总结:(源文件名为loops.c)
可以转换到不同阶段。阶段1,将头文件加进来。阶段2,转换成汇编程序,与机器类型相关。阶段3,转换成机器码,但不完整。阶段4,链接其他系统文件,形成最终可执行文件
cc -E -o loops-firststep.e loops.c
cc -S -o loops-second.s loops.c
cc -c loops.c#此时出现.o文件。或者,更可控地:cc -c -o loops-third.o loops.c
cc -o loops-final loops.c#链接成最终可执行文件
转一:
The Four Stages of Compiling a C Program
Compiling a C program is a multi-stage process. At an overview level, the process can be split into four separate stages: Preprocessing, compilation, assembly, and linking.
In this post, I’ll walk through each of the four stages of compiling the following C program:
/*
* "Hello, World!": A classic.
*/
#include <stdio.h>
int
main(void)
{
puts("Hello, World!");
return 0;
}
Preprocessing#包含头文件
The first stage of compilation is called preprocessing. In this stage, lines starting with a # character are interpreted by the preprocessor as preprocessor commands. These commands form a simple macro language with its own syntax and semantics. This language is used to reduce repetition in source code by providing functionality to inline files, define macros, and to conditionally omit code.
Before interpreting commands, the preprocessor does some initial processing. This includes joining continued lines (lines ending with a ) and stripping comments.
To print the result of the preprocessing stage, pass the -E option to cc:
cc -E hello_world.c
Given the “Hello, World!” example above, the preprocessor will produce the contents of the stdio.h header file joined with the contents of the hello_world.c file, stripped free from its leading comment:
[lines omitted for brevity]
extern int __vsnprintf_chk (char * restrict, size_t,
int, size_t, const char * restrict, va_list);
# 493 "/usr/include/stdio.h" 2 3 4
# 2 "hello_world.c" 2
int
main(void) {
puts("Hello, World!");
return 0;
}
Compilation#转成机器相关的汇编语言
The second stage of compilation is confusingly enough called compilation. In this stage, the preprocessed code is translated to assembly instructions specific to the target processor architecture. These form an intermediate human readable language.
The existence of this step allows for C code to contain inline assembly instructions and for different assemblers to be used.
Some compilers also supports the use of an integrated assembler, in which the compilation stage generates machine code directly, avoiding the overhead of generating the intermediate assembly instructions and invoking the assembler.
To save the result of the compilation stage, pass the -S option to cc:
cc -S hello_world.c
This will create a file named hello_world.s, containing the generated assembly instructions. On macOS 10.10.4, where cc is an alias for clang, the following output is generated:
.section __TEXT,__text,regular,pure_instructions
.macosx_version_min 10, 10
.globl _main
.align 4, 0x90
_main: ## @main
.cfi_startproc
## BB#0:
pushq %rbp
Ltmp0:
.cfi_def_cfa_offset 16
Ltmp1:
.cfi_offset %rbp, -16
movq %rsp, %rbp
Ltmp2:
.cfi_def_cfa_register %rbp
subq $16, %rsp
leaq L_.str(%rip), %rdi
movl $0, -4(%rbp)
callq _puts
xorl %ecx, %ecx
movl %eax, -8(%rbp) ## 4-byte Spill
movl %ecx, %eax
addq $16, %rsp
popq %rbp
retq
.cfi_endproc
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "Hello, World!"
.subsections_via_symbols
Assembly#转换成机器码,生成.o文件
During this stage, an assembler is used to translate the assembly instructions to object code. The output consists of actual instructions to be run by the target processor.
To save the result of the assembly stage, pass the -c option to cc:
cc -c hello_world.c
Running the above command will create a file named hello_world.o, containing the object code of the program. The contents of this file is in a binary format and can be inspected using hexdump or od by running either one of the following commands:
hexdump hello_world.o
od -c hello_world.o
Linking#链接缺失部分,成为真正可执行文件
The object code generated in the assembly stage is composed of machine instructions that the processor understands but some pieces of the program are out of order or missing. To produce an executable program, the existing pieces have to be rearranged and the missing ones filled in. This process is called linking.
The linker will arrange the pieces of object code so that functions in some pieces can successfully call functions in other ones. It will also add pieces containing the instructions for library functions used by the program. In the case of the “Hello, World!” program, the linker will add the object code for the puts function.
