SGD
SGD是深度学习中最常见的优化方法之一,虽然是最常使用的优化方法,但是却有不少常见的问题。
learning rate不易确定,如果选择过小的话,收敛速度会很慢,如果太大,loss function就会在极小值处不停的震荡甚至偏离。每个参数的learning rate都是相同的,如果数据是稀疏的,则希望出现频率低的特征进行大一点的更新。深度神经网络之所以比较难训练,并不是因为容易进入局部最小,而是因为学习过程容易进入马鞍面中,在这种区域中,所有方向的梯度值几乎都是0。
Momentum(动量)
Momentum借助了物理中的动量的概念,即前几次的梯度也会参与计算。为了表示动量,引入一个新的变量V,V是之前的梯度的累加,但是在每个回合都会有一定的衰减。它的特点是当前后梯度方向不一致时,能够加速学习,前后梯度方向一致时,能够抑制震荡。

其中,v就体现了累加的梯度,![]() 表示学习率,当前后梯度一致时,v的值就越来越大,因而加速训练,当出现震荡时,v能够起到缓冲震荡的作用。
表示学习率,当前后梯度一致时,v的值就越来越大,因而加速训练,当出现震荡时,v能够起到缓冲震荡的作用。
Nesterov Momentum
对Momentum的一种改进:先对参数进行估计,然后使用估计估计后的参数来计算误差。
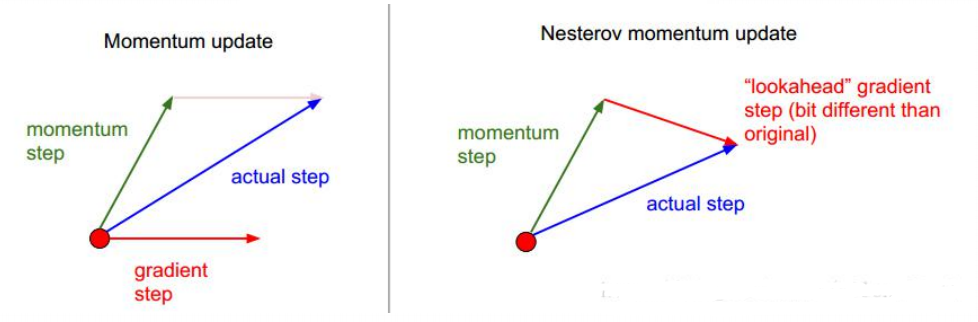
先通过冲量对参数进行更新,相当于向前迈了一步,在计算出这时的梯度,利用这时的梯度进行更新参数。
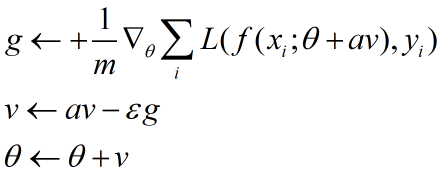
区别于momentum的地方在于先进行了参数的更新。
Adagrad
在上述的优化算法中,参数的步长都是相的,那么能否为不同的常数设置不同的步长呢,对于梯度大的参数设置小的步长,对于梯度小的参数,设置大的步长。类比于在缓坡上面,我们可以大步长的前进,在陡坡上面,这需要小步长的前进。adagrad则是参考了这个思路。
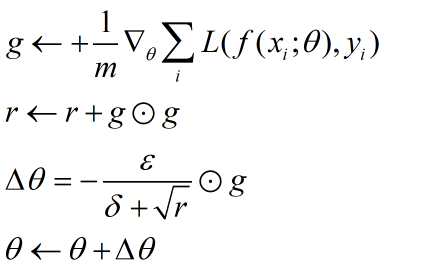
上述的式子中,对梯度的平方进行了累加,所以r值一直都是递增的,故梯度的改变量会越来越小。对于较小的梯度,r的开方若小于1的,故梯度的改变量则较大,对于较大的梯度,r的开放较大,所以梯度改变量则较小。该优化方法的问题是,r的值一直是递增的,导致梯度梯度改变量会一直减小。
RMSprop
RMSprop是对Adagrad的改进,通过引入一个衰减系数,让r每回合都衰减一定的比例。这种方法能够很好的解决Adagrad的过早结束的问题,适合处理非平衡的目标,对于RNN 的效果很好。
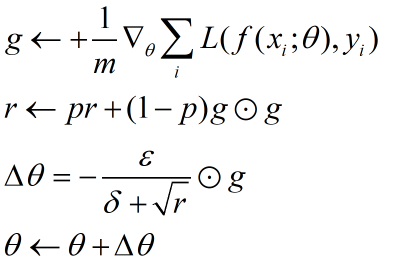
该算法的做法是通过一个参数来控制r的值。
Adam
Adam的名称是adaptive moment estimation,自适应矩估计。它的本质上是带有动量的RMSprop,利用梯度的一阶矩估计和二阶矩估计调整每个参数的学习率。
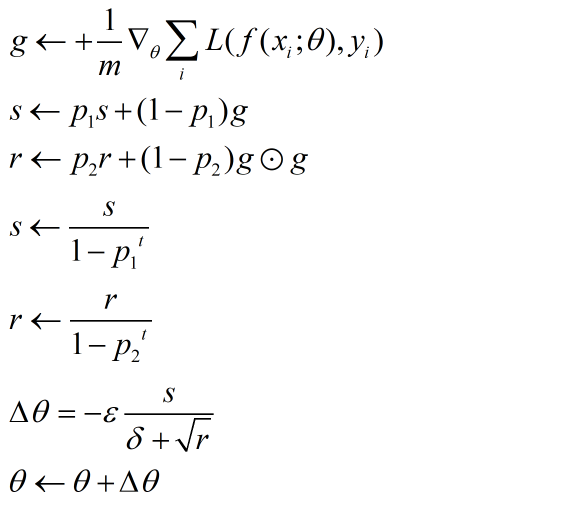
其中,s是一阶矩估计,r是二阶矩估计 ,一阶矩部分中就是带有冲量的部分,二阶矩中就是使得各个参数有不同的梯度。

优化算法的选择
如果数据是稀疏的,就用自适应方法,即adagrad,adadelte,RMSprop,Adam。这几种算法在很多的情况下都是相似的,通过Adam是比较好的选择。如果需要快速的验证新模型可以使用Adam;当模型上线发布时,可以使用SGD进行模型的极致优化。