










课程demo
-
来到杨过曾经生活过的地方,小龙女动情地说:“我也想过过过儿过过的生活。”
-
你也想犯范范玮琪犯过的错吗
-
校长说衣服上除了校徽别别别的
-
这几天天天天气不好
-
我背有点驼,麻麻说“你的背得背背背背佳
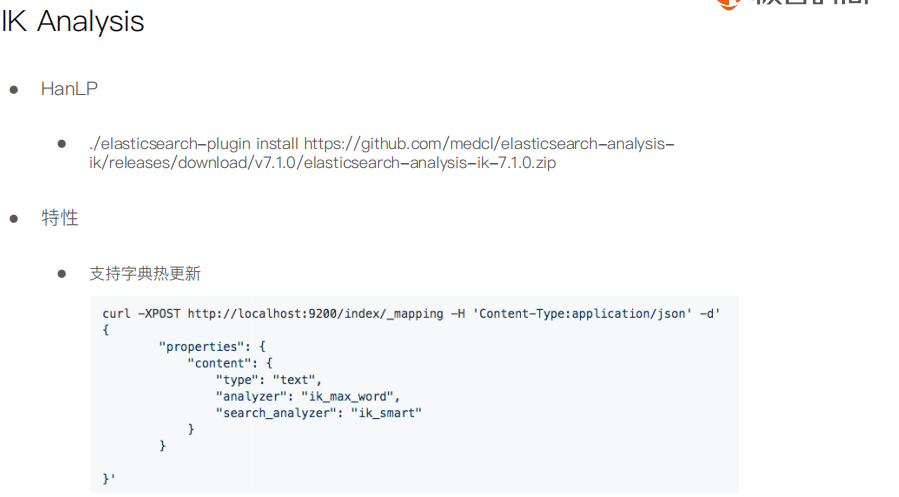
#stop word DELETE my_index PUT /my_index/_doc/1 { "title": "I'm happy for this fox" } PUT /my_index/_doc/2 { "title": "I'm not happy about my fox problem" } POST my_index/_search { "query": { "match": { "title": "not happy fox" } } } #虽然通过使用 english (英语)分析器,使得匹配规则更加宽松,我们也因此提高了召回率,但却降低了精准匹配文档的能力。为了获得两方面的优势,我们可以使用multifields(多字段)对 title 字段建立两次索引: 一次使用 `english`(英语)分析器,另一次使用 `standard`(标准)分析器: DELETE my_index PUT /my_index { "mappings": { "blog": { "properties": { "title": { "type": "string", "analyzer": "english" } } } } } PUT /my_index { "mappings": { "blog": { "properties": { "title": { "type": "string", "fields": { "english": { "type": "string", "analyzer": "english" } } } } } } } PUT /my_index/blog/1 { "title": "I'm happy for this fox" } PUT /my_index/blog/2 { "title": "I'm not happy about my fox problem" } GET /_search { "query": { "multi_match": { "type": "most_fields", "query": "not happy foxes", "fields": [ "title", "title.english" ] } } } #安装插件 ./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.1.0/elasticsearch-analysis-ik-7.1.0.zip #安装插件 bin/elasticsearch install https://github.com/KennFalcon/elasticsearch-analysis-hanlp/releases/download/v7.1.0/elasticsearch-analysis-hanlp-7.1.0.zip #ik_max_word #ik_smart #hanlp: hanlp默认分词 #hanlp_standard: 标准分词 #hanlp_index: 索引分词 #hanlp_nlp: NLP分词 #hanlp_n_short: N-最短路分词 #hanlp_dijkstra: 最短路分词 #hanlp_crf: CRF分词(在hanlp 1.6.6已开始废弃) #hanlp_speed: 极速词典分词 POST _analyze { "analyzer": "hanlp_standard", "text": ["剑桥分析公司多位高管对卧底记者说,他们确保了唐纳德·特朗普在总统大选中获胜"] } #Pinyin PUT /artists/ { "settings" : { "analysis" : { "analyzer" : { "user_name_analyzer" : { "tokenizer" : "whitespace", "filter" : "pinyin_first_letter_and_full_pinyin_filter" } }, "filter" : { "pinyin_first_letter_and_full_pinyin_filter" : { "type" : "pinyin", "keep_first_letter" : true, "keep_full_pinyin" : false, "keep_none_chinese" : true, "keep_original" : false, "limit_first_letter_length" : 16, "lowercase" : true, "trim_whitespace" : true, "keep_none_chinese_in_first_letter" : true } } } } } GET /artists/_analyze { "text": ["刘德华 张学友 郭富城 黎明 四大天王"], "analyzer": "user_name_analyzer" }
相关资源
-
Elasticsearch IK分词插件 https://github.com/medcl/elasticsearch-analysis-ik/releases
-
Elasticsearch hanlp 分词插件 https://github.com/KennFalcon/elasticsearch-analysis-hanlp
一些分词工具,供参考:
- 中科院计算所NLPIR http://ictclas.nlpir.org/nlpir/
- ansj分词器 https://github.com/NLPchina/ansj_seg
- 哈工大的LTP https://github.com/HIT-SCIR/ltp
- 清华大学THULAC https://github.com/thunlp/THULAC
- 斯坦福分词器 https://nlp.stanford.edu/software/segmenter.shtml
- Hanlp分词器 https://github.com/hankcs/HanLP
- 结巴分词 https://github.com/yanyiwu/cppjieba
- KCWS分词器(字嵌入+Bi-LSTM+CRF) https://github.com/koth/kcws
- ZPar https://github.com/frcchang/zpar/releases
- IKAnalyzer https://github.com/wks/ik-analyzer