The result of this stage is the final executable program. When run without options, cc will name this file a.out. To name the file something else, pass the -o option to cc:
cc -o hello_world hello_world.c转二:
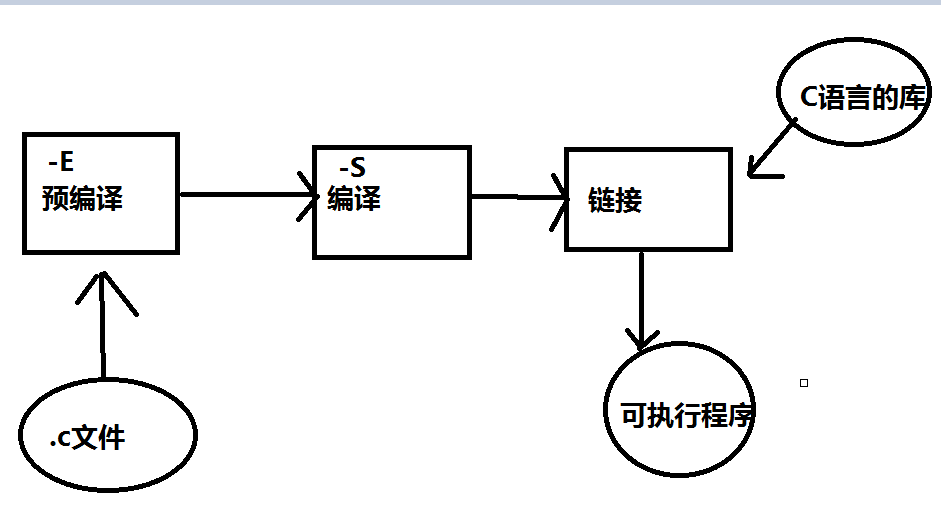
GCC编译器的基本选项如下表:
| 类型 | 说明 |
| -E | 预处理后即停止,不进行编译、汇编及连接 |
| -S | 编译后即停止,不进行汇编及连接 |
| -c | 编译或汇编源文件,但不进行连接 |
| -o file | 指定输出文件file |
C语言的include头文件
- include是要告诉编译器,包含头文件
- 在C语言中,任何的库函数调用都需要包含头文件
- 头文件也相当于一个文档声明
- 如果把main函数放在第一个文件中,而把自定义函数放在第二个文件中,那么就需要在第一个文件中声明函数原型
- 如果把函数原型包含在一个头文件中,那么就不用每次使用函数的时候都声明其原型了,把函数声明放进头文件中是个好习惯!
- 头文件可以不需要编译
- 可以查看具体的声明
- 头文件加上实现文件的o文件提交给使用者即可,不需要知道源代码
- o文件预先编译,所以整个项目编译时,会大大提高编译的时间 。
- 当一个文件(A.c文件)依赖于头文件(b.h)时,如果b.c编译之后形成的b.o文件重新编译后,a.o的文件不需要重新编译
- 可以极大降低手工复制,粘贴的错误几率
头文件的注意事项:
- <头文件>,表示让C语言编译器在系统目录(即gcc编译器的include目录下)下寻找相关的头文件
- “头文件”,表示让C语言编译器在用户当前目录下寻找相关的头文件
- 如果是使用了C语言库函数的需要的头文件,那么一定是#include<>
- 如果是使用了用户自定义的头文件,那么一定是#include“”
转三:
C语言编译和链接详解(通俗易懂,深入本质)
我们平时所说的程序,是指双击后就可以直接运行的程序,这样的程序被称为可执行程序(Executable Program)。在 Windows 下,可执行程序的后缀有.exe和.com(其中.exe比较常见);在类 UNIX 系统(Linux、Mac OS 等)下,可执行程序没有特定的后缀,系统根据文件的头部信息来判断是否是可执行程序。
可执行程序的内部是一系列计算机指令和数据的集合,它们都是二进制形式的,CPU 可以直接识别,毫无障碍;但是对于程序员,它们非常晦涩,难以记忆和使用。
例如,在屏幕上输出“VIP会员”,C语言的写法为:
puts("VIP会员");
二进制的写法为:

你感受一下,直接使用二进制是不是想撞墙,是不是受到一吨重的伤害?
