一、横向扩容(添加新节点)
1.克隆一台虚拟机
修改ip及主机名
清空 /opt/software/hadoop-2.7.7/tmp/dfs下文件
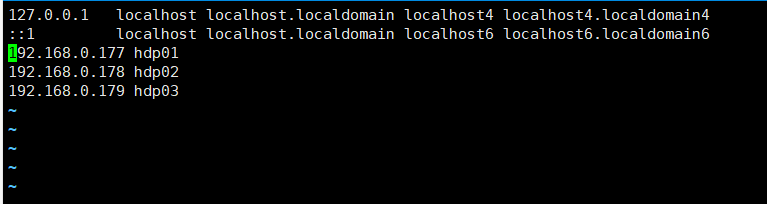
2.在hadoop服务器虚拟机配置ip映射
启动satrt-dfs.sh
vim /etc/hosts
3.配置slaves
vim etc/hadoop/slaves

加入新的主机名
4.给hdp03加免密
ssh-copy-id hdp03
5.启动hdp03的datanode
ssh hdp03 #控制hdp03
hadoop-daemon.sh start datanode #启动datanode
访问192.168.0.177:50070可看到三个节点

二、纵向扩容(添加硬盘)
1.右键虚拟机-->设置-->添加 点击硬盘添加
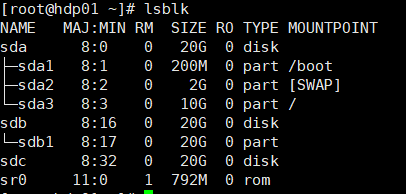
lsblk查看当前系统硬盘的使用情况

重启后
2.硬盘分区
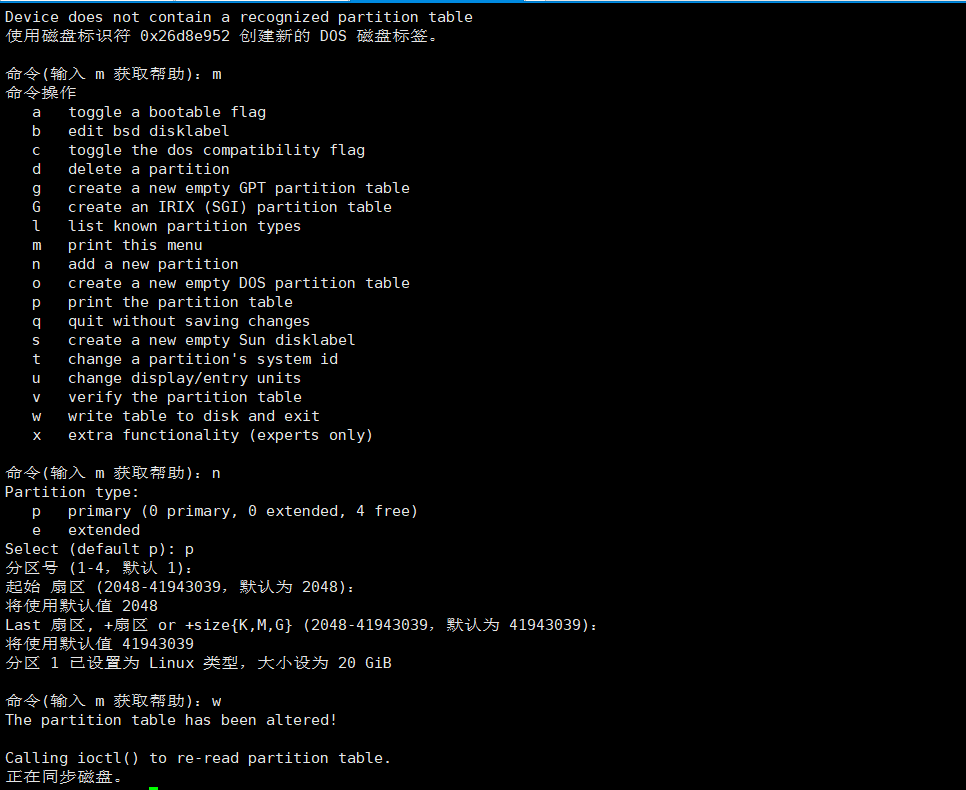
fdisk /dev/sdc
m:获取帮助
n:分区
p:查看分区表
w:将分区信息写入硬盘

3.格式化
mkfs.xfs /dev/sdc1
4.挂载
在根目录mkdir sdc1
mount /dev/sdc1 /sdc1
vim /etc/fstab 配置开机挂载信息

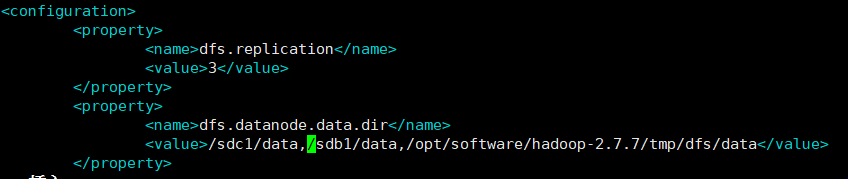
5.配置hdfs-site.xml
cd /opt/software/hadoop-2.7.7/etc/hadoop
vim hdfs-site.xml
6.启动
start-dfs.sh
配置前:

配置后:
