一、什么是分布式存储
传统存储系统:客户端读写数据时需要一个controller或gateway,这种集中式组件通信架构使其天然具有单点故障,性能瓶颈、扩展性差等特点。
分布式存储:Ceph允许Client(客户端)直接访问OSD进程(硬盘),消除集中式架构,不再需要查询中心式元数据表,将计算压力下发,提升整体存储性能。
二、ONEStor多副本存储及故障域隔离方案
1、同一集群内。可根据供电系统,分布位置等因素的不同,把服务器划分至不同的故障域中
2、数据写入时,将不同的副本分布在不同的故障域中。
3、即使其中一个故障域内的设备集体故障,也不会影响数据的正常运行。
三、ONEStor实现数据强一致性
数据一致性:分布式系统通过副本控制协议,使得从系统外部读取系统内部各个副本的数据在一定的约束条件下相同,称之为副本一致性。
四、ONEStor高可用架构设计
优化架构保障应用的可靠性:基于应用的HA特性。这种方案适用性很强,应用侧不需要做任何配置,就可以实现ONESotr存储集群的高可靠性和负载分担。
多副本保障数据的可靠性:可提供N+N,N+1多副本的存储机制保障数据可靠性
数据自动重构及均衡保障系统可靠性:当有节点发生故障,ONEStor系统会自动进行数据重构,恢复因故障丢失的副本,保障系统的高可靠性。
五、ONEStor支持SSD读/写加速
读加速:为提升读性能,热数据保存在SSD组成的Flashcache中,采用around模式,仅读操作时经过该cache
写加速:为提升写性能,写操作时的journal直接写入SSD;当Server有较大Raid卡缓存时,建议将SSD用作读加速
六、ONEStor组网
1、ONEStor业务网络:承载ONEStor MON管理集群、OSD前端心跳报文,与CAS交互数据;重要程度非常高,需独立组网,带宽万兆,建议双链路冗余
2、ONEStor存储内网:承载ONEStor OSD后端心跳,在OSD发生变化时数据重分布等流量,流量大且可能有较高的突发,需独立组网,带宽万兆,建议双链路作冗余
3、CAS存储网络:承载与ONEStor集群数据交互的流量;重要程度非常高,需独立组网,带宽万兆,建议双链路冗余
4、CAS业务网络:承载业务访问数据,需要独立组网,与CAS管理网络、CAS存储内网分离,根据业务情况带宽可为千兆或者万兆,建议双链路冗余
5、CAS管理网络:承载主机及虚拟机软件管理报文(HA、集群心跳等报文)、迁移数据;重要程度非常高,需独立组网,带宽千兆,建议双链路冗余
七、部署
1、独立部署:ONEStor独立部署服务器上。
2、融合部署:先搭建CAS集群,然后在安装ONEStor组件,搭建ONEStor集群,服务器数据盘,被ONEStor独立管理,CPU,内存,系统盘,CAS与ONEStor共用。
八、数据写入过程

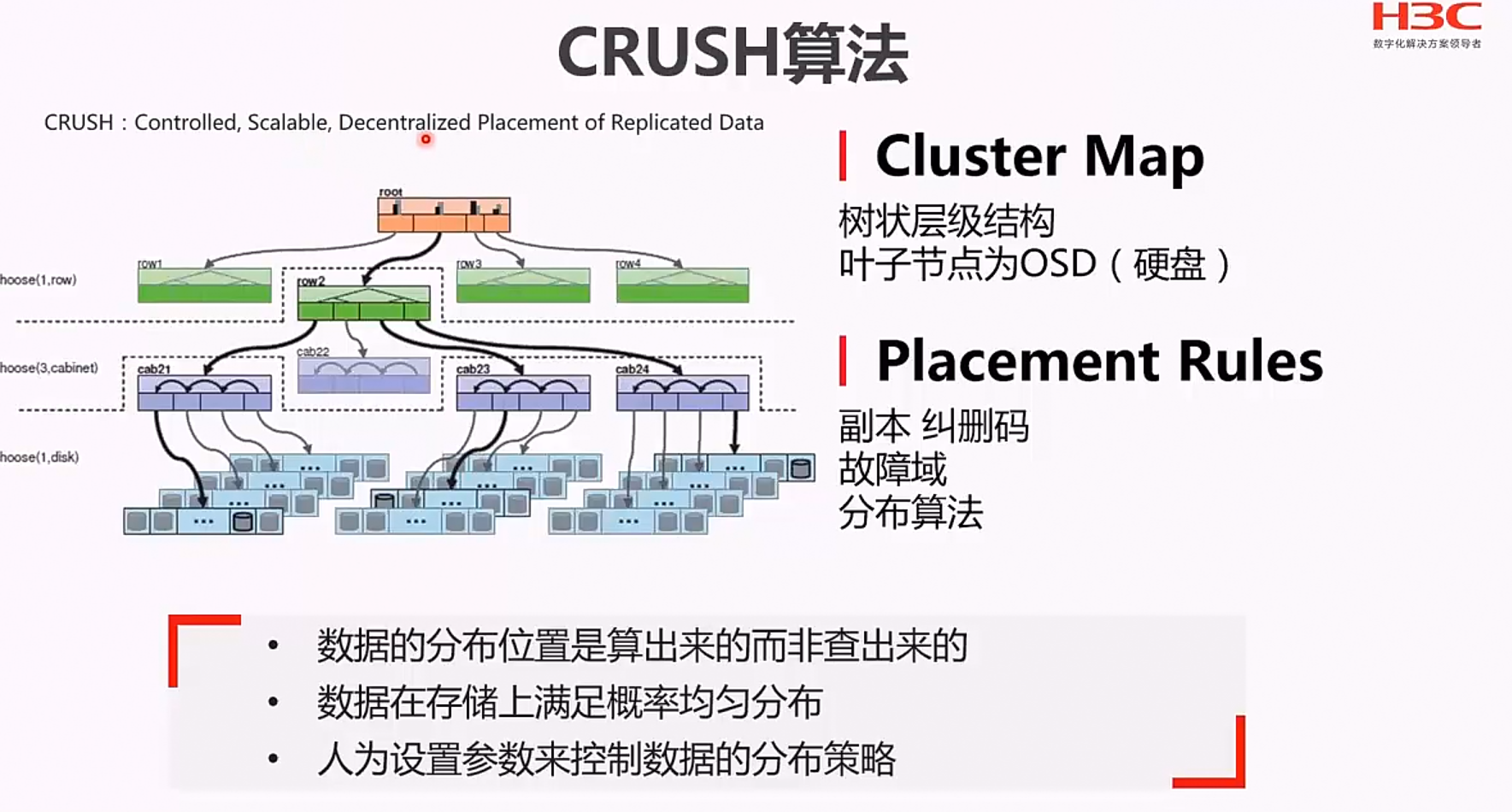
九、CRUSH算法