在计算机发展的初期,程序员就是使用这样的二进制指令来编写程序的,那个拓荒的年代还没有编程语言。
直接使用二进制指令编程对程序员来说简直是噩梦,尤其是当程序比较大的时候,不但编写麻烦,需要频繁查询指令手册,而且除错会异常苦恼,要直接面对一堆二进制数据,让人眼花缭乱。另外,用二进制指令编程步骤繁琐,要考虑各种边界情况和底层问题,开发效率十分低下。
这就倒逼程序员开发出了编程语言,提高自己的生产力,例如汇编、C语言、C++、Java、Python、Go语言等,都是在逐步提高开发效率。至此,编程终于不再是只有极客能做的事情了,不了解计算机的读者经过一定的训练也可以编写出有模有样的程序。
编译(Compile)
C语言代码由固定的词汇按照固定的格式组织起来,简单直观,程序员容易识别和理解,但是对于CPU,C语言代码就是天书,根本不认识,CPU只认识几百个二进制形式的指令。这就需要一个工具,将C语言代码转换成CPU能够识别的二进制指令,也就是将代码加工成
.exe 程序的格式;这个工具是一个特殊的软件,叫做编译器(Compiler)。
编译器能够识别代码中的词汇、句子以及各种特定的格式,并将他们转换成计算机能够识别的二进制形式,这个过程称为编译(Compile)。
编译也可以理解为“翻译”,类似于将中文翻译成英文、将英文翻译成象形文字,它是一个复杂的过程,大致包括词法分析、语法分析、语义分析、性能优化、生成可执行文件五个步骤,期间涉及到复杂的算法和硬件架构。对于学计算机或者软件的大学生,“编译原理”是一门专业课程,有兴趣的读者请自行阅读《编译原理》一书,这里我们不再展开讲解。
注意:不了解编译原理并不影响我们学习C语言,我也不建议初学者去钻研编译原理,贪多嚼不烂,不要把自己绕进去。
C语言的编译器有很多种,不同的平台下有不同的编译器,例如:
- Windows 下常用的是微软开发的 Visual C++,它被集成在 Visual Studio 中,一般不单独使用;
- Linux 下常用的是 GUN 组织开发的 GCC,很多 Linux 发行版都自带 GCC;
- Mac 下常用的是 LLVM/Clang,它被集成在 Xcode 中(Xcode 以前集成的是 GCC,后来由于 GCC 的不配合才改为 LLVM/Clang,LLVM/Clang 的性能比 GCC 更加强大)。
你的代码语法正确与否,编译器说了才算,我们学习C语言,从某种意义上说就是学习如何使用编译器。
编译器可以 100% 保证你的代码从语法上讲是正确的,因为哪怕有一点小小的错误,编译也不能通过,编译器会告诉你哪里错了,便于你的更改。
链接(Link)
C语言代码经过编译以后,并没有生成最终的可执行文件(.exe 文件),而是生成了一种叫做目标文件(Object File)的中间文件(或者说临时文件)。目标文件也是二进制形式的,它和可执行文件的格式是一样的。对于 Visual C++,目标文件的后缀是.obj;对于 GCC,目标文件的后缀是.o。
目标文件经过链接(Link)以后才能变成可执行文件。既然目标文件和可执行文件的格式是一样的,为什么还要再链接一次呢,直接作为可执行文件不行吗?
不行的!因为编译只是将我们自己写的代码变成了二进制形式,它还需要和系统组件(比如标准库、动态链接库等)结合起来,这些组件都是程序运行所必须的。
链接(Link)其实就是一个“打包”的过程,它将所有二进制形式的目标文件和系统组件组合成一个可执行文件。完成链接的过程也需要一个特殊的软件,叫做链接器(Linker)。
随着我们学习的深入,我们编写的代码越来越多,最终需要将它们分散到多个源文件中,编译器每次只能编译一个源文件,生成一个目标文件,这个时候,链接器除了将目标文件和系统组件组合起来,还需要将编译器生成的多个目标文件组合起来。
再次强调,编译是针对一个源文件的,有多少个源文件就需要编译多少次,就会生成多少个目标文件。
总结
不管我们编写的代码有多么简单,都必须经过「编译 --> 链接」的过程才能生成可执行文件:
- 编译就是将我们编写的源代码“翻译”成计算机可以识别的二进制格式,它们以目标文件的形式存在;
- 链接就是一个“打包”的过程,它将所有的目标文件以及系统组件组合成一个可执行文件。
转四:
linker input file unused because linking not done
GCC是Linux平台下常用的编译链接器。编译链接的过程分为:
源代码-->预处理文件(.i)-->编译后的汇编代码(.s)-->汇编后的二进制文件(.o)-->链接后的二进制物件(无后缀)。
处理程序分别是 :cpp、ccl、as、ld。
使用 -v选项,可以看到各个阶段关联的处理程序。
使用gcc -E 指示gcc对源代码进行预处理,结果直接输出到终端。
使用gcc -S 指示gcc编译成为汇编语言
使用gcc -c 指示gcc直至形成二进制文件(不进行链接)
使用gcc 指示gcc链接形成二进制物件(多个二进制模块链接形成大的模块或者可执行程序)
因此你需要的目标文件的种类是 -E、-S、-c或者不带这些参数确定的,
源文件可以是中间文件的一种。-o参数控制的仅仅是输出文件的名称。
但是gcc默认会根据源文件的后缀去判断应该调用处理程序的那些。例如源文件的后缀是.c,则gcc -E使用的是cpp,gcc -c则使用cpp、ccl、as。如果源文件的后缀是.o,则gcc -E 是无法进行的,会报错:linker input file unused because linking not done。这是gcc发现这个应该进行链接,但是选项指示不使用linker程序,因而报这种错误信息。如果源文件是二进制的文件,但是保存的源文件后缀却是.c,则gcc会当作这是.c文件,如果采用gcc不带参数,则gcc会很多错,因为它把这个文件当作源代码处理的。
注意:这里,源文件指的是gcc的输入文件,源代码指的是程序源代码文件。