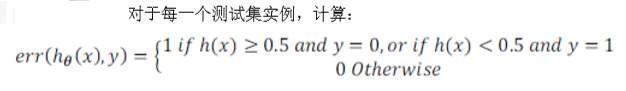反向传播的直观理解
在如下例子的神经网络中,误差从后向前传递。误差反向传递的过程中,以权值theta作为反向传递的依据。
如delta(4)1=y-a(4)1作为最终的误差。delta(3)2=theta(3)02*delta(4)1,delta(2)2=theta(2)12*delta(3)1+theta(2)22*delta(3)2
这里使用的表示法和之前相同,括号中为第几层的数据,角标数据为下一层与上一层的组合关系。

参数展开
在代码编程的过程中,使用costFunction函数,传入fminunc这样的优化求解器,可以找到无约束函数的最小值。
fminunc见:https://blog.csdn.net/qq_35488769/article/details/76396275。
问题在于传递参数过程中,由于是对神经网络进行的操作,每层之间使用的是矩阵权值、矩阵权值偏导数。所以需要将矩阵变换为向量,便于在函数见传递。传入后,再进行变换用于使用。

如下图中所示,thetaVec表示权值向量,它将所有的Theta展开为向量后,进行了矩阵连接成一维。同理如DVec。
thetaVec传入costFunction函数中后,使用reshape函数,可以恢复数据为之前的矩阵形式,然后就可以求D值吧,最后再变换为向量形式,返回参数。

其实就是如下图中,获得了初始的theta1,theta2,theta3矩阵以后,展开成向量传入fminunc函数,其theta会传入costFunction中。
costFunction中,恢复theta为矩阵,计算theta的偏导数矩阵D1,D2,D3,然后将D矩阵进行展开和连接,作为gradientVec返回。

梯度检验
梯度检验是为了保证,使用J误差函数,对theta求得的偏导数D的正确性。实现方式如下:
使用theta+-e的方式,求得一个近似梯度,然后和计算得出的梯度进行比较,一致则表示梯度正确。
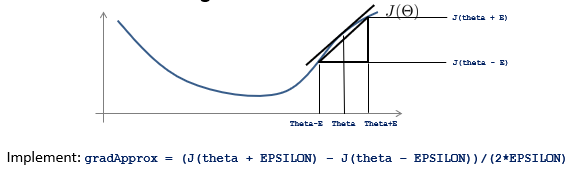
在多theta矩阵参数的具体应用过程中,固定住所有其他theta矩阵中的值,只对其中一个进行改变,然后计算近似梯度。
如下是对theta1,theta2,theta3等分别求得的偏导,
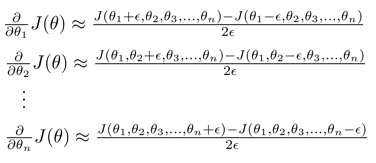
同理的代码实现:

在检验完成后,关闭梯度检验,以提高代码的执行速度。
随机初始化
为了使得神经网络具有良好的泛化特性,便于学习到不同的特征,需要使用随机初始化权值,而不是固定相同的权值,否则反向传递则会相同,神经网络性能不太好吧。
随机初始化可以设计为均匀分布,也可正态分布。如下是将Theta1和Theta2的连接权值矩阵设计为了(-INIT_EPSLON,INIT_EPSLON)的均匀分布吧。

神经网络综合总结
就是如下六步骤吧,初始权值,前向传递得出结果h,通过h和y计算误差J,然后对J求权值theta的偏导,然后梯度检验偏导得出的梯度值,正确则应用,最终进行反向传递,训练权值theta。

算法改进优化以及排错方向
没有正确的分析和以理论指导的工作,很大程度上会导致低效率,甚至数个月时间的浪费。
一些优化的方案如下,但是在选择方案的时候,还是强调,不是随机选择,而是使用机器学习诊断法。

诊断法:
评估假设函数h
所谓假设函数其实就是训练完成的神经网络模型,输出值为h,或者又如一个预测线性回归模型,或者又如分类问题的逻辑回归模型。
在判断如下模型是否过拟合时候,采用训练集和测试集的方式,对训练完成的模型进行评估。评估的方式,自然是误差。在训练集完成训练后,将测试集输入得出模型的输出误差J的值,训练集误差低而测试集误差太高的话,当然是过拟合了。训练集合测试集的比例一般按照先随机打乱,然后7:3进行分。

另外,针对逻辑回归,使用的J的值可以如下方式吧: