id>标签表示user_id是关联查询对象的唯一标识;<result property="username" column="username"/>:意思是查询结果的username列对应关联对象的username属性。
一对多关联映射
现有这样一个需求:查询所有用户信息及用户所关联的订单信息。这儿,用户信息和订单信息为一对多关系。此处,我会使用resultMap来解决这个需求。首先在User实体类中加入一个List<Orders> orders属性,如此一来,User类的代码就要改成下面这个样子了。
private Integer id; // int类型的id是不可能为null的! private String username;// 用户姓名 private String sex;// 性别 private Date birthday;// 生日 private String address;// 地址 private String uuid2; private List<Order> orders;
然后,在UserMapper.xml映射文件中添加一个如下的<select>元素。
<select id="getUserOrderMap" resultMap="user_order_map"> SELECT u.`id`, u.`username`, u.`birthday`, u.`sex`, u.`address`, u.`uuid2`, o.`id` oid, o.`number`, o.`createtime`, o.`note` FROM `user` u LEFT JOIN `order` o ON o.`user_id` = u.`id` </select>
上面id为user_order_map的resultMap也须定义,如下所示:
<!-- 定义resultMap -->
<resultMap type="user" id="user_order_map">
<id property="id" column="id" />
<result property="username" column="username" />
<result property="address" column="address" />
<result property="birthday" column="birthday" />
<result property="sex" column="sex" />
<!--
<collection>用于配置一对多关联关系
property:映射的是User实体类里面的orders属性
ofType:User实体类里面的orders属性的数据类型,可以写成别名
-->
<collection property="orders" ofType="order">
<!-- <id>用于映射主键 -->
<id property="id" column="oid" />
<result property="userId" column="id" />
<result property="number" column="number" />
<result property="createtime" column="createtime" />
<result property="note" column="note" />
</collection>
</resultMap>
针对以上<collection>标签的配置,我觉得有必要说明如下几点:
<collection>标签部分定义了用户关联的订单信息,即它表示关联查询结果集。- property:该属性表示关联查询的结果集存储在User对象的哪个属性上,也就是说它对应的是User对象中的集合属性;
- ofType:该属性指定关联查询的结果集中的对象类型(即List集合中的元素类型)。此处可以使用别名,也可以使用全限定名;
<id>标签及<result>标签的意义同一对一查询。
整合Spring
整合思路
MyBatis整合Spring的思路如下:
- SqlSessionFactory对象应该放到Spring容器中作为单例存在;
- 传统dao的开发方式中,应该从Spring容器中获得SqlSession对象;
- Mapper代理形式中,应该从Spring容器中直接获得Mapper的代理对象;
- 数据库的连接以及数据库连接池事务管理都要交给Spring容器来完成。
整合需要的jar包
MyBatis整合Spring所需的jar包如下:
- Spring的jar包;
- MyBatis的jar包;
- Spring与MyBatis的整合包,即
mybatis-spring-1.2.2.jar; - MySQL数据库驱动jar包;
- 数据库连接池的jar包。
整合的步骤
接下来,我将按照下面整合的步骤来整合MyBatis与Spring:
- 第一步:创建一个普通的Java工程;
- 第二步:导入jar包(上面所提到的jar包);
- 第三步:编写MyBatis的配置文件(即SqlMapConfig.xml);
- 第四步:编写Spring的配置文件,在该配置文件中,可能需要进行如下配置:
- 数据库连接及连接池
- 事务管理(暂时可以不配置)
- SqlSessionFactory对象需要配置到Spring容器中
- Mapeer代理对象或者是dao层实现类需要配置到Spring容器中
- 第五步:编写dao层或者mapper.xml映射文件;
- 第六步:测试。
逆向工程
可以针对单表自动生成MyBatis执行所需要的代码(包括po类,mapper.xml映射文件和Mapper接口等)。一般在实际开发中,常用的逆向工程方式是通过数据库的表生成代码。
按照官网开发即可
嵌套查询与嵌套结果查询
Mybatis表现关联关系比hibernate简单,没有分那么细致one-to-many、many-to-one、one-to-one。而是只有两种association(一)、collection(多),表现很简洁。下面通过一个实例,来展示一下Mybatis对于常见的一对多和多对一关系复杂映射是怎样处理的。
以最简单的用户表订单表这个最简单的一对多做示例:
对应的JavaBean:
User:
public class User {
private int id;
private String name;
private Double age;
private List<User_orders> orders;
// get set 省
}User_orders:
public class User_orders {
private int id;
private String name;
// get set 省
}对应的数据库:
mysql> desc user;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| age | double | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
mysql> desc user_orders;
+---------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| user_id | int(5) | YES | MUL | NULL | |
+---------+-------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
现在查询一个user的id查询出所有信息.如果不考虑关联查询,我们会先根据user的id在user表中查询出name,age然后设置给User类的时候,再根据该user的id在user_orders表中查询出所有订单并设置给User类。这样的话,在底层最起码调用两次查询语句,得到需要的信息,然后再组装User对象。
嵌套语句查询
mybatis提供了一种机制,叫做嵌套语句查询,可以大大简化上述的操作,加入配置及代码如下:
<resultMap type="domain.User" id="user">
<id column="id" property="id"/>
<result column="age" property="age"/>
<collection column="id" property="orders" ofType="domain.User_orders"
