简述
Java与那些较传统的语言比如C++有个很大不同就是垃圾回收策略了。前者通常是虚拟机自动帮我们做了,而后者就需要我们手动来完成。
Java虚拟机帮我们完成了垃圾回收,是不是意味着我们就不用完全去管它了呢?当然不是的。在很多场景下,虚拟机默认做的并不能使我们满意。比如某个java应用较大时,频繁产生GC,就会非常影响我们应用的响应速度。这时候就需要我们根据自身需要,进行相应的调整。那么如何调整呢?这就需要我们对虚拟机的垃圾回收机制有所了解了。
找到将要回收的对象
如何找到要回收的对象呢?这里主要有两个算法:
引用计数法
算法大概思路就是给对象中添加一个引用计数器,每当一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器值为0的对象就是不可能再被使用的。
但它的问题在于:很难解决对象之间相互引用的问题。比如对象A引用对象B,同时对象B又引用了对象A,但没有其他对象引用这两个对象,也就是说A和B这个整体是孤立的对象。按理说他们应该是被回收的,但是他们的计数器值并不为0,所以也就不能被回收了。
可达性分析算法
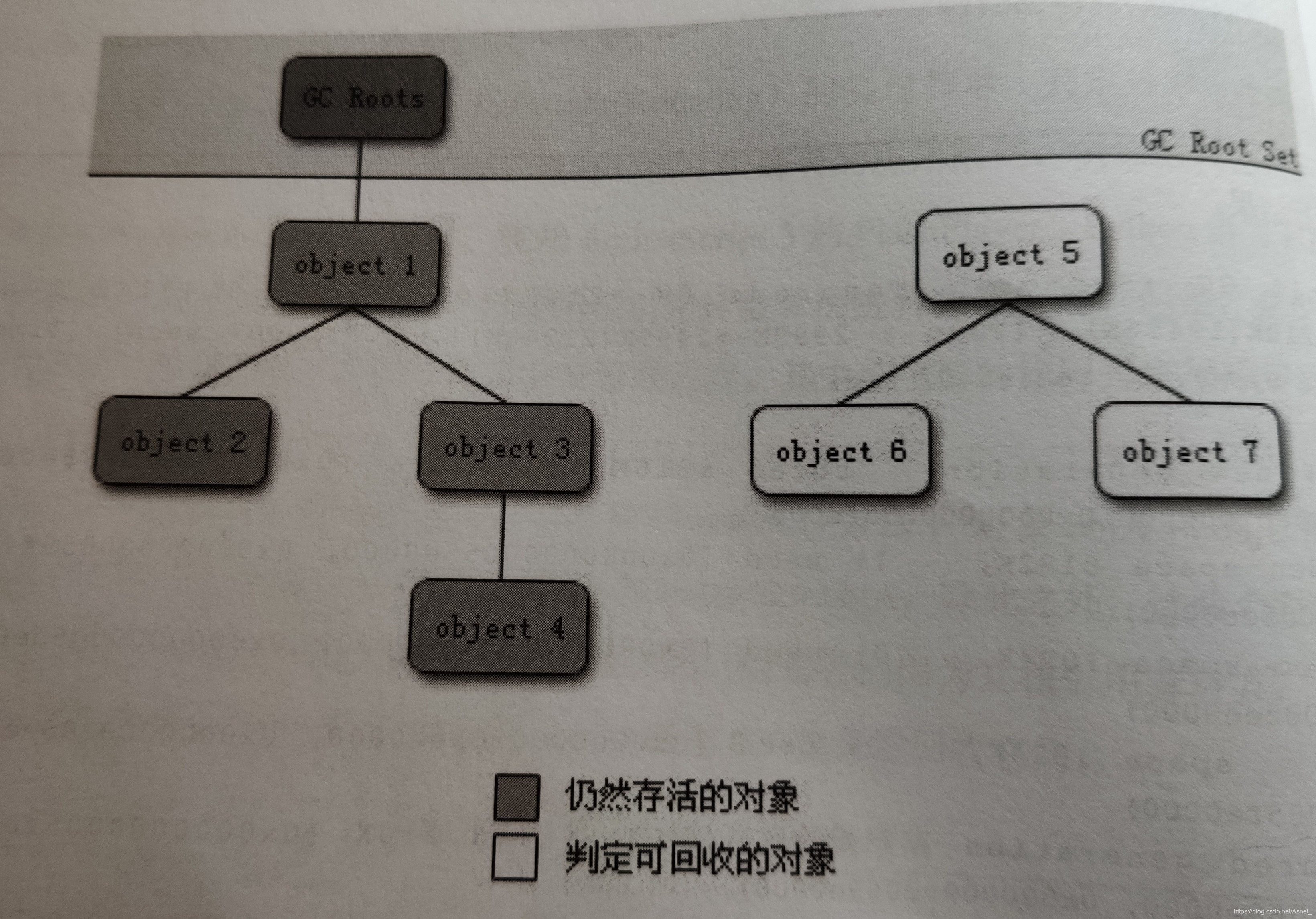
该算法主要思路就是通过一系列的称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走的路径称为引用链(Refererce Chain),当一个对象到GC Roots没有任何引用链相连时,则证明此对象时不可用的。下图为例,即使对象5和对象6、7相连,但它到GC Roots是不可达的,所以对象5、6、7也是要被回收的。这里就解决了前面引用计数法所存在的那个问题。所以该算法目前也是大多数商用程序语言的主流实现。
垃圾收集算法
垃圾收集算法主要有以下四种,不过基本上后面都是前面的改进或者结合。
标记-清除算法
最基础的当数“标记-清除”(Mark-Sweep)算法了。算法分两个阶段:“标记”和“清除”。其中“标记”就是找到可以没有被引用的对象,“清除”就是收集该对象。如下图所示(图片凑合看下吧):

该算法的的缺点很明显:效率问题、空间问题。前者是因为标记和清除两个过程效率都不高。后者是因为会产生大量不连续的内存碎片,从而导致后续需要分配大对象时找不到足够的连续空间而提前触发另一次收集动作。
复制算法
复制(Copying)算法主要时为了解决前面的效率问题。它将可用的容量分为大小相等的两块,每次只使用其中一块。其中一块快用完了,就将存活的对象复制到另外一块上,在把原来那块使用过的空间清理掉。如下图所示(颜色有点混了,格子中间水平分为相等的两部分)。
主要问题:浪费了太多内存。
目前多数商业虚拟机都采用该算法来回收新生代。但并不是严格按照1:1的比例分割内存,而是将它分为一块较大的Eden空间和两块较小的Survivor空间。一块Eden和一块Survivor比例大概为8:1 。每次使用Eden和一块Survivor空间,回收时将所有存活的对象复制到另外一块未使用的Survivor空间上。

标记-整理算法
标记-整理(Mark-Compact)算法,主要适用于对象存活率较高的情况,而前面的复制算法适用于存活率较低的情况。算法大概思路就是先标记要回收的对象,然后清除掉掉这些对象,最后将存活的对象复制整理到一起。也就是在前面标记-清除算法的基础上多了整理的步骤。

分代收集算法
