存储管理追求目标:有效降低存储资源消耗,节省存储成本。用最少存储成本满足最大化业务需求,使数据价值最大化。
1.生命周期管理
数据的生命周期管理是存储管理的一项重要手段。 通过生命周期管理矩阵可以保证存储最大化利用。
1.1生命周期管理策略
(1)删除策略
周期性删除:所存储的数据都有一定的有效期,可以周期性删除 X 天前的数据。
彻底删除:无用表数据或者 ETL 过程产生的临时数据,以及不需要保留的数据,可以进行及时删除
(2)保留策略
永久保留:重要且不可恢复的底层数据和应用数据需要永久保留。 可采用如下方式存储:
a.极限存储:极限存储可以超高压缩重复镜像数据。缺点是对数据质量要求非常高,配置与维护成本比较高,一个分区有超过 5GB 的镜像数据(如商品维表、用户维表)就使用极限存储。
b.冷数据存储:重要且不可恢复的、占用存储空间大于lOOTB,且访问频次较低的数据进行冷备,例如3年以上的日志数据。
c.增量表merge全量表:merge全量表只存储当前最新状态,如账户余额表。使用每日增量去merge更新全量表状态。
1.2通用生命周期管理矩阵
适合大数据生命周期管理的规范,主要通过对历史数据的等级划分与对表类型的划分生成相应的生命周期管理矩阵。
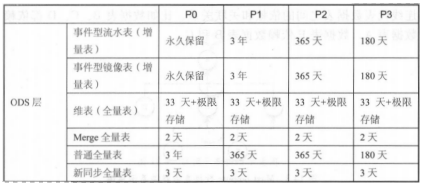
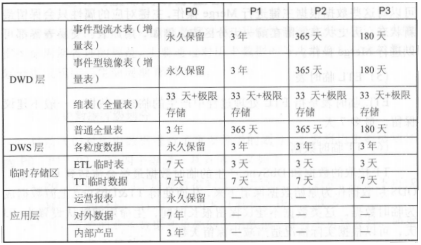
(1)历史数据划分为 P0、Pl、P2、P3 四个等级
P0:不可恢复,非常重要主题域和应用数据。如交易、日志表。
P1:不可恢复,重要业务和应用数据。如业务产品数据。
P2:可再恢复,重要业务和应用数据。如ETL中间过程数据。
P3:可再恢复,不重要业务和应用数据。如一些报表。
(2)表类型划分
事件型流水表(增量表):指数据无重复或者无主键数据,如日 志。
事件型镜像表(增量表):指业务过程性数据,有主键,但是对于同样主键的属性会发生缓慢变化,如交易、订单状态与时间会根据业务发生变更。
维表:维表包括维度与维度属性数据,如用户表、商品表。
Merge 全量表:包括业务过程性数据或者维表数据。由于数据本身有新增的或者发生状态变更,对于同样主键的数据可能会保留多份,因此可以对这些数据根据主键进行 Merge 操作,主键对应的属性只会保留最新状态 ,历史状态保留在前一天分区中。例如,用户表、交易表等。
ETL 临时表:ETL 临时表是指 ETL 处理过程中产生的临时表数据,一般不建议保留,最多 7 天。
TT 临时数据:TT 拉取的数据和 DbSync 产生的临时数据最终会流转到 ODS 层,ODS 层数据作为原始数据保留下来,从而使得 TT&DbSync 上游数据成为临时数据。这类数据不建议保留很长时间,生命周期默认设置为 93天 ,可以根据实际情况适当减少保留天数。
普通全量表:很多小业务数据或者产品数据, BI 一般是直接全量拉取 ,这种方式效率快,对存储压力也不是很大,而且表保留很长时间,可以根据历史数据等级确定保留策略。
2.存储治理项优化
建立存储治理项优化闭环四个环节:现状分析(形成存储治理优化项)、 问题诊断(形成治理项)、管理优化(治理项推送和优化)、效果反馈(回收优化存储效果)。通过这个闭环,可以有效地推进数据存储的优化,降低存储管理的成本。

2.1存储治理优化项
(1)未管理的表
(2) 空表
(3)最近 62 天未访问表、大于100G且无访问表
(4)数据无更新无任务表 、数据无更新有任务表
(5)长周期表
2.2数据压缩优化方法
(1)问题背景:
分布式文件系统中,默认通常会将数据存储3份,这就需要存储 lTB 的逻辑数据, 实际上会占用3TB的物理空间。
(2)解决方案:
MaxCompute提供的archive压缩方法,数据保存为 RAID file(6,3)的格式文件,即 6 份数据+3 份校验块的方式 ,逻辑、物理存储比由1:3降到1:1.5,省一半空间。

(3)适用场合:
archive 压缩方法应用在冷备数据与日志数据的压缩存储上。
(4)压缩代价:
如果某个数据块出现了损坏或者某台机器着机损坏了,恢复数据块的时间将要比原来的方式更长,读的性能会有一定的损失。
2.3数据重分布优化方法
(1)列式存储
数据表(堆,B-Tree)以行存储模式存储数据,而列存储索引以列存储模式存储数据。行存储和列存储的示例图:

(2)避免列热点
MaxCompute 中主要采用基于列存储的方式,由于每个表的数据分布不同,插人数据的顺序不一样,会导致压缩效果有很大的差异。
因此通过修改表的数据重分布,避免列热点,将会节省一定的存储空间。目前我们主要通过修改 distribute by 和 sort by 字段的方法进行数据重分布。
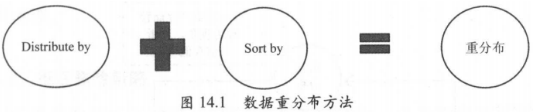
数据重分布效果的波动比较大,这主要眼数据表中宇段的重复值、字段本身的大小、其他宇段的具体分布有一定 的关系, 一般我们会筛选出重分布效果高于 15%的表进行优化处理。

3.数据资产成本管理
数据资产的成本管理分为数据成本计量和数据使用计费两个步骤。
3.1数据成本计量
数据成本定义为存储成本、计算成本和扫描成本三个部分。 通过成本计量,可以比较合理地评估出数据加工链路中的成本 ,从成本的角度反映出在数据加工链路中是否存在加工复杂、链路过长、依赖不合理等问题,间接辅助数据模型优化,提升数据整合效率。
(1)存储成本是为了计量数据表消耗的存储资源
(2)计算成本是为了计量数据计算过程中的 CPU 消耗
(3)引人扫描成本的概念,可以避免仅仅将表自身硬件资源的消耗作为数据表的成本,还应引入依赖任务的成本。(A依赖B,B依赖C,C依赖D;C的数据成本应含A和B的成本)。
3.2数据使用计费
数据使用付费定义为存储付费、计算付费和扫描付费。通过数据使用计费,可以规范下游用户的数据使用方法,提升数据使用效率,从而为业务提供优质的数据服务。
4.扩展知识:
MaxCompute作为阿里巴巴计算力的核心引擎,承载着阿里集团99%的数据存储和95%的计算,是阿里集团名副其实的航母级计算引擎。在2017年的双11的技术大考中,MaxCompute双11当天数据处理峰值超过320PB,百万级调度作业,不断刷新极限。
参考文档: