一.归并排序的优缺点(pros and cons)
耗费心思来理解它,总要有个理由吧:
- 归并排序的效率达到了巅峰:时间复杂度为O(nlogn),这是基于比较的排序算法所能达到的最高境界
- 归并排序是一种稳定的算法(即在排序过程中大小相同的元素能够保持排序前的顺序,3212升序排序结果是1223,排序前后两个2的顺序不变),这一点在某些场景下至关重要
- 归并排序是最常用的外部排序方法(当待排序的记录放在外存上,内存装不下全部数据时,归并排序仍然适用,当然归并排序同样适用于内部排序...)
缺点:
- 归并排序需要O(n)的辅助空间,而与之效率相同的快排和堆排分别需要O(logn)和O(1)的辅助空间,在同类算法中归并排序的空间复杂度略高
P.S.本文只讨论最原始的“两路归并”,多路的与之类似
二.内部原理
首先要知道归并排序的思想是:分治法,与快速排序的思想一样
算法思想:无序 -> 部分有序 -> 整体有序
归并排序中“分”与“合”的过程是结合在一起的,即每一趟都在做“分”与“合”的工作,并不是先“分”完再“合”(“分”很简单,不就是一直二分二分直到不可再分呗,额,这么想就错了,分完就合不起来了,切记“分”与“合”是结合在一起的)
用一幅图来解释归并排序的过程就足够了:
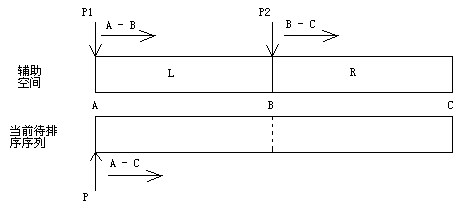
说明:P1与P2比较,将较大(小)者装入P,然后P1或者P2右移(装了谁就移谁),最后P右移
比如要对数组a[n]做升序排序,那么具体过程如下:
- 申请两个长度都为n/2的辅助空间,把a数组装进去,前一半装进L,后一半装进R
- 按照说明中的方式做一轮比较(P从A移动到C,一趟结束)
现在想想我们做完一趟排序得到了什么?
- 达成了部分有序(前一半 < 后一半,对吧?)
- 除此之外,我们很自然的把待排序序列一分为二,为递归做好了准备
还不够清晰?那么还有几句话:
- 图示的过程解释了为什么需要长度为n的辅助空间
- 只要L和R各自内部都有序(同升序或者同降序),那么只需要再经过一趟归并,排序就完成了(仔细想想,没错吧?)
- 排序部分就是合并部分(还记得上面提过的那句话吗?“分”与“合”的过程是结合在一起的,千万不能分开想,否则你会发现合不起来了...)
三.实现细节
如果上面的解释还不够清晰,那么我们来举个例子,一步步分析:
假定待排序序列为a[] = {3, 2, 1, 4},那么具体过程是这样的:
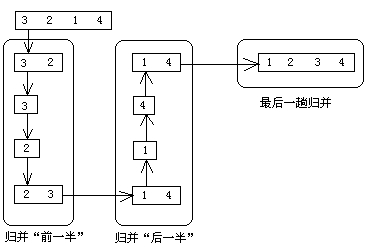
P.S.如果待排序序列是奇数个怎么办?这是问题吗?无非是拆得的前一半比后一半少一个而已,单趟循环控制是由P指针来做的,不存在某个P1没有与之配对的P2可以比的问题
四.总结
归并排序多用于需要外部排序的场景,除此之外当内部排序需要保证稳定性时也采用归并排序(不要求稳定性的内部排序一般采用快排或者堆排序,前者在待排序序列基本有序时效率低,后者堆的维护是个问题)