分代收集(Generational Collection)算法主要是将内存划分为新生代和老年代,不同块采用不同的算法。新生代对象存活率较低,就采用复制算法;老年代对象存活率较高,就采用标记-整理算法。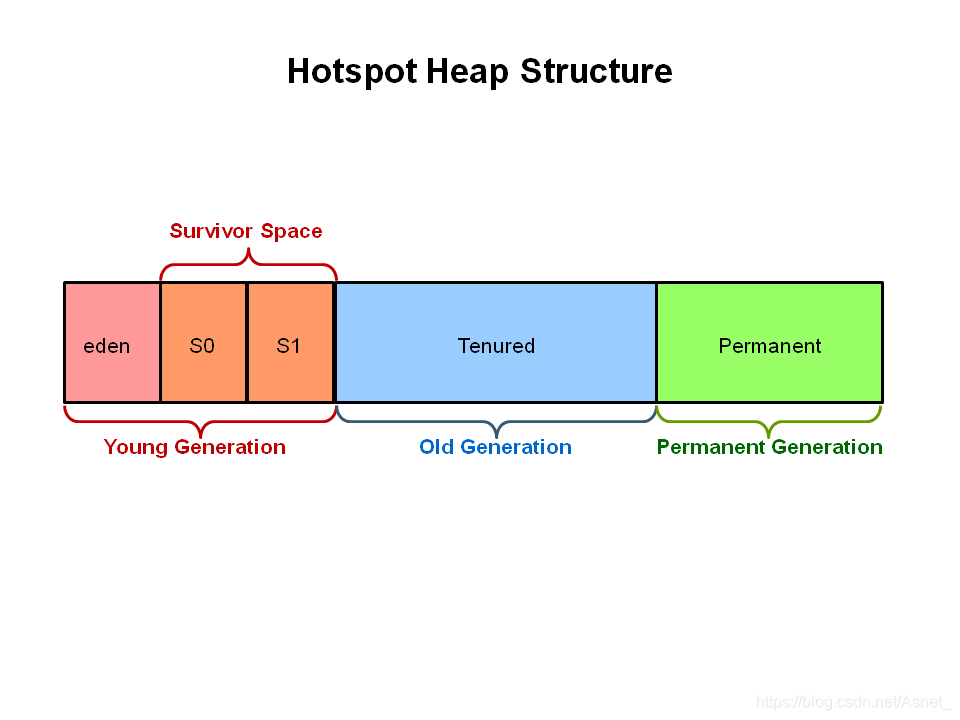
垃圾收集器
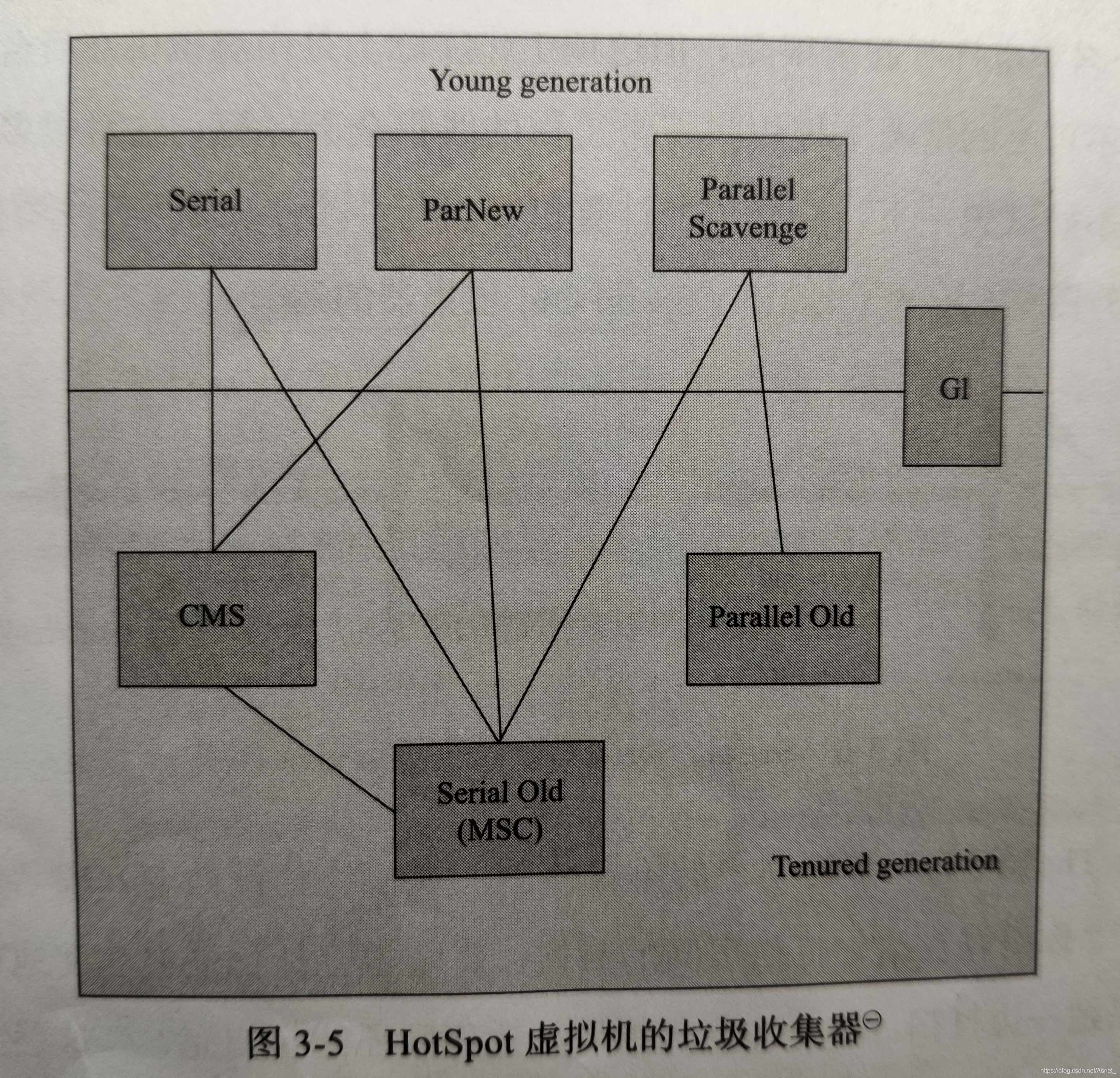
垃圾收集器就相当于前面介绍的那些算法的具体实现了。
新生代收集器使用的收集器:Serial、PraNew、Parallel Scavenge
老年代收集器使用的收集器:Serial Old、Parallel Old、CMS
Serial收集器(复制算法)
新生代单线程收集器,标记和清理都是单线程,优点是简单高效。
Serial Old收集器(标记-整理算法)
老年代单线程收集器,Serial收集器的老年代版本。
ParNew收集器(停止-复制算法)
新生代收集器,可以认为是Serial收集器的多线程版本,在多核CPU环境下有着比Serial更好的表现。
Parallel Scavenge收集器(停止-复制算法)
并行收集器,追求高吞吐量,高效利用CPU。吞吐量一般为99%, 吞吐量= 用户线程时间/(用户线程时间+GC线程时间)。适合后台应用等对交互相应要求不高的场景。
Parallel Old收集器(停止-复制算法)
Parallel Scavenge收集器的老年代版本,并行收集器,吞吐量优先
CMS(Concurrent Mark Sweep)收集器(标记-清理算法)
高并发、低停顿,追求最短GC回收停顿时间,cpu占用比较高,响应时间快,停顿时间短,多核cpu 追求高响应时间的选择
引用:
《深入理解Java虚拟机》 第二版 周志明