神经网络模型表示

前向传播
每一层都增加一个偏差单位x0=1和a0=1以后,使用如下公式推导出输出h。
相当于输入层的x经过权重theta乘积变换后重组为特征输出a,然后a再经过变换得到结果h。

theta作为权值矩阵的表示为:
在上述网络中,增加了偏置值x0,则从隐层向输入层,theta1的尺寸为3*4,下角标中第一位表示隐层单位编号,第二位表示输入层单位编号,以此连接的一条权值。
矩阵表示
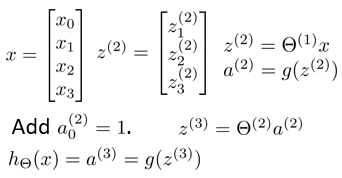
其中的z表示了theta与x的矩阵乘积。theta为3*4的规模,x为4*1的规模,求得z为3*1的输出,z再通过g函数,得到a。同理,得到a3,即输出。(过程中手动增加偏置,进行矩阵重组)
特征表示的直观理解

如上图,当以上的神经网络模型进行组合以后,可以得到异或模型。以上的三个神经网络输出中间值后,经过g函数,则变换为对应的0或1。如下所示,将神经网络组合后得到非线性的xnor分类的效果:
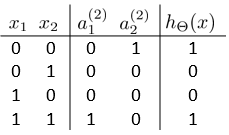
所以看来,神经网络的非线性化,其实是可以通过线性的神经网络组合表示的,也就是说,神经网络本质上,是由多个逻辑回归h函数,组合以后,获得的非线性化。
多元分类
采用onehot的编码方式,如下所示的四分类,将输出变为4个神经元,为1的表示对应的分类预测结果(如果是二分类,1个神经元输出就是足够的用0和1表示二分类,其实吧,也可以有其他的表示法,比如二进制编码吧,这样四分类,两个输出神经元,能降低一点网络规模吧)。

代价函数
代价函数与逻辑回归中有相似之处,在逻辑回归中,m为数据条数,x为输入,y为标签,h为预测函数,theta为h函数中x的参数,然后增加正则项防止过拟合,lambda为用于调节过拟合的程度的一个超参数。
参阅:https://www.cnblogs.com/bai2018/p/12526607.html#_label2
神经网络中,过拟合项类似,K为h函数的个数,也即为前向传播的下一层的输出个数。根据之前的推断,神经网络是由多个h函数的组合,获得了非线性效果。

反向传播算法
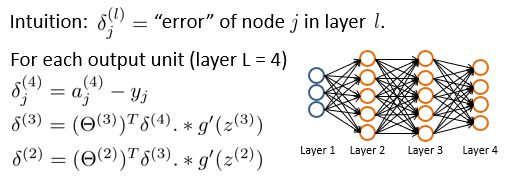
误差的反向传递通过以上实现,更新训练参数theta通过以下方式,训练神经网络:
其中D表示代价函数的偏导数,其,实现方案可以通过大derta的累积然后平均,然后代入theta实现。
