本文首发于我的公众号 Linux云计算网络(id: cloud_dev) ,专注于干货分享,号内有 10T 书籍和视频资源,后台回复 「1024」 即可领取,欢迎大家关注,二维码文末可以扫。
一、概述
此处所说的堆为数据结构中的堆,而非内存分区中的堆。堆通常可以被看做是树结构,满足两个性质:1)堆中任意节点的值总是不大于(不小于)其子节点的值;2)堆是一棵完全树。正是由于这样的性质,堆又被称为优先队列。根据性质一,将任意节点不大于其子节点的堆称为最小堆或最小优先队列,反之称为最大堆或最大优先队列。优先队列在操作系统作业调度的设计中有着举足轻重的作用。之前写了一篇优先队列的文章,详见算法导论第六章优先队列。

常见的堆结构,有二叉堆、左倾堆、斜堆、二项堆、斐波那契堆等。斐波那契堆在前文算法导论第十九章 斐波那契堆已经作了讲述。本文主要对其余几种堆结构做宏观上的概述,并说明它们的异同点。
二、二叉堆
二叉堆是最简单的堆结构,本质是一棵完全的二叉树,一般由数组实现,其父节点和左右子节点之间存在着这样的关系: 索引为i(i从0开始)的左孩子的索引是 (2*i+1); 右孩子的索引是 (2*i+2); 父结点的索引是 floor((i-1)/2)。详细请看我之前写的一篇文章:算法导论第六章堆排序(一)。众所周知,二叉堆在排序算法中应用甚广,特别是涉及到大数据的处理中,如Topk算法。

三、二项堆
某些应用中需要用到合并两个堆的操作,这个时候二叉堆的性能就不是很好,最坏情况下时间复杂度为O(n)。为了改善这种操作,算法研究者就提出了性能更好的可合并堆,如二项堆和斐波那契堆,当然还有左倾堆,斜堆等。二项堆对于该操作能在最坏情况Θ(lgn)下完成,而斐波那契堆则更进一步,能在平摊时间为Θ(1)下完成(注意是平摊时间),见下表。除了Union操作,二叉堆各操作的性能都挺好,而二项堆对此也仅仅是改善了Union操作,对于Minimum操作甚至还不如二叉堆,我想这大概是《算法导论》第三版没有把二项堆再作为一章的原因之一吧。而斐波那契堆各个操作都有极好的性能,除了Extract_min和Delete操作。

说回到二项堆,二项堆是由一组的二项树组成,二项树B_k是一种递归定义的有序树,其具有以下的性质:
1)共有2^k个节点;
2)树的高度为k;
3)在深度 i 处恰有C^i_k个节点,因为C^i_k为二项系数,正因如此,才称其为二项树;
4)根的度数为k(即孩子节点个数),它大于任何其他节点的度数。
二项树B_0只包含一个节点,二项树B_k由两棵二项树B_k-1连接而成,其中一棵树的根是另一棵树的根的最左孩子。如下图:
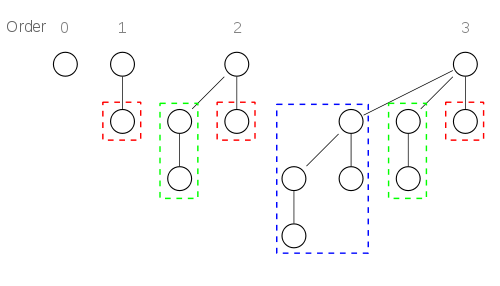
二项堆H由一组满足下面二项堆性质的二项树组成:
1)H中的每个二项树满足最小堆性质(说明二叉堆中最小节点在二项树的根中);
2)对任意非负整数k,H中至多有一棵二项树的根具有度数k(说明在包含n个节点的二项堆中,至多有floor(lgn)+1棵二项树)。
不同于斐波那契堆采用双循环链表来连接根节点和孩子节点,二项堆中采用的是单链表,每个节点有指向父节点的指针,孩子节点指针和兄弟节点指针,如:

1 struct BinomialHeapNode { 2 BinomialHeapNode *parent; 3 BinomialHeapNode *child; 4 BinomialHeapNode *sibling; 5 6 unsigned int degree; 7 KeyType key; 8 };
下面列上自己写的动态集合操作的代码:


#ifndef _BINOMIAL_HEAP_ #define _BINOMIAL_HEAP_ //#define NOT_IN_HEAP UINT_MAX // the node of binomial tree // struct heap_node { // struct heap_node* parent; // struct heap_node* child; // struct heap_node* sibling; // // unsigned int degree; // int key; // const void* value; // }; template<typename KeyType> class BinomialHeap { public: struct BinomialHeapNode { BinomialHeapNode *parent; BinomialHeapNode *child; BinomialHeapNode *sibling; unsigned int degree; KeyType key; }; public: BinomialHeap() { _head_list = NULL; } ~BinomialHeap() { BinomialHeapNode *tmp = _head_list; while (tmp) { BinomialHeapNode *next = tmp->sibling; _DeleteTree(tmp); tmp = next; } } public: //在二项堆中插入一个新节点 void BinomialInsert(KeyType new_key) { BinomialHeap new_heap; new_heap._head_list = new BinomialHeapNode(); new_heap._head_list->parent = new_heap._head_list->child = new_heap._head_list->sibling = NULL; new_heap._head_list->degree = 0; new_heap._head_list->key = new_key; this->BinomialUnion(new_heap); } //获取二项堆中最小元素的值 //用一个列表存根链表的值,然后找最小值,O(lgn),或者用一个指针指向最小值,O(1) KeyType Minimum() const { vector<KeyType> values_in_head_list; BinomialHeapNode *node = _head_list; while (node != NULL) { values_in_head_list.push_back(node->key); node = node->sibling; } return *min_element(values_in_head_list.begin(), values_in_head_list.end()); } bool CompVector( BinomialHeapNode *left, BinomialHeapNode *right ) { return left->key < right->key; } //弹出二项堆中的最小元素,并获取该最小元素的值 KeyType ExtractMinimum() { vector<BinomialHeapNode *> head_nodes; BinomialHeapNode *hl = _head_list; while ( hl ) { head_nodes.push_back( hl ); hl = hl->sibling; } / // auto min_ele = min_element(head_nodes.begin(), head_nodes.end(), [](BinomialHeapNode *left, BinomialHeapNode *right) // { // return left->key < right->key; // }); vector<BinomialHeapNode *>::iterator min_ele = min_element(head_nodes.begin(), head_nodes.end()/*, CompVector*/); int min_index = min_ele - head_nodes.begin(); KeyType min_value = ( *min_ele )->key; BinomialHeapNode *min_node = head_nodes[min_index]; //根链表上去掉最小结点,更新兄弟节点的值,注意头尾的处理 if ( min_index == 0 ) { if ( head_nodes.size() > 1 ) _head_list = head_nodes[1]; else _head_list = NULL; //根链表上只有一个元素 } else if ( min_index == head_nodes.size() - 1 ) head_nodes[min_index - 1]->sibling = NULL; else head_nodes[min_index - 1]->sibling = head_nodes[min_index + 1]; //处理最小结点的孩子节点 BinomialHeap new_head; new_head._head_list = min_node->child; BinomialHeapNode *x = new_head._head_list; //更新所有孩子节点上的兄弟节点 while ( x ) { x->parent = NULL; x = x->sibling; } //把独立出来的节点合并到原链表上 this->BinomialUnion( new_head ); delete min_node; min_node = NULL; return min_value; } //减小一个节点的值到某个值 void Decrease( BinomialHeapNode *x, KeyType k ) { if ( k > x->key ) throw exception("只能减少不能增大"); x->key = k; BinomialHeapNode *y = x; BinomialHeapNode *z = y->parent; while ( z && y->key < z->key ) { swap(y->key, z->key); y = z; z = y->parent; } } //删除一个结点 void Delete( BinomialHeapNode *node ) { if ( node ) { //将要删除的结点减小到最小值,然后在删除 Decrease( node, numeric_limits<KeyType>::min() ); ExtractMinimum(); } } //查找一个值为key的结点 //所有的堆堆查找操作的支持都很差,时间复杂度为O(n) BinomialHeapNode* Search( KeyType key ) const { BinomialHeapNode *tree = _head_list; //遍历根链 while ( tree ) { BinomialHeapNode *node = _SearchInTree( tree, key ); if ( node ) return node; tree = tree->sibling; } return NULL; } //联合另外一个二项堆,当联合操作完成后,other的二项堆中的数据将无效 void BinomialUnion( BinomialHeap &other ) { vector<BinomialHeapNode *> nodes; BinomialHeapNode *l = _head_list; BinomialHeapNode *r = other._head_list; while ( l ) { nodes.push_back( l ); l = l->sibling; } while ( r ) { nodes.push_back( r ); r = r->sibling; } if ( nodes.empty() ) return; //排序并合并两个二项堆 sort( nodes.begin(), nodes.end()); for ( size_t i = 0; i < nodes.size() - 1; ++ i ) nodes[i]->sibling = nodes[i + 1]; nodes[nodes.size()-1]->sibling = NULL; //重置根链表 this->_head_list = nodes[0]; //销毁待合并的链表 other._head_list = NULL; if ( this->_head_list == NULL ) return; //将具有相同度的二项树进行合并 BinomialHeapNode *prev_x = NULL; BinomialHeapNode *cur_x = _head_list; BinomialHeapNode *next_x = cur_x->sibling; while ( next_x ) { if ( cur_x->degree != next_x->degree || ( next_x->sibling != NULL && next_x->sibling->degree == cur_x->degree ) ) { prev_x = cur_x; cur_x = next_x; } else if ( cur_x->key < next_x->key ) { cur_x->sibling = next_x->sibling; _Link( next_x, cur_x ); } else { if ( prev_x == NULL ) _head_list = next_x; else prev_x->sibling = next_x; _Link( cur_x, next_x ); cur_x = next_x; } next_x = cur_x->sibling; } } //判断二项堆当前状态是否为空 bool IsEmpty() const { return _head_list == NULL; } //得到二项堆的根链表 BinomialHeapNode *GetHeadList() { return _head_list; } //显示二项堆 void Display() const { //stringstream ss; cout << "binomial_heap:" << "{" << endl; BinomialHeapNode *node = _head_list; if ( node ) cout << "rootlist->" << node->key << ";" << endl; while ( node ) { _DisplayTree( node ); if ( node->sibling ) cout << " " << node->key << "->" << node->sibling->key << ";" << endl; node = node->sibling; } cout << "}" << endl; } private: //删除一棵二项树 void _DeleteTree(BinomialHeapNode *tree) { if (tree && tree->child) { BinomialHeapNode *node = tree->child; while (node) { BinomialHeapNode *next = node->sibling; _DeleteTree(next); node = next; } delete tree; tree = NULL; } } //将D(k-1)度的y结点连接到D(k-1)度的z结点上去,使得z成为一个D(k)度的结点 void _Link(BinomialHeapNode *y, BinomialHeapNode *z) { y->parent = z; y->sibling = z->child; z->child = y; ++(z->degree); } //在二项树中搜索某个结点 BinomialHeapNode * _SearchInTree( BinomialHeapNode *tree, KeyType key ) const { if ( tree->key == key ) return tree; BinomialHeapNode *node = tree->child; while( node ) { BinomialHeapNode *n = _SearchInTree( node, key ); if ( n ) return n; node = node->sibling; } return NULL; } //画一棵二项树 void _DisplayTree( BinomialHeapNode *tree ) const { if ( tree ) { BinomialHeapNode *child = tree->child; if ( child ) { vector<BinomialHeapNode *> childs; while ( child ) { childs.push_back( child ); child = child->sibling; } // for_each( childs.begin(), childs.end(), [&]( BinomialHeapNode *c ){ // ss << " " << c->key << "->" << tree->key << ";" << endl; // _DisplayTree( ss, c ) // } ); for ( vector<BinomialHeapNode *>::iterator it = childs.begin(); it != childs.end(); ++ it ) { cout << " " << (*it)->key << "->" << tree->key << ";" << endl; _DisplayTree( *it ); } } } } private: BinomialHeapNode *_head_list; //根链表 }; #endif//_BINOMIAL_HEAP_
四、左倾堆
左倾堆(leftist tree 或 leftist heap),又称为左偏树。这种结构《算法导论》上没有提及,大概是因为太简单了吧。因为其本质是一棵二叉树,不像二项堆和斐波那契堆一样,具有复杂的结构。我想历史的演进过程大概是先提出左倾堆以及接下来要说的斜堆,然后才提出的二项堆和斐波那契堆这种复杂的结构,由易到难嘛,又或者同时,相反,anyway。
二叉堆是非常平衡的树结构,左倾堆,从名字上来看,这种堆结构应该是整体往左倾,不平衡,那是什么导致它往左倾,孩子节点个数?不可能,比如下面这棵树:

如果只从孩子节点个数来评判它往哪倾,则从整体上看,根节点的右孩子节点要多于左孩子节点,但是这棵树是左倾堆。那到底通过什么来评判一棵树为左倾堆?要引入一个属性:零距离(英文名NPL,Null Path Length)——表示的是从一个节点到一个“最近的不满节点”的路径长度(不满节点:两个子节点至少有一个为NULL)。一个叶节点的NPL为0,一个NULL节点的NPL为-1。因此,左倾的意思主要是看每个节点的NPL是否满足左孩子的NPL >= 右孩子的NPL,这也是左倾堆的性质一。当然啦,左倾堆既然叫堆,自然满足堆的性质:即每个节点的优先级大于子节点的优先级,这是性质二。还有性质三就是:节点的NPL = 它的右孩子的NPL + 1。如上图:每个节点旁边的标号即为它们的NPL值。
如前所述,这些堆结构的提出,主要是解决简单二叉堆中Union操作的低性能的。左倾堆的Union操作相对上述两种比较简单,基本思想如下:
1)如果一个空左倾堆与一个非空左倾堆合并,返回非空左倾堆;
2)如果两个左倾堆都非空,那么比较两个根节点,取较小堆的根节点为新的根节点。然后将“较小堆的根节点的右孩子”和“较大堆”进行合并;
3)如果新堆的右孩子的NPL > 左孩子的NPL,则交换左右孩子;
4)设置新堆的根节点的NPL = 右子堆NPL + 1。
上面的Union算法递归调用了自身,由于我们沿着右侧路径递归,所以时间复杂度为lgn量级。至于其他操作,比如insert,delete_min都可以在Union的基础上实现,如insert:将新增节点与一个已有的左倾堆做Union;delete_min删除根节点,将剩余的左右子堆合并。具体的就不再详述,如有疑问,可以参考这篇图文并茂的博客:左倾堆(一)之 图文解析 。(站在别人的肩膀上学习,避免重复造轮子^-^)
五、斜堆
斜堆(skew heap),又称自适应堆,它是左倾堆的一个变种。相比于左倾堆,斜堆的节点没有“NPL”这个属性,合并操作也相对简单了,但同样能实现lgn的量级。具体算法过程的前两步和左倾堆是一样的,只是第三步不像左倾堆要比较左右孩子的NPL大小才交换,而是合并后就直接交换。
六、总结
最常用的堆结构还是要属二叉堆,前面也提到过,如果没有Union操作,二叉堆的性能还是令人满意的。对于一些复杂的问题场景,则相应需要用到复杂的数据结构,此时斐波那契堆是最佳选择,如求最小生成树问题和求单源点最短路径问题的实现,如果基于斐波那契堆,则能得到非常好的性能。但这只是从理论上来说,《算法导论》上也说了,如果从实际应用角度来看,除了某些需要管理大量数据的应用外,对于大多数应用,斐波那契堆的常数因子和编程复杂性使得它比起普通二叉堆并不那么适用。因此,斐波那契堆的研究主要出于理论兴趣。这个时候,如果权衡一下,那就只有左倾堆和斜堆这等堆结构更适用了。是这样吗?不禁陷入了深深的思考中......
我的公众号 「Linux云计算网络」(id: cloud_dev),号内有 10T 书籍和视频资源,后台回复 「1024」 即可领取,分享的内容包括但不限于 Linux、网络、云计算虚拟化、容器Docker、OpenStack、Kubernetes、工具、SDN、OVS、DPDK、Go、Python、C/C++编程技术等内容,欢迎大家关注。
