因为想巩固下mapreduce,就在网上找了个练习题做。
涉及到的知识点,自定义序列化类,排序输出,分区输出,分组。
数据及字段说明:
computer,huangxiaoming,85,86,41,75,93,42,85
computer,xuzheng,54,52,86,91,42
computer,huangbo,85,42,96,38
english,zhaobenshan,54,52,86,91,42,85,75
english,liuyifei,85,41,75,21,85,96,14
algorithm,liuyifei,75,85,62,48,54,96,15
computer,huangjiaju,85,75,86,85,85
english,liuyifei,76,95,86,74,68,74,48
english,huangdatou,48,58,67,86,15,33,85
algorithm,huanglei,76,95,86,74,68,74,48
algorithm,huangjiaju,85,75,86,85,85,74,86
computer,huangdatou,48,58,67,86,15,33,85
english,zhouqi,85,86,41,75,93,42,85,75,55,47,22
english,huangbo,85,42,96,38,55,47,22
algorithm,liutao,85,75,85,99,66
computer,huangzitao,85,86,41,75,93,42,85
math,wangbaoqiang,85,86,41,75,93,42,85
computer,liujialing,85,41,75,21,85,96,14,74,86
computer,liuyifei,75,85,62,48,54,96,15
computer,liutao,85,75,85,99,66,88,75,91
computer,huanglei,76,95,86,74,68,74,48
english,liujialing,75,85,62,48,54,96,15
math,huanglei,76,95,86,74,68,74,48
math,huangjiaju,85,75,86,85,85,74,86
math,liutao,48,58,67,86,15,33,85
english,huanglei,85,75,85,99,66,88,75,91
math,xuzheng,54,52,86,91,42,85,75
math,huangxiaoming,85,75,85,99,66,88,75,91
math,liujialing,85,86,41,75,93,42,85,75
english,huangxiaoming,85,86,41,75,93,42,85
algorithm,huangdatou,48,58,67,86,15,33,85
algorithm,huangzitao,85,86,41,75,93,42,85,75
数据解释
数据字段个数不固定:
第一个是课程名称,总共四个课程,computer,math,english,algorithm,
第二个是学生姓名,后面是每次考试的分数,但是每个学生在某门课程中的考试次数不固定。
题目一:统计每门课程的参考人数和课程平均分
package com.startbigdata.studentPractise;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/*
统计每门课程的参考人数和课程平均分
*/
public class AvgCourse {
static class MapDrv extends Mapper<LongWritable, Text,Text, Text>{
private final static Text outputValue = new Text();
private Text outputKey = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将每行的数据分割成数组
String[] line = value.toString().split(",");
//先求取每行数据后面分数的和
int sum = 0;
for (int i = 2;i<line.length;i++){
sum+=Integer.parseInt(line[i]);
}
//将结果以(课程,<分数和每个人的考试次数)的形式存储,
// 不要用(<课程数,分数和>,每个人的考试次数)进行存储,否则相同的课程不会被分到一组
this.outputKey.set(line[0]);
outputValue.set(sum+"-"+(line.length-2));
context.write(outputKey,outputValue);
}
}
static class ReduceDrv extends Reducer<Text, Text,Text,Text>{
private Text outputValue = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//用于存储该课程出现的次数,即相当于求取了学生的人数
int personSum = 0;
//用于存储分数和
int courseSum=0;
//用于存储考试的总次数
int testNum = 0;
//求取人数和,分数和
for (Text value:values) {
//将每个value进行分割得到分数和,考试次数和
String[] str = value.toString().split("-");
personSum++;
courseSum+=Integer.parseInt(str[0]);
testNum+=Integer.parseInt(str[1]);
}
//用于存储平均分
int avg = courseSum / testNum;
this.outputValue.set(personSum+" "+avg);
context.write(key,outputValue);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,AvgCourse.class.getName());
job.setJarByClass(AvgCourse.class);
job.setMapperClass(MapDrv.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(ReduceDrv.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
FileSystem fs = FileSystem.get(conf);
if (fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
job.waitForCompletion(true);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
执行命令:
hadoop jar /opt/modules/hadoop-2.7.3/jars/hadoopapi.jar com.startbigdata.AvgCourse /tmp1/student.txt /tmp1/out6
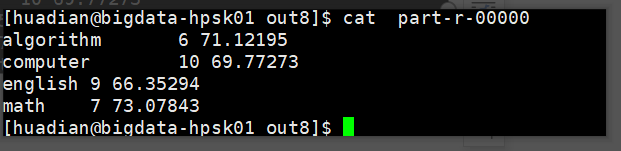
题目二:统计每门课程参考学生的平均分,并且按课程存入不同的结果文件,要求一门课程一个结果文件,并且按平均分从高到低排序,分数保留一位小数。
排序快速记忆:当前对象与后一个对象进行比较,如果比较结果为1进行交换,其他不进行交换。
当后一个对象比当前对象大,返回结果值为1时,前后交换,说明是倒序排列。
当后一个对象比当前对象小,返回结果值为1时,前后交换,说明是升序排列。
自定义序列化类:
package com.startbigdata.studentPractise;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 自定义序列化类型
*/
public class StudentBean implements WritableComparable<StudentBean> {//记得是实现WritableComparable接口
private String course;//课程名
private String name;//学生姓名
private Float avgScore;//平均成绩
//自定义序列化需要无参的构造函数
public StudentBean() {
}
public StudentBean(String course, String name, Float avgScore) {
this.course = course;
this.name = name;
this.avgScore = avgScore;
}
public String getCourse() {
return course;
}
public void setCourse(String course) {
this.course = course;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Float getAvgScore() {
return avgScore;
}
public void setAvgScore(Float avgScore) {
this.avgScore = avgScore;
}
//序列化
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(course);//注意dataOutput.writeXX类型
dataOutput.writeUTF(name);
dataOutput.writeFloat(avgScore);
}
//反序列化
public void readFields(DataInput dataInput) throws IOException {
//反序列化的顺序要和序列化顺序相同
course = dataInput.readUTF();
name = dataInput.readUTF();
avgScore=dataInput.readFloat();
}
//设定排序方法是倒叙还是顺序
public int compareTo(StudentBean o) {
return o.avgScore > this.avgScore?1:-1;
}
// 通过toString方法自定义输出类型
@Override
public String toString() {
return course+" "+name+" "+avgScore;
}
}
自定义分区:
package com.startbigdata.studentPractise;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* Mapreduce中会将map输出的kv对,按照相同key分组,然后分发给不同的reducetask
*默认的分发规则为:根据key的hashcode%reducetask数来分发
*所以:如果要按照我们自己的需求进行分组,则需要改写数据分发(分组)组件Partitioner
*自定义一个CouresePartition继承抽象类:Partitioner
*然后在job对象中,设置自定义partitioner: job.setPartitionerClass(CustomPartitioner.class)
*
*/
//自定义分区规则,这里不清楚自定义分区的执行过程
public class CouresePartition extends Partitioner<StudentBean, NullWritable> {
public int getPartition(StudentBean key, NullWritable nullWritable, int i) {
/* algorithm
computer
english
math */
if ("algorithm".equals(key.getCourse())){
return 0;
}
else if ("computer".equals(key.getCourse())){
return 1;
}
else if ("english".equals(key.getCourse())){
return 2;
}
else
return 3;
}
}
mapreduce程序:
package com.startbigdata.studentPractise;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
//统计每门课程参考学生的平均分,并且按课程存入不同的结果文件,
// 要求一门课程一个结果文件,并且按平均分从高到低排序,分数保留一位小数。
public class StudentAvgCourse {
static class MapDrvAvg extends Mapper<LongWritable, Text, StudentBean, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] ling = value.toString().split(",");
//求每个学生的平均分
int sum = 0;//存储总分数
for (int i = 2;i<ling.length;i++){
sum+=Long.parseLong(ling[i]);