select="selectOrderByUser">
<id column="id" property="id"/>
<result column="name" property="name"/>
</collection>
</resultMap>
<select id="selectOrderByUser" parameterType="integer" resultType="domain.User_orders">
select id,name from user_orders where user_id = #{id}
</select>
<select id="findById" resultMap="user" parameterType="integer">
select * from user where id = #{id}
</select>
测试(可以成功查询到所有信息):
String config = "sqlMapConfig.xml";
InputStream inputStream = Resources.getResourceAsStream(config);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession session = sqlSessionFactory.openSession();
// 执行在bean配置文件中定义的sql语句
User user = session.selectOne("UserMapper.findById", 1);
//一句即可获取到复杂的User对象。
System.out.println(user);
session.commit();
session.close();嵌套语句查询的原理
在上面的代码中,Mybatis会执行以下流程:
1.先执行 findById 对应的语句从User表里获取到ResultSet结果集;
2.取出ResultSet下一条有效记录,然后根据resultMap定义的映射规格,通过这条记录的数据来构建对应的一个User 对象。
- 当要对User中的orders属性进行赋值的时候,发现有一个关联的查询,此时Mybatis会先执行这个select查询语句,得到返回的结果,将结果设置到user的orders属性上
这种关联的嵌套查询,有一个非常好的作用就是:可以重用select语句,通过简单的select语句之间的组合来构造复杂的对象。想如上的两个select完全可以独立使用。
嵌套查询的多对一
上面的关联查询查询其实是对于一对多的查询,即从user中查出user_order的信息。
现在从user_order中查user的信息.
在User_order表中增加字段user:
public class User_orders {
private int id;
private String name;
private User user;
//xxx
}配置select:
<resultMap type="domain.User_orders" id="user_order">
<id column="id" property="id"/>
<result column="name" property="name"/>
<association property="user" column="user_id" javaType="domain.User" select="selectUserByOrderId">
<id column="id" property="id"/>
<result column="age" property="age"/>
</association>
</resultMap>
<select id="selectUserByOrderId" parameterType="INTEGER" resultType="domain.User">
select id,age from user where id = #{id}
</select>
<select id="findOne" resultMap="user_order" parameterType="integer">
select * from user_orders where id=#{id}
</select>测试:
SqlSession session = sqlSessionFactory.openSession();
// 执行在bean配置文件中定义的sql语句
User_orders user_orders= session.selectOne("User_ordersMapper.findOne", 1);
System.out.println(user_orders);
//查询到了user_order对应的user的信息
session.commit();
session.close();嵌套查询的N+1问题
尽管嵌套查询大量的简化了存在关联关系的查询,但它的弊端也比较明显:即所谓的N+1问题。关联的嵌套查询显示得到一个结果集,然后根据这个结果集的每一条记录进行关联查询。
现在假设嵌套查询就一个(即resultMap 内部就一个association标签),现查询的结果集返回条数为N,那么关联查询语句将会被执行N次,加上自身返回结果集查询1次,共需要访问数据库N+1次。如果N比较大的话,这样的数据库访问消耗是非常大的!所以使用这种嵌套语句查询的使用者一定要考虑慎重考虑,确保N值不会很大。
以上面一对多(根据user的id查询order)的例子为例,select 语句本身会返回user条数为1 的结果集,由于它存在有1条关联的语句查询,它需要共访问数据库 1*(1+1)=2次数据库。
嵌套结果查询
嵌套语句的查询会导致数据库访问次数不定,进而有可能影响到性能。Mybatis还支持一种嵌套结果的查询:即对于一对多,多对多,多对一的情况的查询,Mybatis通过联合查询,将结果从数据库内一次性查出来,然后根据其一对多,多对一,多对多的关系和ResultMap中的配置,进行结果的转换,构建需要的对象。
重新定义User的结果映射 resultMap
<resultMap type="domain.User" id="user_auto">
<id column="id" property="id"/>
<result column="age" property="age"/>
<collection column="id" property="orders" ofType="domain.User_orders">
<id column="order_id" property="id"/>
<result column="name" property="name"/>
</collection>
</resultMap>对应的sql语句如下:
<select id="findAuth" resultMap="user_auto">
select u.id,u.age,o.id as order_id ,o.name,o.user_id as user_id from user u left outer join user_orders o
on o.user_id = u.id
</select>嵌套结果查询的执行步骤:
1.根据表的对应关系,进行join操作,获取到结果集;
- 根据结果集的信息和user 的resultMap定义信息,对返回的结果集在内存中进行组装、赋值,构造User;
- 返回构造出来的结果List 结果。
对于关联的结果查询,如果是多对一的关系,则通过形如 <association property="user" column="user_id" javaType="domain.User" > 进行配置,Mybatis会通过column属性对应的user_id 值去从内存中取数据,并且封装成User_order对象;
如果是一对多的关系,就如User和User_order之间的关系,通过形如 <collection column="id" property="orders" ofType="domain.User_orders">进行配置,MyBatis通过 id去内存中取User_orders对象,封装成List;
对于关联结果的查询,只需要查询数据库一次,然后对结果的整合和组装全部放在了内存中。
以上是通过查询User表所有信息来演示了一对多和多对一的映射对象处理。