散列表是普通数组概念的推广。由于对普通数组可以直接寻址,使得能在O(1)时间内访问数组中的任意位置。在散列表中,不是直接把关键字作为数组的下标,而是根据关键字计算出相应的下标。
使用散列的查找算法分为两步。第一步是用散列函数将被查找的键转化为数组的一个索引。
我们需要面对两个或多个键都会散列到相同的索引值的情况。因此,第二步就是一个处理碰撞冲突的过程,由两种经典解决碰撞的方法:拉链法和线性探测法。
散列表是算法在时间和空间上作出权衡的经典例子。
如果没有内存限制,我们可以直接将键作为(可能是一个超大的)数组的索引,那么所有查找操作只需要访问内存一次即可完成。但这种情况不会经常出现,因此当键很多时需要的内存太大。
另一方面,如果没有时间限制,我们可以使用无序数组并进行顺序查找,这样就只需要很少的内存。而散列表则使用了适度的空间和时间并在这两个极端之间找到了一种平衡。
●散列函数
我们面对的第一个问题就是散列函数的计算,这个过程会将键转化为数组的索引。我们要找的散列函数应该易于计算并且能够均匀分布所有的键。
散列函数和键的类型有关,对于每种类型的键我们都需要一个与之对应的散列函数。
正整数
将整数散列最常用的方法就是除留余数法。我们选择大小为素数M的数组,对于任意正整数k,计算k除以M的余数。(如果M不是素数,我们可能无法利用键中包含的所有信息,这可能导致我们无法均匀地散列值。)
浮点数
将键表示为二进制数,然后再使用除留余数法。(让浮点数的各个位都起作用)(Java就是这么做的)
字符串
除留余数法也可以处理较长的键,例如字符串,我们只需将它们当做大整数即可。即相当于将字符串当做一个N位的R进制值,将它除以M并取余。
·····软缓存
如果散列值的计算很耗时,那么我们或许可以将每个键的散列值缓存起来,即在每个键中使用一个hash变量来保存它的hashCode()返回值。
●基于拉链法的散列表
一个散列函数能够将键转化为数组索引。散列算法的第二步是碰撞处理,也就是处理两个或多个键的散列值相同的情况。
拉链法:将大小为M的数组中的每个元素指向一条链表,链表中的每个结点都存储了散列值为该元素的索引的键值对。
查找分两步:首先根据散列值找到对应的链表,然后沿着链表顺序查找相应的键。
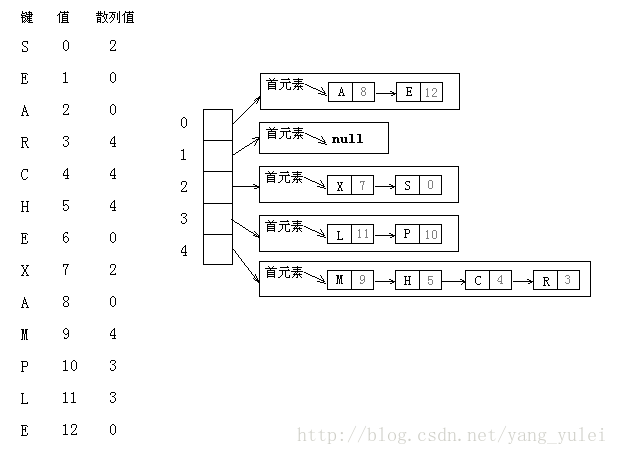
拉链法在实际情况中很有用,因为每条链表确实都大约含有N/M个键值对。
基于拉链法的散列表的实现简单。在键的顺序并不重要的应用中,它可能是最快的(也是使用最广泛的)符号表实现。
●基于线性探测法的散列表
实现散列表的另一种方式就是用大小为M的数组保存N个键值对,其中M>N。我们需要依靠数组中的空位解决碰撞冲突。基于这种策略的所有方法被统称为开放地址散列表。
开放地址散列表中最简单的方法叫做线性探测法:当碰撞发生时,我们直接检查散列表中的下一个位置(将索引值加1),如果不同则继续查找,直到找到该键或遇到一个空元素。
(开放地址类的散列表的核心思想是:与其将内存用作链表,不如将它们作为在散列表的空元素。这些空元素可以作为查找结束的标志。)
特点:散列最主要的目的在于均匀地将键散布开来,因此在计算散列后键的顺序信息就丢失了,如果你需要快速找到最大或最小的键,或是查找某个范围内的键,散列表都不是合适的选择。
【应用举例】
海量处理
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
答:
可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
分而治之/hash映射:
遍历文件a,对每个url求取,然后根据所取得的值将url分别存储到1000个小文件(记为,这里漏写个了a1)中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为)。这样处理后,所有可能相同的url都在对应的小文件()中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
hash_set统计:
求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
参考文章:https://blog.csdn.net/yang_yulei/article/details/26104921