}
StudentBean studentBean = new StudentBean();
studentBean.setName(ling[1]);
studentBean.setCourse(ling[0]);
studentBean.setAvgScore(sum*1.0f/(ling.length-2));
context.write(studentBean,NullWritable.get());
}
}
static class ReduceDrvAvg extends Reducer<StudentBean, NullWritable,StudentBean,NullWritable>{
@Override
protected void reduce(StudentBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//因为自定义了分区组件,自定义类型有排序规则,所以这里直接输出就可以了
for (NullWritable nullWritable : values) {
context.write(key, nullWritable.get());
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,StudentAvgCourse.class.getName());
job.setJarByClass(StudentAvgCourse.class);
//设置分区类
job.setPartitionerClass(CouresePartition.class);
//设置reduce 任务数
job.setNumReduceTasks(4);
job.setMapperClass(MapDrvAvg.class);
job.setMapOutputKeyClass(StudentBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(ReduceDrvAvg.class);
job.setOutputKeyClass(StudentBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
FileSystem fs = FileSystem.get(conf);
if (fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
boolean wait = job.waitForCompletion(true);
System.exit(wait?0:1);
}
}

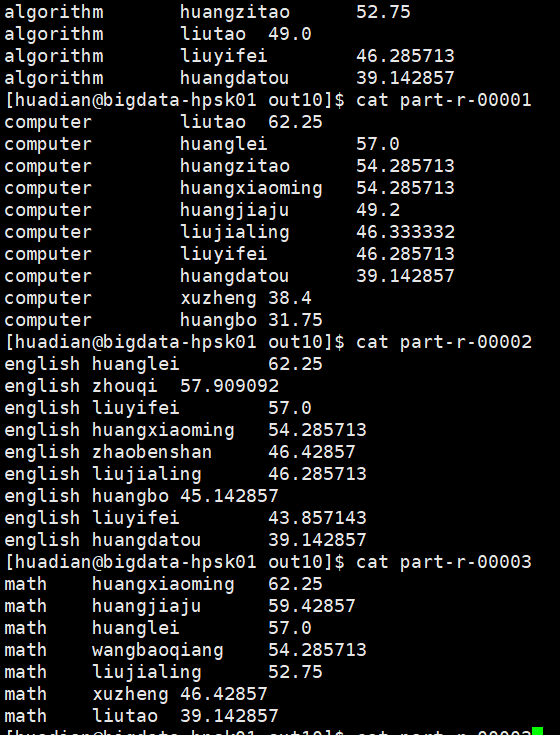
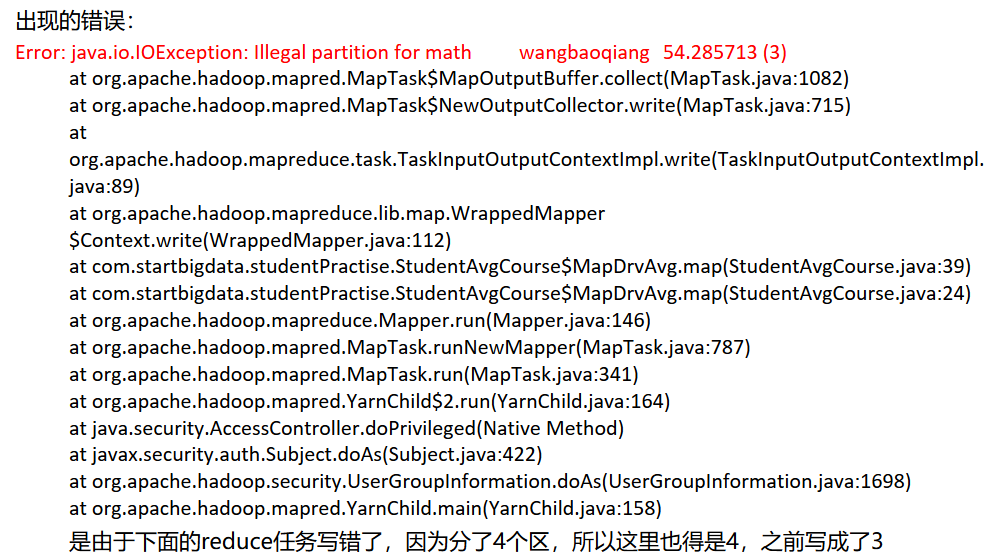
上面图片后面算出的数据是错误的,因为之前程序有个逻辑错误,已经修正了,但结果图片未保存。不过输出的格式如上图。

题目三:求出每门课程参考学生成绩最高的学生的信息:课程,姓名和平均分
自定义序列化类:
package com.startbigdata.studentPractise;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class StudentMaxBean implements WritableComparable<StudentMaxBean> {
private String course;
private String name;
private Float avgScore;
private Float maxScore;
public StudentMaxBean() {
}
public StudentMaxBean(String course, String name, Float avgScore, Float maxScore) {
this.course = course;
this.name = name;
this.avgScore = avgScore;
this.maxScore = maxScore;
}
public String getCourse() {
return course;
}
public void setCourse(String course) {
this.course = course;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Float getAvgScore() {
return avgScore;
}
public void setAvgScore(Float avgScore) {
this.avgScore = avgScore;
}
public Float getMaxScore() {
return maxScore;
}
public void setMaxScore(Float maxScore) {
this.maxScore = maxScore;
}
public int compareTo(StudentMaxBean o) {
//首先通过课程进行排序,课程相同的通过成绩进行排序
//值得一提的是,使用自定义分组组件指定的分组字段,一定要在comparaTo方法中使用字段得而前面
int index = o.course.compareTo(this.course);
if (index==0){
float flag = o.maxScore-this.maxScore;
return flag>0.0f?1:-1;
}
else return index>0.0f?1:-1;
}
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(course);//注意dataOutput.writeXX类型
dataOutput.writeUTF(name);
dataOutput.writeFloat(avgScore);
dataOutput.writeFloat(maxScore);
}
//反序列化
public void readFields(DataInput dataInput) throws IOException {
//反序列化的顺序要和序列化顺序相同
course = dataInput.readUTF();
name = dataInput.readUTF();
avgScore=dataInput.readFloat();
maxScore=dataInput.readFloat();
}
@Override
public String toString() {
return course+" "+name+" "+avgScore+" "+maxScore;
}
}
自定义分组类:
package com.startbigdata.studentPractise;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
//自定义分组,
//主要就是对于分组进行排序,分组只按照组建键中的一个值进行分组
public class CourseGroup extends WritableComparator {
protected CourseGroup() {
super(StudentMaxBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
StudentMaxBean astudentMaxBean = (StudentMaxBean)a;
StudentMaxBean bstudentMaxBean =(StudentMaxBean)b;
//如果是整型直接astudentMaxBean.getCourse()-bstudentMaxBean.getCourse()
return astudentMaxBean.getCourse().compareTo(bstudentMaxBean.getCourse());
}
}
mapreduce程序:
package com.startbigdata.studentPractise;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
//求出每门课程参考学生成绩最高的学生的信息:课程,姓名和平均分
public class StudentTop {
static class MapDrv extends Mapper<LongWritable, Text,StudentMaxBean,NullWritable >{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(",");
//求每个同学每门课程最高分,默认第一次考试为最高分
Float maxScore = Float.parseFloat(line[2]);
//存储总分
Float sumScore = 0.0f;
for (int i=2;i<line.length;i++){
//求总分
sumScore+=Float.parseFloat(line[i]);
//如果后次比前次分数高就将maxScore替换,否则不变
if (maxScore<Float.parseFloat(line[i])) maxScore=Float.parseFloat(line[i]);
}
//平均分
Float avgScore = sumScore/(line.length-2)*1.0f;
StudentMaxBean studentMaxBean = new StudentMaxBean(line[0],line[1],avgScore,maxScore);
//输出<课程名,学生信息>
System.out.println("map------------------------"+studentMaxBean.toString());
context.write(studentMaxBean,NullWritable.get());
}
}
static class ReduceDrv extends Reducer<StudentMaxBean, NullWritable,StudentBean,NullWritable>{
protected void reduce(StudentMaxBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
// StudentBean s = new StudentBean(key.getCourse(),key.getName(),key.getAvgScore());不要在这里就赋值,这样会导致数据的每个值都是第一个进来的值
StudentBean s = new StudentBean();//存放同组内分数最高的同学信息
context.write(s,NullWritable.get());
/*
求topN如下:
int i = 0;
for(NullWritable nullWritable:values){
if (i>=2) break;
s.setCourse(key.getCourse());
s.setName(key.getName());
s.setAvgScore(key.getAvgScore());
context.write(s,nullWritable.get());
i++;
}
*/
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,StudentTop.class.getName());
job.setJarByClass(StudentTop.class);
//设置分组
job.setGroupingComparatorClass(CourseGroup.class);
job.setMapperClass(MapDrv.class);
// job.setMapOutputKeyClass(Text.class);
//job.setMapOutputValueClass(StudentMaxBean.class);
job.setMapOutputKeyClass(StudentMaxBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(ReduceDrv.class);
job.setOutputKeyClass(StudentBean.class);
job.setOutputValueClass(NullWritable.class);
// FileInputFormat.addInputPath(job,new Path(args[0]));
// FileOutputFormat.setOutputPath(job,new Path(args[1]));
FileInputFormat.addInputPath(job,new Path("E:/tmp/student.txt"));
FileOutputFormat.setOutputPath(job,new Path("E:/tmp/out"));
FileSystem fs = FileSystem.get(conf);
//if (fs.exists(new Path(args[1]))){
//fs.delete(new Path(args[1]),true);
// }
boolean wait = job.waitForCompletion(true);
System.exit(wait?0:1);
}
}
上面第三题我是在windows环境下做的,因为程序之前运行的结果不对,我linux没有编译器,就在windows环境下编译的,所以和前两题有点不太一样。
